Spring Data Nedir ve Nasıl Çalışır?
Spring Data, Spring uygulamasının kalıcılık (persistence) katmanını minimum çabayla implement etme imkanı veren bir Spring ekosistem projesidir.


Spring Data, Spring uygulamasının kalıcılık (persistence) katmanını minimum çabayla implement etme imkanı veren bir Spring ekosistem projesidir. Bildiğiniz gibi, bir application framework'ün temel rolü, doğrudan uygulamalara ekleyebileceğiniz kullanıma hazır özellikler sağlamaktır. Framework'ler zamandan tasarruf etmemize ve uygulamaların tasarımının daha kolay anlaşılmasını sağlamamıza yardımcı olur.
Bu bölümde; interface'leri tanımlayarak uygulamanın repository'lerini oluşturmayı, framework'ün bu interface'ler için implementasyon sağlamasına izin vermeyi, uygulamanızın repository'i kendiniz implement etmeden ve minimum çabayla bir veritabanıyla çalışmasını tam anlamıyla etkinleştirmeyi öğreneceksiniz.
Bölüme, Spring Data'nın nasıl çalıştığını tartışarak başlayacağız ve Spring Data'nın Spring uygulamalarına nasıl entegre olduğunu göreceksiniz. Daha sonra, bir uygulamanın kalıcılık katmanını implemente etmek için Spring Data JDBC kullanmayı öğreneceğiniz pratik bir örnekle devam edeceğiz.
1. Spring Data Nedir?
Spring Data, kullandığımız persistence teknolojisine göre implementasyonlar sağlayarak persistence katmanının yazılmasını basitleştiren bir Spring ekosistem projesidir. Bu şekilde, Spring uygulamamızın repository'lerini tanımlamak için yalnızca birkaç satır kod yazmamız yeterli olacak. Şekil 1, Spring Data'nın yerinin bir uygulamanın perspektifinden görsel bir temsilini sunar.
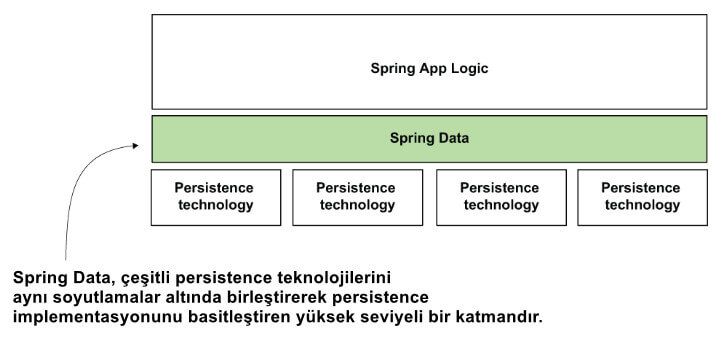
Java ekosistemi çok sayıda çeşitli persistence teknolojisi sunar. Her teknolojiyi belirli bir şekilde kullanırsınız. Her teknolojinin kendi soyutlamaları ve sınıf tasarımı vardır. Spring Data, çoklu persistence teknolojilerinin kullanımını basitleştirmek için tüm bu persistence teknolojileri üzerinde ortak bir abstraction katmanı sunar.
Spring Data'nın bir Spring uygulamasında nereye uyduğunu görelim. Bir uygulamada, kalıcı verilerle çalışmak için kullanabileceğiniz çeşitli teknolojilere sahip olursunuz. Spring Data Source ve JDBC Kullanımı başlıklı yazımızda, bir driver manager aracılığıyla ilişkisel DBMS'ye doğrudan bağlanan JDBC'i kullanmıştık. Ancak JDBC, ilişkisel bir veritabanına bağlanmak için kullanabileceğiniz tek yaklaşım değildir. Data persistence'yi uygulamanın bir başka yaygın yolu da Hibernate gibi bir ORM framework kullanmaktır. Ve ilişkisel veritabanları, persistence data teknolojilerinin tek türü değildir. Bir uygulama, verileri kalıcı hale getirmek için çeşitli NoSQL teknolojilerinden birini kullanabilir.
Şekil 2, Spring'in kalıcı verilere yönelik bazı alternatiflerini gösterir. Her alternatifin, uygulamanın repository'lerini uygulamak için kendi yolu vardır. Bazen, uygulamanın kalıcılık katmanını tek bir teknoloji için (JDBC gibi) implemente etmekte kullanacağınız birden fazla seçeneğiniz bile olabilir. Örneğin, JDBC ile, önceki yazımızda öğrendiğiniz gibi JdbcTemplate'i kullanabilirsiniz, ancak doğrudan JDK interface'leriyle de (Statement, ReadyStatement, ResultSet vb.) çalışabilirsiniz. Uygulamanın persistence özelliklerini implement etmek için bu kadar çok yola sahip olmak aynı zamanda karmaşıklığı artırır.

İlişkisel bir DBMS'ye bağlanmak için JDBC'yi kullanmak, bir uygulamanın kalıcılık katmanını implemente etmek için tek seçenek değildir. Gerçek dünya senaryolarında, diğer seçenekleri de kullanacaksınız ve verileri kalıcı hale getirirken kullandığınız her teknolojinin kendi library'si ve öğrenmeniz gereken API kümesi olduğunu göreceksiniz. Tabi bu çeşitlilik beraberinde çok fazla karmaşıklık da getirir.
Hibernate gibi ORM framework'ünü dahil edersek diyagram daha karmaşık hale gelir. Şekil 3, Hibernate'in sahnedeki yerini gösterir. Uygulamanız JDBC'yi çeşitli şekillerde doğrudan kullanabilir, ancak JDBC üzerinden uygulanan bir framework'e de güvenebilir.
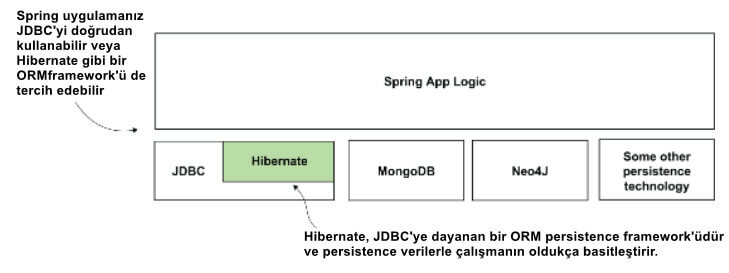
Bazen uygulamalar, Hibernate gibi JDBC'nin üzerine inşa edilmiş framework'ler kullanır. Seçimlerdeki çeşitlilik, persistence katmanının implementasyonunu karmaşık hale getirir. Ve bizde uygulamalarımızdan bu karmaşıklığı ortadan kaldırmak istiyoruz. Burada öğreneceğiniz gibi Spring Data bunu yapmamıza yardımcı olur.
Endişelenmeyin! Spring Data'yı öğrenmek için bunların hepsini bir kerede öğrenmenize gerek yok, hepsini bilmenize de gerek yok. Şanslısınız ki, Spring Data'yı öğrenmeye başlamanız için önceki iki yazımızda anlattıklarımızı öğrenmeniz yeterli olacaktır. İsterseniz öncelikle bu iki yazımızı okuduktan sonra buradan devam edebilirsiniz:
 Ismet BALAT
Ismet BALAT Ismet BALAT
Ismet BALAT
Sizi tüm bunlardan haberdar etmemin sebebi Spring Data'nın neden bu kadar değerli olduğunu göstermektir. Kendinize şu soruyu sormuş olabilirsiniz: "Her biri için farklı yaklaşımlar bilmek yerine tüm bu teknolojilerin kalıcılığını implement etmenin bir yolu var mı?" Cevap evet ve Spring Data bu hedefe ulaşmamıza yardımcı oluyor.
Spring Data, aşağıdakileri yaparak persistence katmanının implementasyonunu basitleştirir:
- Çeşitli persistence teknolojileri için ortak bir soyutlama (abstraction) seti (interfaceler) sağlamak. Bu şekilde, farklı teknolojilerde kalıcılığı implemente etmek için benzer bir yaklaşım kullanırsınız.
- Kullanıcının, yalnızca Spring Data'nın sağladığı soyutlamaları kullanarak kalıcılık işlemlerini implemente etmesine izin vermek. Bu şekilde daha az kod yazarsınız ve uygulamanın özelliklerini daha hızlı uygularsınız. Daha az yazılı kodla, uygulamanın anlaşılması ve bakımı daha kolay hale gelir.
Şekil 4, Spring Data'nın bir Spring uygulamasındaki konumunu gösterir. Gözlemlediğiniz gibi, Spring Data, kalıcılığı implemente etmenin çeşitli yolları üzerinde üst düzey bir katmandır. Dolayısıyla, uygulamanızın kalıcılığını implemente etmek için seçiminiz hangisi olursa olsun, Spring Data kullanıyorsanız kalıcılık işlemlerini benzer şekilde yazacaksınız.
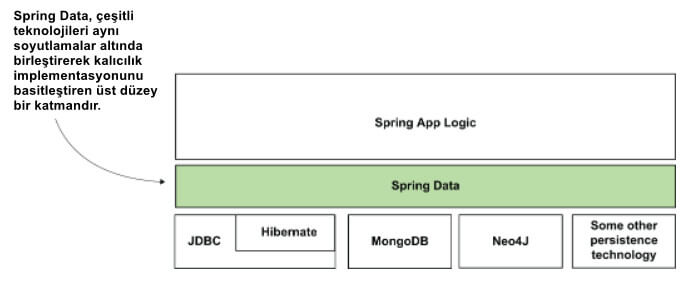
Spring Data, çeşitli teknolojiler için ortak bir soyutlama seti sunarak kalıcılık katmanı implementasyonunu basitleştirir.
2. Spring Data Nasıl Çalışır?
Bu bölümde, Spring Data'nın nasıl çalıştığını ve Spring uygulamanızın kalıcılık katmanını implement etmek için nasıl kullanacağımızı tartışacağız. Geliştiriciler "Spring Data" terimini kullandıklarında, genel olarak bu projenin bir kalıcılık teknolojisine veya diğerine bağlanmak için Spring uygulamanıza sağladığı tüm yeteneklere atıfta bulunurlar. Bir uygulamada genellikle belirli bir teknoloji kullanırsınız: JDBC, Hibernate, MongoDB veya başka bir teknoloji.
Spring Data projesi, bir teknoloji veya başka bir teknoloji için farklı modüller sunar. Bu modüller birbirinden bağımsızdır ve bunları farklı Maven bağımlılıklarını kullanarak projenize ekleyebilirsiniz. Bu nedenle, bir uygulamayı implement ettiğinizde, Spring Data bağımlılığını kullanmazsınız. Bir Spring Data bağımlılığı diye bir şey yoktur. Spring Data projesi, desteklediği her persistence biçimi için bir Maven bağımlılığı sağlar. Örneğin, doğrudan JDBC aracılığıyla DBMS'ye bağlanmak için Spring Data JDBC modülünü kullanabilir veya bir MongoDB veritabanına bağlanmak için Spring Data Mongo modülünü kullanabilirsiniz. Şekil 5, Spring Verilerinin JDBC kullanılarak nasıl göründüğünü göstermektedir.
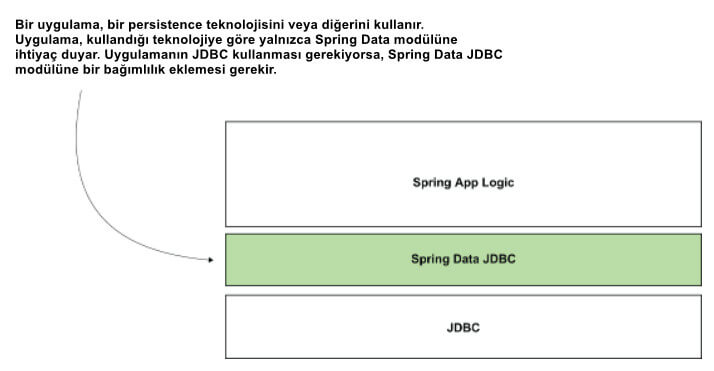
Uygulama JDBC kullanıyorsa, yalnızca Spring Data projesinin JDBC aracılığıyla kalıcılığı yöneten kısmına ihtiyaç duyar. Kalıcılığı JDBC aracılığıyla yöneten Spring Data modülüne Spring Data JDBC adı verilir. Bu Spring Data modülünü kendi bağımlılığı ile uygulamanıza eklersiniz.
Spring Data modüllerinin tam listesini Spring Data'nın resmi sayfasında bulabilirsiniz: https://spring.io/projects/spring-data.
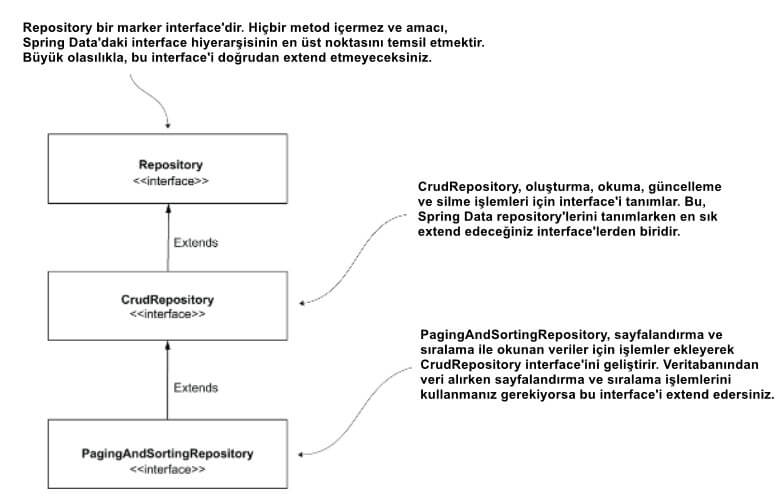
Uygulamanız hangi kalıcılık teknolojisini kullanırsa kullansın Spring Data, uygulamanın kalıcılık özelliklerini tanımlamak için extend edebileceğiniz ortak bir interface seti sağlar. Şekil 6 aşağıdaki interface'leri sunar:
- Repository en soyut interface'dir. Bu interface'i extend ederseniz uygulamanız yazdığınız interface'i belirli bir Spring Data repository'si olarak tanır. Yine de, önceden tanımlanmış herhangi bir işlemi (yeni bir kayıt eklemek, tüm kayıtları almak veya primary anahtarıyla bir kayıt almak gibi) yeniden tanımlamazsınız. Repository interface'i herhangi bir metod bildirmez (bu bir marker interface'dir).
- CrudRepository, bazı persistence yetenekleri de sağlayan en basit Spring Data interface'sidir. Bu interface'i uygulamanızın persistence özelliklerini tanımlayacak şekilde extend ederseniz, kayıt oluşturmak, almak, güncellemek ve silmek için en basit işlemleri elde edersiniz.
- PagingAndSortingRepository, CrudRepository'yi extend eder ve kayıtları sıralama veya belirli bir sayıdan (sayfalar) oluşan parçalar halinde almayla ilgili işlemleri ekler.
Spring Data kullanarak uygulamanızın repository'lerini implement etmek için belirli interface'leri extend edersiniz. Spring Data interface'lerini temsil eden ana interface'ler Repository, CrudRepository ve PagingAndSortingRepository'dir. Uygulamanızın persistence özelliklerini implement etmek için bu interface'lerden birini extend edebilirsiniz.
NOT: Daha önce tartıştığımız @Repository anotasyonunu Spring Data Repository interface'i ile karıştırmayın. @Repository anotasyonu, Spring'e anotated edildiği sınıfın bir instance'ını application context'e eklemesi talimatını vermek için sınıflarla birlikte kullandığınız stereotype bir anotasyondur. Bu bölümde tartıştığımız bu Repository interface'i, Spring Data'ya özeldir ve öğreneceğiniz gibi, Spring Data repository tanımlamak için onu veya ondan extend edilen başka bir interface'i extend edersiniz.
Belki de Spring Data'nın neden birbirini extend eden birden fazla interface sağladığını merak ediyorsunuzdur. Neden tüm işlemleri içeren tek bir interface yeterli değil? Spring Data, tüm işlemlerle size tek bir "şişman" interface sağlamak yerine birbirini extend eden birden fazla interface implement ederek, uygulamanıza yalnızca ihtiyaç duyduğu işlemleri gerçekleştirme olanağı verir. Bu yaklaşım, interface segregation adı verilen ve bilinen bir ilkedir. Örneğin, uygulamanızın yalnızca CRUD işlemlerini kullanması gerekiyorsa, CrudRepository interface'ini extend edersiniz Uygulamanız, kayıtları sıralama ve sayfalama ile ilgili işlemleri almaz, bu da uygulamanızı basitleştirir (şekil 7).
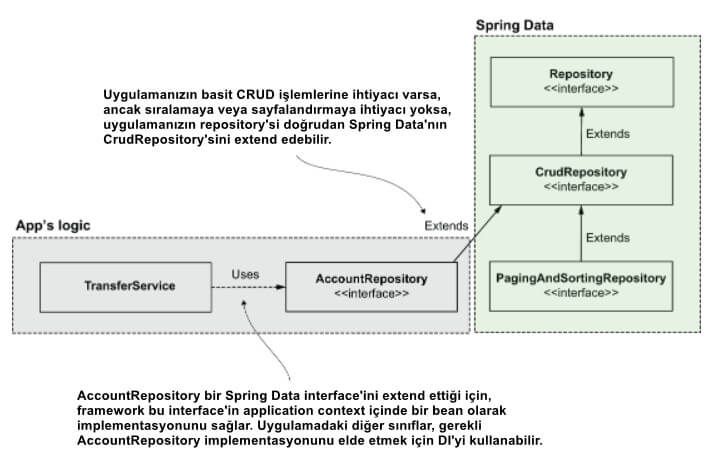
Spring Data repository oluşturmak için Spring Data interface'lerinden birini extend bir interface tanımlarsınız. Örneğin, uygulamanızın yalnızca CRUD işlemlerine ihtiyacı varsa, repository olarak tanımladığınız interface, CrudRepository interface'ini extend etmelidir. Uygulama, tanımladığınız interface'in implementasyonunu Spring Context'e bir bean olarak ekler, böylece onu kullanması gereken diğer tüm uygulama bileşenleri onu context'ten kolayca enjekte edebilir.
Uygulamanızın ayrıca basit CRUD işlemleri üzerinde sayfalama ve sıralama yeteneklerine ihtiyacı varsa, daha özel bir interface olan PagingAndSortingRepository interface'ini (şekil 8) extend etmesi gerekir.
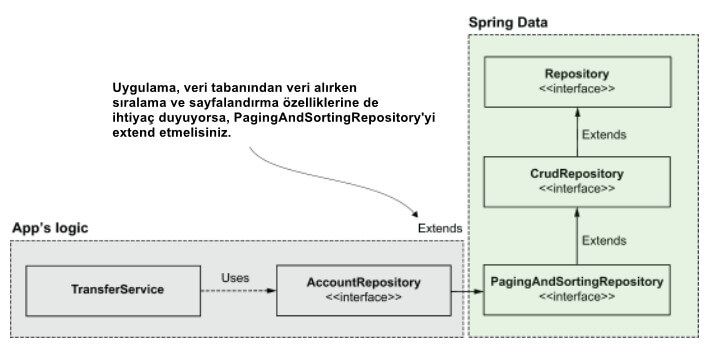
Uygulamanın sıralama ve sayfalama özelliklerine ihtiyacı varsa, daha özel bir interface olan PagingAndSortingRepository interface'i extend etmesi gerekir. Uygulama, interface'i implement eden ve daha sonra onu kullanması gereken diğer herhangi bir bileşenden enjekte edilebilen bir bean sağlar.
Bazı Spring Data modülleri, temsil ettikleri teknolojiye özel interface'ler sağlayabilir. Örneğin, Spring Data JPA kullanarak, JpaRepository interface'ini doğrudan da extend edebilirsiniz (şekil 9'da gösterildiği gibi). JpaRepository arabirimi, PagingAndSortingRepository'den daha özel bir interface'dir. Bu interface, yalnızca Jakarta Persistence API (JPA) spesifikasyonunu implement eden Hibernate gibi belirli teknolojileri kullanırken geçerli olan işlemleri ekler.
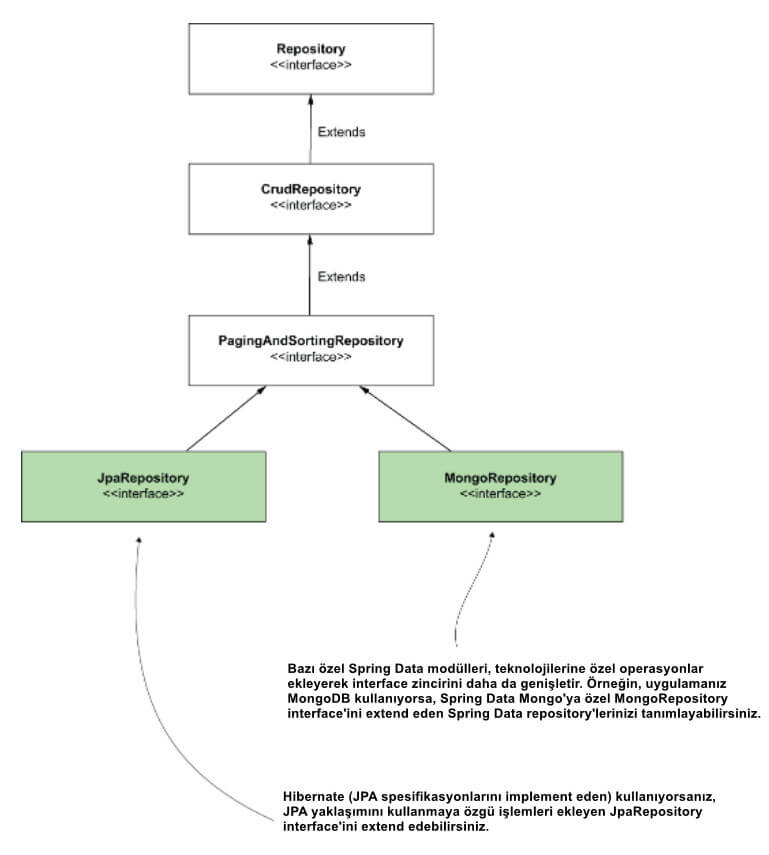
Belirli teknolojilere özgü Spring Data modülleri, yalnızca bu teknolojilerle implement edebileceğiniz işlemleri tanımlayan belirli interface'ler sağlayabilir. Bu tür teknolojileri kullanırken, uygulamanız büyük olasılıkla bu özel interface'leri kullanacaktır.
Başka bir örnek, MongoDB gibi bir NoSQL teknolojisi kullanmaktır. Spring Data'yı MongoDB ile kullanmak için, uygulamanıza, bu persistence teknolojisine özel işlemler ekleyen MongoRepository adlı belirli bir interface sağlayan Spring Data Mongo modülünü eklemeniz gerekir.
Bir uygulama belirli teknolojileri kullandığında, o teknolojiye özel işlemler sağlayan Spring Data sözleşmelerini extend eder. Uygulama, CRUD işlemlerinden daha fazlasına ihtiyaç duymuyorsa yine de CrudRepository'yi uygulayabilir, ancak bu özel interface'ler genellikle, yapıldıkları belirli teknolojiyle kullanımı daha rahat çözümler sunar. Şekil 10'da, AccountRepository sınıfı (uygulamanın) JpaRepository'den (Spring Data JPA modülüne özel) extend edilir.
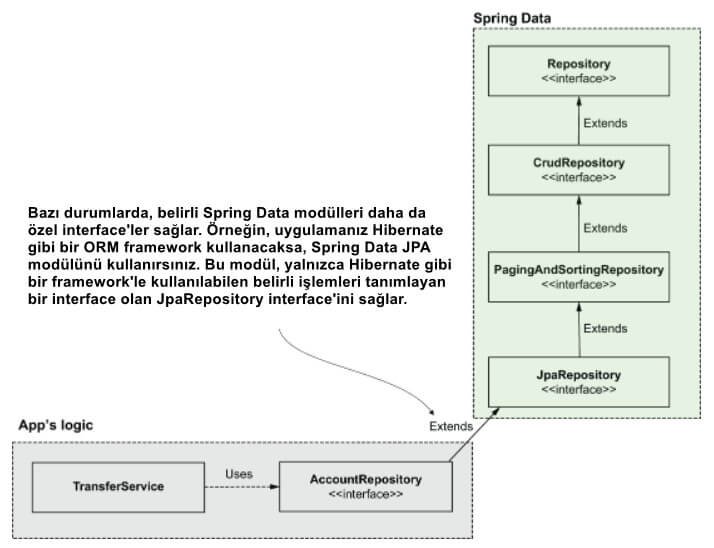
Farklı Spring Data modülleri başka, daha özel interface'ler sağlayabilir. Örneğin, Spring Data ile Hibernate (JPA'yı implement eden) gibi bir ORM framework kullanıyorsanız, yalnızca Hibernate gibi bir JPA uygulaması kullanılırken uygulanabilir işlemleri sağlayan daha özel bir interface olan JpaRepository interface'ini extend edebilirsiniz.
3. Spring Data JDBC Kullanımı
Bu bölümde, bir Spring uygulamasının kalıcılık katmanını uygulamak için Spring Data JDBC kullanıyoruz. Yapmanız gereken tek şeyin bir Spring Data interface'sini extend etmek olduğunu öğrendik, ancak bunu şimdi örnekle görelim. Bu başlıkta ayrıca düz bir repository implement etmeye ek olarak, özel repository işlemlerini nasıl oluşturacağınızı ve kullanacağınızı da öğreneceksiniz.
İlk bölümde üzerinde çalıştığımız senaryoya benzer bir senaryo ele alacağız. Oluşturduğumuz uygulama, kullanıcılarının hesaplarını yöneten bir elektronik cüzdandır. Bir kullanıcı kendi hesabından başka bir hesaba para aktarabilir. Bu öğreticide, kullanıcının bir hesaptan diğerine para göndermesine izin vermek için para transferi use case'ini yazıyoruz. Para transferi işleminin iki adımı vardır (şekil 11):
- Kaynak hesaptan para çekin.
- Hedef hesaba çekilen parayı yatırın.
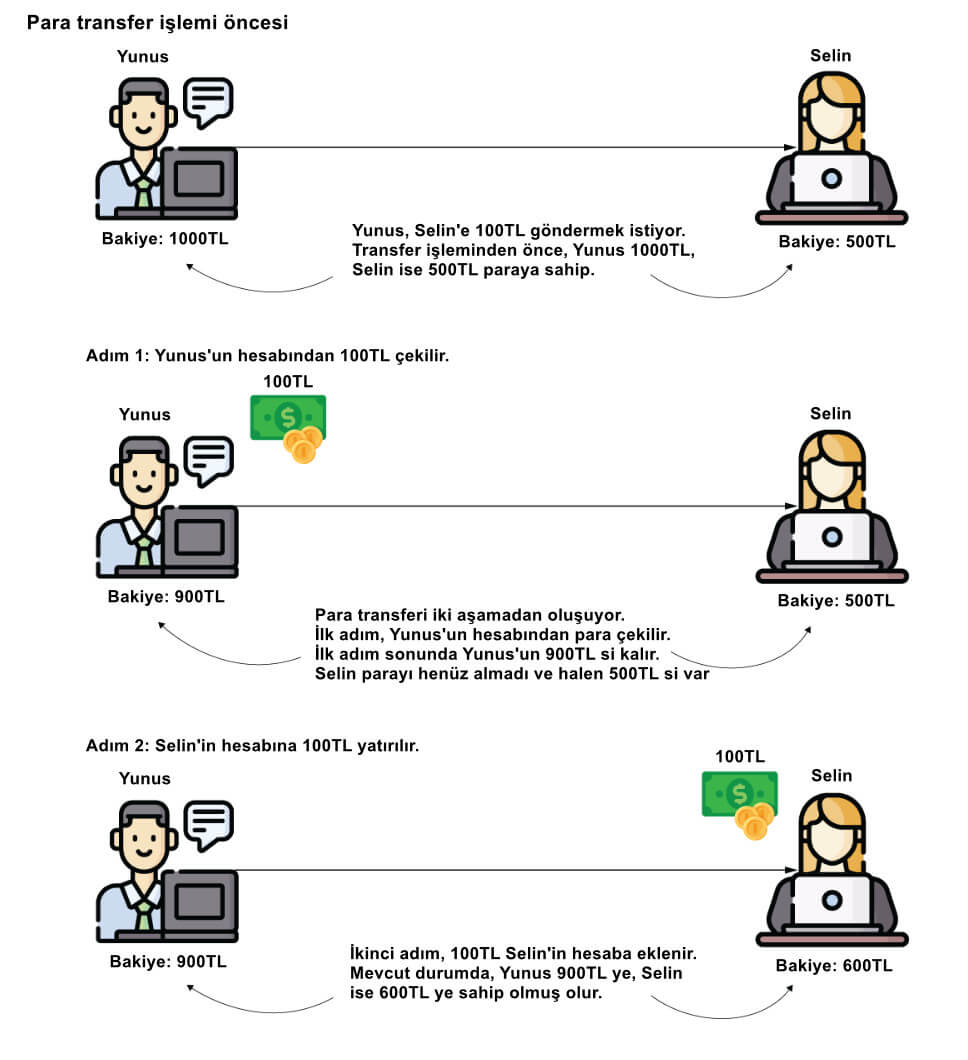
Para transferi use case'i iki adımdan oluşur. İlk olarak, uygulama aktarılan tutarı gönderenin (Yunus'un) hesabından çeker. İkincisi, uygulama aktarılan tutarı alıcının (Selin'in) hesabına yatırır.
Hesap detaylarını veritabanında bir tabloda saklayacağız. Örneği kısa ve basit tutmak ve bu bölümün konusuna odaklanmanıza izin vermek için bir H2 in-memory veritabanı kullanacağız.
Account tablosunda aşağıdaki alanlar bulunur:
- id — Primary key. Bu alanı, auto increment bir INT değeri olarak tanımlarız.
- name — Hesabın sahibinin adı.
- amount — Sahibinin hesapta sahip olduğu para miktarı.
Projeye eklememiz gereken bağımlılıklar (pom.xml dosyasında) sonraki kod parçacığında sunulmuştur:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId> ❶
<artifactId>spring-boot-starter-data-jdbc</artifactId>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>❶ Bu uygulamanın kalıcılık katmanını uygulamak için Spring Data JDBC modülünü kullanıyoruz.
Uygulamanın H2 in-memory veritabanında account tablosunu oluşturmak için Maven projesinin resources klasörüne bir “schema.sql” dosyası ekliyoruz. Bu dosya, sonraki kod parçacığında sunulduğu gibi, account tablosunu oluşturmak için gereken DDL sorgusunu saklar:
create table account (
id INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
amount DOUBLE NOT NULL
);Ayrıca account tablosuna birkaç kayıt eklememiz gerekiyor. Bu kayıtları uygulamayı daha sonra test etmek için kullanacağız. Uygulamaya birkaç kayıt ekleme talimatı vermek için Maven projesinin resources klasöründe bir “data.sql” dosyası oluşturuyoruz. Hesap tablosuna iki kayıt eklemek için, bir sonraki kod parçacığında gösterildiği gibi “data.sql” dosyasına birkaç INSERT ifadesi yazacağız:
INSERT INTO account VALUES (NULL, 'Jane Down', 1000);
INSERT INTO account VALUES (NULL, 'John Read', 1000);Bölümün sonunda, Yunus'tan Selin'e 100TL transfer ederek uygulamanın nasıl çalıştığını göstereceğiz. Şimdi account tablosu kayıtlarını Account isimli bir sınıf ile modelleyelim. Tablodaki her sütunu uygun tipte eşleştirmek için bir field kullanırız.
Ondalık sayılar için, aritmetik işlemlerde hassasiyetle ilgili olası sorunları önlemek için double veya float yerine BigDecimal kullanmanızı önerdiğimi unutmayın.
Veritabanından veri almak gibi sağladığı çeşitli işlemler için Spring Data'nın, tablonun primary key'ini hangi field'ın eşlediğini bilmesi gerekir. Primary key'i işaretlemek için aşağıda gösterildiği gibi @Id anotasyonunu kullanırsınız. Aşağıdaki liste Account model sınıfını gösterir.
public class Account {
@Id ❶
private long id;
private String name;
private BigDecimal amount;
// Omitted getters and setters
}❶ Primary key'i modelleyen field'a @Id anotasyonu ekleriz.
Artık bir model sınıfınız olduğuna göre, Spring Data repository implement edebiliriz. Bu uygulama için sadece CRUD işlemlerine ihtiyacımız var ve bu yüzden CrudRepository interface'ini extend bir interface yazacağız. Tüm Spring Data interface'lerine sağlamanız gereken iki generic tip vardır:
- Repository için yazdığınız model sınıfı (bazen entity olarak adlandırılır)
- Primary key field tipi
public interface AccountRepository
extends CrudRepository<Account, Long> { ❶
}❶ İlk generic tip değeri, tabloyu temsil eden model sınıfının tipidir. İkincisi, primary key field'ının tipidir.
CrudRepository interface'ini extend ettiğinizde Spring Data, primary key ile değer alma, tablodan tüm kayıtları alma, kayıtları silme vb. gibi basit işlemler sağlar. Ancak SQL sorgularıyla uygulayabileceğiniz tüm olası işlemleri size sağlayamaz. Gerçek dünyadaki bir uygulamada, uygulanması için yazılı bir SQL sorgusu gerektiren özel işlemlere ihtiyacınız vardır. Peki Spring Data repository için özel bir işlemi nasıl implement edersiniz?
Spring Data aspect'i o kadar kolaylaştırır ki bazen bir SQL sorgusu yazmanıza bile gerek kalmaz. Spring Data, metot isimlerini bazı adlandırma tanımlama kurallarına göre yorumlamayı bilir ve sizin için sahne arkasında SQL sorgusunu oluşturur. Örneğin, belirli bir ad için tüm hesapları almak için bir işlem yazmak istediğinizi varsayalım. Spring Data'da şu ada sahip bir yöntem yazabilirsiniz: findAccountsByName.
Metod adı "find" ile başladığında, Spring Data bir şeyi SELECT etmek istediğinizi bilir. Ardından, “Accounts” kelimesi, Spring Data'ya hangi tabloda SELECT yapmak istediğiniz şeyi söyler. Spring Data o kadar akıllı ki sadece findByName metodu olarak adlandırdığınızda bile metod AccountRepository interface'inde olduğu için hangi tablonun seçileceğini bilirdi. Bu örnekte daha spesifik olmak ve işlem adını netleştirmek istedim. Metod adındaki “By”dan sonra Spring Data, sorgunun koşulunu (WHERE yan tümcesi) almayı bekler. Bizim durumumuzda, “ByName”yi seçmek istiyoruz, bu nedenle Spring Data bunu WHERE name = ? olarak çevirir.
Şekil 12, metodun adı ile Spring Data'nın perde arkasında oluşturduğu sorgu arasındaki ilişkiyi görsel olarak temsil etmektedir.
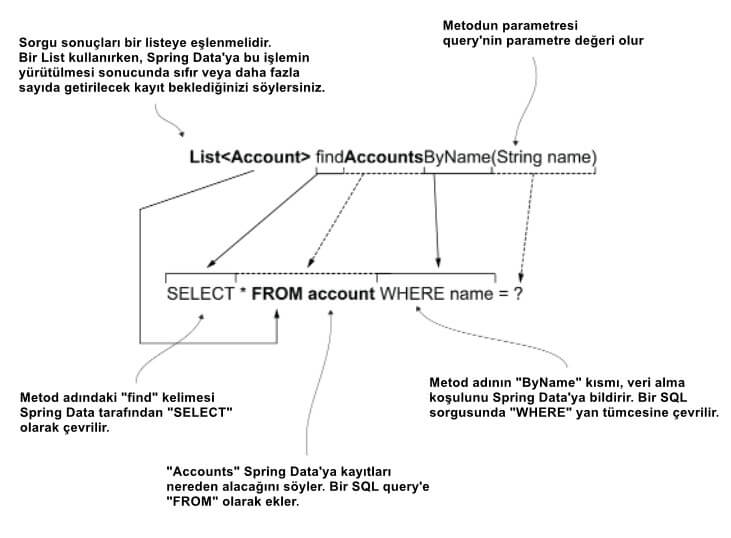
Repository'nin metod adı ile Spring Data'nın perde arkasında oluşturduğu sorgu arasındaki ilişki yukarıdaki gibidir.
Aşağıdaki kod, AccountRepository interface'indeki metodun tanımını gösterir.
public interface AccountRepository
extends CrudRepository<Account, Long> {
List<Account> findAccountsByName(String name);
}Bir metodun adını bir sorguya çevirmenin bu sihri, ilk bakışta inanılmaz görünüyor. Ancak deneyimle, bunun gümüş bir kurşun olmadığını anlarsınız. Birkaç dezavantajı var, bu yüzden geliştiricilerin metodun adını çevirmek için Spring Data'ya güvenmek yerine her zaman sorguyu açıkça belirtmelerini öneririm. Metodun adına güvenmenin başlıca dezavantajları şunlardır:
- İşlem daha karmaşık bir sorgu gerektiriyorsa, metodun adı çok büyük olur ve okunması zor olur.
- Bir geliştirici yanlışlıkla metodun adını yeniden düzenlerse, uygulamanın davranışını fark etmeden etkileyebilir (ne yazık ki, tüm uygulamalar kabaca test edilmez ve bu nedenle bunu dikkate almamız gerekir).
- Metodun adını yazarken size ipuçları sunan bir IDE'niz yoksa Spring Data'nın adlandırma kurallarını öğrenmeniz gerekir. SQL'i zaten bildiğiniz için, yalnızca Spring Data için geçerli olan bir dizi kuralı öğrenmek avantajlı değildir.
- Spring Data'nın ayrıca metod adını bir sorguya çevirmesi gerektiğinden performans etkilenir, bu nedenle uygulama daha yavaş başlatılır (uygulama önyüklendiğinde uygulama metod adlarını sorgulara çevirir).
Bu sorunları önlemenin en basit yolu, bu metodu çağırdığınızda uygulamanın çalıştıracağı SQL sorgusunu belirtmek için @Query anotasyonunu kullanmaktır. @Query metoduna anotasyon eklediğinizde, artık bu metodu nasıl adlandırdığınız önemli değildir. Spring Data, metodun adını bir sorguya çevirmek yerine sağladığınız sorguyu kullanır. Davranış ayrıca daha performanslı hale gelir. Aşağıdaki kod, @Query anotasyonunu nasıl kullanacağınızı gösterir.
public interface AccountRepository
extends CrudRepository<Account, Long> {
@Query("SELECT * FROM account WHERE name = :name") ❶
List<Account> findAccountsByName(String name);
}❶ Sorgudaki parametrenin adının metod parametresinin adıyla aynı olması gerektiğini unutmayın. İki nokta üst üste (:) ile parametre adı arasında boşluk olmamalıdır.
Herhangi bir sorguyu tanımlamak için @Query anotasyonunu aynı şekilde kullanırsınız. Ancak, sorgunuz verileri değiştirdiğinde, yönteme @Modifying anotasyonu eklemeniz de gerekir. UPDATE, INSERT veya DELETE kullanıyorsanız, @Modifying ile metoda anotasyon eklemeniz de gerekir. Aşağıdaki kod, bir repository metodu için bir UPDATE sorgusu tanımlamak için @Query'nin nasıl kullanılacağını gösterir.
public interface AccountRepository
extends CrudRepository<Account, Long> {
@Query("SELECT * FROM account WHERE name = :name")
List<Account> findAccountsByName(String name);
@Modifying ❶
@Query("UPDATE account SET amount = :amount WHERE id = :id")
void changeAmount(long id, BigDecimal amount);
}❶ Verileri değiştiren işlemleri tanımlayan metodları @Modifying anotasyonu ile işaretliyoruz.
Uygulamada ihtiyaç duyduğunuz her yerde AccountRepository interface'ini implement eden bir bean elde etmek için DI'yi kullanın. Sadece interface'i yazdığınız için de endişelenmeyin. Spring Data, dinamik bir implementasyon oluşturur ve uygulamanızın context'ine bir bean ekler. Sonraki kod, uygulamanın TransferService servisinin, AccountRepository tipinde bir bean almak için constructor injection'ı nasıl kullandığını gösterir. Daha önceki yazılarımızda, Spring'in akıllı olduğunu öğrendiniz ve interface tipine sahip bir field için bir DI talep ettiyseniz, o interface'i implement eden bir bean bulması gerektiğini biliyorsunuz.
@Service
public class TransferService {
private final AccountRepository accountRepository;
public TransferService(AccountRepository accountRepository) {
this.accountRepository = accountRepository;
}
}Sonraki kod, para transferi use case implementasyonunu göstermektedir. Hesap ayrıntılarını almak ve hesap tutarlarını değiştirmek için AccountRepository'yi kullanırız. Spring Transactions Nedir ve Nasıl Kullanılır? yazımızda öğrendiğiniz gibi, logic'i bir transaction'a sararak, işlemlerden herhangi biri başarısız olduğunda çıkacak inconsistent verileri önler. Bunun için @Transactional anotasyonunu kullanmaya devam ediyoruz.
@Service
public class TransferService {
private final AccountRepository accountRepository;
public TransferService(AccountRepository accountRepository) {
this.accountRepository = accountRepository;
}
@Transactional ❶
public void transferMoney(
long idSender,
long idReceiver,
BigDecimal amount) {
Account sender = ❷
accountRepository.findById(idSender) ❷
.orElseThrow(() -> new AccountNotFoundException()); ❷
Account receiver = ❷
accountRepository.findById(idReceiver)
.orElseThrow(() -> new AccountNotFoundException());
BigDecimal senderNewAmount = ❸
sender.getAmount().subtract(amount); ❸
BigDecimal receiverNewAmount = ❸
receiver.getAmount().add(amount); ❸
accountRepository ❹
.changeAmount(idSender, senderNewAmount); ❹
accountRepository ❹
.changeAmount(idReceiver, receiverNewAmount); ❹
}
}❶ Herhangi bir işlem başarısız olursa veri tutarsızlıklarını önlemek için use case logic'i bir transaction'a sararız.
❷ Gönderici ve alıcının hesap bilgilerini alırız.
❸ Aktarılan değeri gönderen hesaptan çıkarıp hedef hesaba ekleyerek yeni hesap tutarlarını hesaplıyoruz.
❹ Veritabanındaki hesapların tutarlarını değiştiriyoruz.
Para transferi use case'inde, AccountNotFoundException adlı basit bir runtime exception sınıfı kullandık. Sonraki kod parçacığı, bu sınıfın tanımını sunar:
public class AccountNotFoundException extends RuntimeException {
}Veritabanından tüm kayıtları almak ve hesap detaylarını sahibinin adına göre almak için bir servis metodu ekleyelim. Uygulamamızı test ederken bu işlemleri kullanacağız. Tüm kayıtları almak için metodu kendimiz yazmadık. AccountRepository'miz, aşağıdaki kodda gösterildiği gibi, CrudRepository interface'inden findAll() metodunu devralır.
@Service
public class TransferService {
// Omitted code
public Iterable<Account> getAllAccounts() {
return accountRepository.findAll(); ❶
}
public List<Account> findAccountsByName(String name) {
return accountRepository.findAccountsByName(name);
}
}❶ AccountRepository, bu metodu Spring Data CrudRepository interface'inden devralır.
Aşağıdaki kod, AccountController sınıfının bir REST endpoint aracılığıyla para transferi use case'i nasıl ortaya çıkardığını gösterir.
@RestController
public class AccountController {
private final TransferService transferService;
public AccountController(TransferService transferService) {
this.transferService = transferService;
}
@PostMapping("/transfer")
public void transferMoney( ❶
@RequestBody TransferRequest request
) {
transferService.transferMoney( ❷
request.getSenderAccountId(),
request.getReceiverAccountId(),
request.getAmount());
}
}❶ HTTP request gövdesinden gönderici ve hedef hesap kimliklerini ve aktarılan tutarı alırız.
❷ Para transferi use case'i yürütmek için servisi çağırıyoruz.
Sonraki kod parçacığı, /transfer endpoint'in HTTP request gövdesini eşlemek için kullandığı TransferRequest DTO implementayonunu sunar:
public class TransferRequest {
private long senderAccountId;
private long receiverAccountId;
private BigDecimal amount;
// Omitted getters and setters
}Bir sonraki kodda, kayıtları veritabanından getirmek için bir endpoint implement ediyoruz.
@RestController
public class AccountController {
// Omitted code
@GetMapping("/accounts")
public Iterable<Account> getAllAccounts( ❶
@RequestParam(required = false) String name
) {
if (name == null) { ❷
return transferService.getAllAccounts();
} else { ❸
return transferService.findAccountsByName(name);
}
}
}❶ Hesap ayrıntılarını döndürmek istediğimiz adı almak için isteğe bağlı bir request parametresi kullanıyoruz.
❷ İsteğe bağlı request parametresinde isim belirtilmemişse, tüm hesap detaylarını döndürürüz.
❸ Request parametresinde bir ad verilirse, yalnızca verilen ad için hesap ayrıntılarını döndürürüz.
Uygulamayı başlatıyoruz ve veritabanındaki tüm hesapları döndüren /accounts endpoint'i çağırarak hesap kayıtlarını kontrol ediyoruz:
curl http://localhost:8080/accountsBu komutu çalıştırdıktan sonra, konsolda bir sonraki snippet'te sunulana benzer bir çıktı bulmalısınız:
[
{"id":1,"name":"Yunus","amount":1000.0},
{"id":2,"name":"Selin","amount":1000.0}
]Sonraki kodda gösterilen cURL komutunu kullanarak 100TL'yi Yunus'dan Selin'e aktarmak için /transfer enpointi çağırırız:
curl -XPOST -H "content-type:application/json" -d '{"senderAccountId":1,
➥ "receiverAccountId":2, "amount":100}' http://localhost:8080/transfer/accounts endpointi tekrar çağırırsanız, farkı gözlemlersiniz. Para transferi işleminden sonra Yunus'un sadece 900 TL si varken, Selin'in şimdi 1100 TL si var:
curl http://localhost:8080/accountsPara transferi işleminden sonra /accounts endpoint çağrılmasının sonucu bir sonraki snippet'te sunulur:
[
{"id":1,"name":"Yunus","amount":900.0},
{"id":2,"name":"Selin","amount":1100.0}
]Bir sonraki snippet'te sunulduğu gibi /accounts endpointinde name request parametresini kullanırsanız yalnızca Yunus'un hesabını görürsünüz:
curl http://localhost:8080/accounts?name=YunusBir sonraki snippet'te sunulduğu gibi, bu cURL komutunun response gövdesinde yalnızca Yunus isimli hesapları alacaksınız:
[
{
"id": 1,
"name": "Jane Down",
"amount": 900.0
}
]4. Özet
- Spring Data, Spring uygulamasının persistence (kalıcılık) katmanını daha kolay implement etmenize yardımcı olan bir Spring ekosistem projesidir. Spring Data, çoklu persistence teknolojileri üzerinde bir abstraction (soyutlama) katmanı sağlar ve ortak bir interface seti sağlayarak implementasyonu kolaylaştırır.
- Spring Data ile standart Spring Data interface'lerini extend interface'ler aracılığıyla repository'i implement ederiz:
- Repository, herhangi bir persistence işlemi sağlamaz
- CrudRepository, basit CREATE, READ, UPDATE, DELETE (CRUD) işlemleri sağlar
- PagingAndSortingRepository, CrudRepository'i extend eder ve getirilen kayıtların sayfalandırılması ve sıralanması için işlemler ekler
- Spring Data'yı kullanırken, uygulamanızın kullandığı persistence teknolojisine göre belirli bir modül seçersiniz. Örneğin, uygulamanız DBMS'ye JDBC aracılığıyla bağlanıyorsa, uygulamanız Spring Data JDBC modülüne ihtiyaç duyarken, uygulamanız MongoDB gibi bir NoSQL uygulaması kullanıyorsa Spring Data Mongo modülüne ihtiyaç duyar.
- Spring Data interface'i extend ederken, uygulamanız bu interface tarafından tanımlanan işlemleri devralır ve kullanabilir. Ancak uygulamanız, repository interface'lerinde metodlarla özel işlemler tanımlayabilir.
- Uygulamanızın belirli bir işlem için yürüttüğü SQL sorgusunu tanımlamak için Spring Data repository metodunda @Query anotasyonu kullanırsınız.
- Bir metod bildirirseniz ve @Query anotasyonuyla açıkça bir sorgu belirtmezseniz, Spring Data metodun adını bir SQL sorgusuna çevirecektir. Metod adının anlaşılması ve doğru sorguya dönüştürülmesi için Spring Data kurallarına göre tanımlanması gerekir. Spring Data metod adını çözemezse, uygulama başlatılamaz ve bir exception atar.
- @Query anotasyonu kullanmak ve metod adını sorguya çevirmek için Spring Data'ya güvenmekten kaçınmayı tercih etmelisiniz. Ad çevirisi yaklaşımını kullanmak zorluklarla karşı karşıya kalabilir:
- Uygulamanın sürdürülebilirliğini etkileyen daha karmaşık işlemler için uzun ve okunması zor metod adları oluşturur.
- Uygulamanın şimdi metod adlarını da çevirmesi gerektiğinden, uygulamanın başlatılmasını yavaşlatır.
- Spring Data metodları isim kurallarını öğrenmeniz gerekiyor.
- metod adının yanlış bir şekilde yeniden düzenlenmesiyle uygulamanın davranışını etkileme riskini taşır.
- Verileri değiştiren herhangi bir işlem (örneğin, INSERT, UPDATE veya DELETE sorguları), Spring Data'ya işlemin veri kayıtlarını değiştirdiğini bildirmek için @Modifying anotasyonuyla eklenmelidir.