Spring Data Source ve JDBC Kullanımı
Spring Data Source, JDBC ve JdbcTemplate konularını detaylarıyla ve örneklerle inceliyoruz.


Günümüzde hemen hemen her uygulamanın birlikte çalıştığı verileri depolaması gerekir ve çoğu zaman uygulamalar verileri yönetmek için veritabanlarını kullanır. Uzun yıllar boyunca ilişkisel veritabanları, uygulamalara birçok senaryoda başarıyla uygulayabileceğiniz verileri depolamak için basit ve zarif bir yol sağlamıştır. Spring uygulamalarının, diğer uygulamalar gibi, verileri korumak için genellikle veritabanlarını kullanması gerekir ve bu nedenle Spring uygulamalarınız için bu tür özellikleri nasıl uygulayacağınızı öğrenmeniz gerekir.
Bu bölümde, bir veri kaynağının (data source) ne olduğunu ve Spring uygulamanızın bir veritabanıyla çalışmasını sağlamanın en kolay yolunu tartışacağız. Bu basit yol, Spring'in sunduğu JdbcTemplate aracıdır.
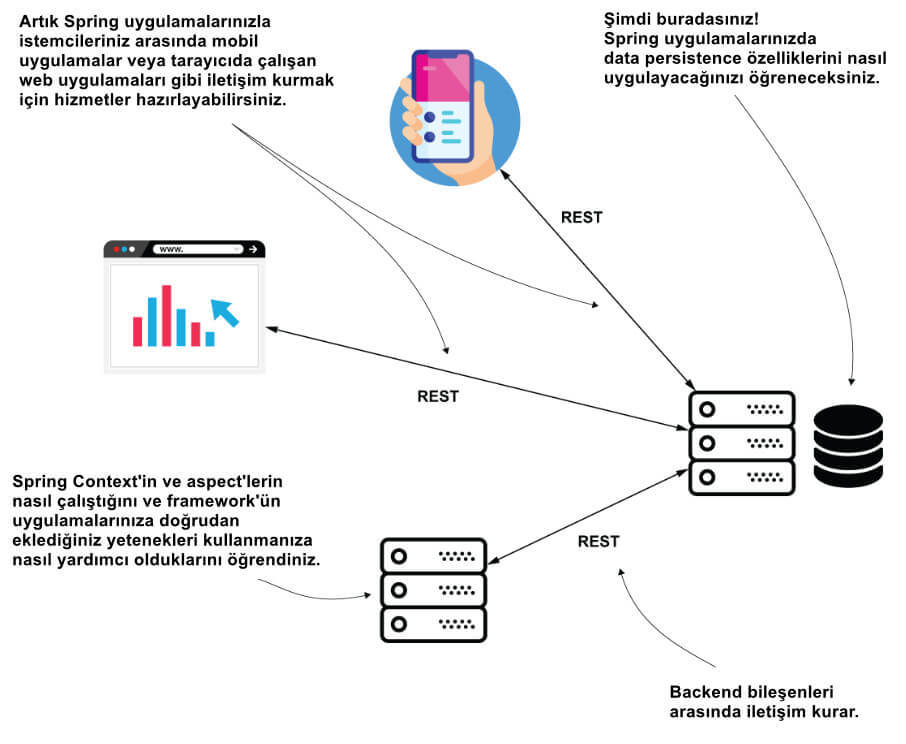
Şekil 1, bir sistemde çeşitli temel yetenekleri implemente etmek için Spring'te kullandağımız genel mimariyi gösteriyor. Şimdiye kadar ki yazılarda bu sistemin diğer bileşenlerini gördük. Artık Spring uygulamanızın kalıcı verilerle çalışmasını sağlamanın değerli becerilerini öğrenme yolculuğunuza başlıyorsunuz.
1. Veri Kaynağı (Data Source) Nedir?
Bu bölümde, Spring uygulamanızın bir veritabanına erişmek için ihtiyaç duyduğu önemli bir bileşeni olan veri kaynağını (data source) tartışıyoruz . Veri kaynağı (şekil 2), veritabanını işleyen sunucuya (DBMS olarak da bilinen veritabanı yönetim sistemi) bağlantıları yöneten bir bileşendir.
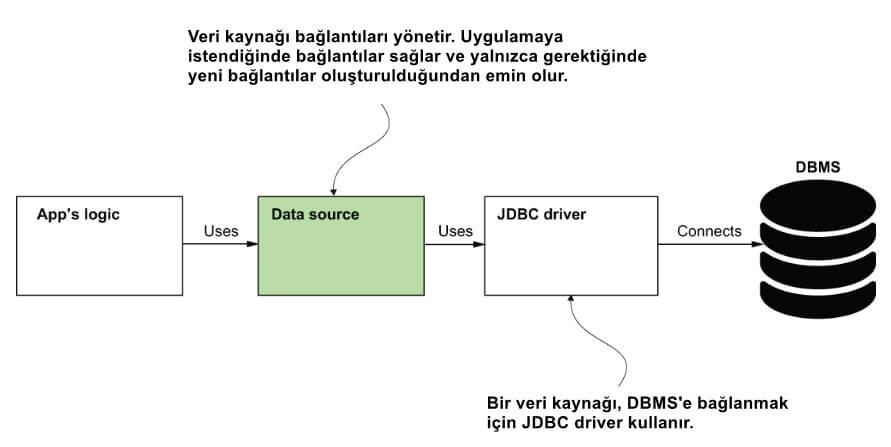
Veri kaynağı (data source), veritabanı yönetim sistemlerine (DBMS) bağlantıları yöneten bir bileşendir. Veri kaynağı, yönettiği bağlantıları almak için JDBC sürücüsünü kullanır. Veri kaynağı, logic'inin DBMS'ye olan bağlantıları yeniden kullanmasına ve yalnızca ihtiyaç duyduğunda yeni bağlantılar istemesine izin vererek uygulamanın performansını iyileştirmeyi amaçlar. Veri kaynağı, bağlantıları serbest bıraktığında da kapatmaya özen gösterir.
NOT: DBMS, kalıcı verileri (persistence data) güvenli tutarken verimli bir şekilde yönetmenize (ekleme, değiştirme, alma) izin vermek olan bir yazılımdır. Bir DBMS, veritabanlarındaki verileri yönetir. Veritabanı kalıcı bir veri topluluğudur.
Bir veri kaynağının sorumluluğunu üstlenen bir nesne olmadan, uygulamanın verilerle yapılan her işlem için yeni bir bağlantı oluşturması gerekir. Bu yaklaşım, production senaryosunda gerçekçi değildir, çünkü her işlem için yeni bir bağlantı kurmak üzere ağ üzerinden iletişim kurmak, uygulamayı önemli ölçüde yavaşlatacak ve performans sorunlarına neden olacaktır. Veri kaynağı, uygulamanızın yalnızca gerçekten ihtiyacı olduğunda yeni bir bağlantı talep etmesini sağlayarak uygulamanın performansını artırır.
İlişkisel bir veritabanında veri kalıcılığıyla ilgili herhangi bir araçla çalışırken Spring sizden bir veri kaynağı tanımlamanızı bekler. Bu nedenle, önce bir veri kaynağının uygulamanın kalıcılık katmanına nereye uyduğunu tartışmamız ve ardından örneklerde bir veri kalıcılık katmanının nasıl uygulanacağını göstermemiz önemlidir.
Bir Java uygulamasında, dilin ilişkisel bir veritabanına bağlanma yeteneklerine Java DataBase Connection (JDBC) adı verilir. JDBC, veritabanıyla çalışmak için bir DBMS'ye bağlanmanın bir yolunu sunar. Ancak JDK, belirli bir teknolojiyle (MySQL, Postgresql veya Oracle gibi) çalışmak için özel bir implementasyon sağlamaz. JDK, yalnızca bir uygulamanın ilişkisel bir veritabanıyla çalışması için gereken nesneler için soyutlamalar (abstraction) sağlar. Bu soyutlamanın implemente edilmesini sağlamak ve uygulamanızın belirli bir DBMS teknolojisine bağlanmasını sağlamak için JDBC driver adında bir runtime bağımlılığı eklersiniz (şekil 3). Her teknoloji satıcısı, belirli bir teknolojiye bağlanabilmesi için uygulamanıza eklemeniz gereken JDBC driver'ını sağlar. JDBC driver, JDK'dan veya Spring gibi bir framework'ten gelen bir şey değildir.
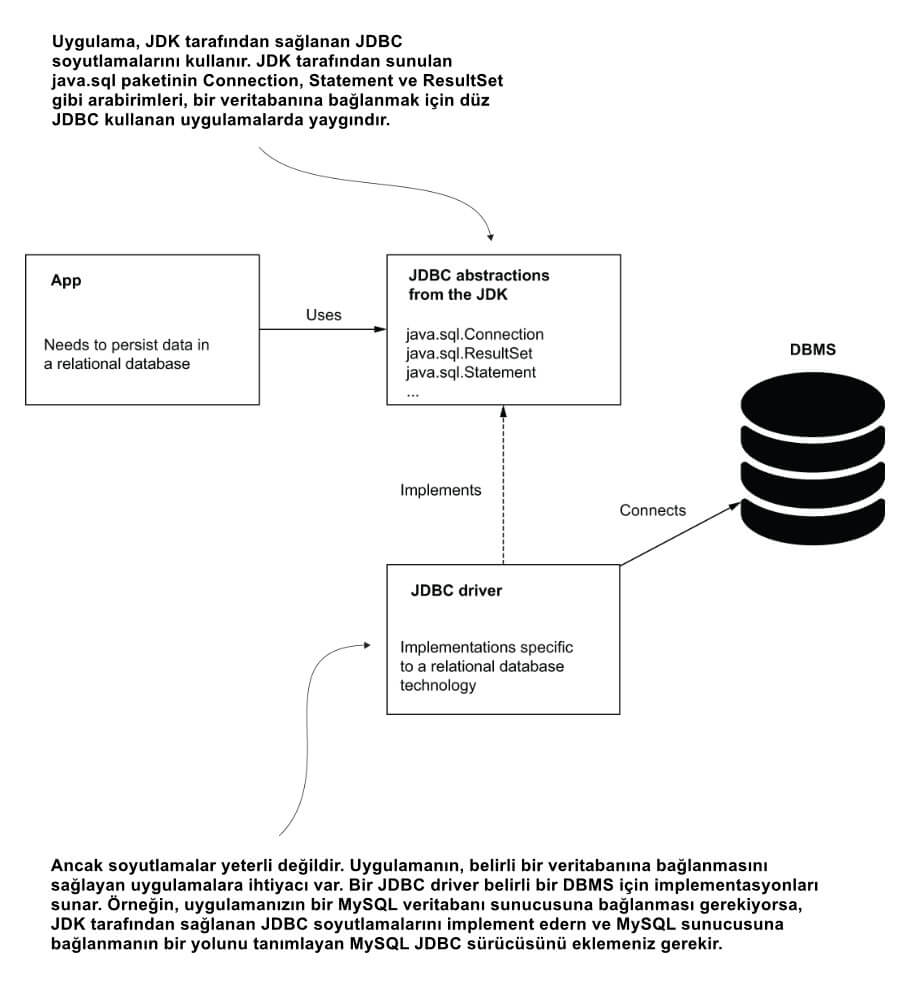
Bir veritabanına bağlanırken, Java uygulaması JDBC kullanır. JDK bir dizi soyutlama (abstraction) sağlar, ancak uygulamanın, uygulamanın bağlandığı ilişkisel veritabanı teknolojisine bağlı belirli bir implementasyona ihtiyacı vardır. JDBC sürücüsü adlı bir runtime bağımlılığı bu implementasyonları sunar. Her özel teknoloji için böyle bir driver vardır ve uygulamanın, bağlanması gereken sunucu teknolojisi için implementasyonları sunan tam driver'a ihtiyacı vardır.
JDBC sürücüsü, DBMS'ye bağlantı elde etmenin bir yolunu sunar. İlk seçenek, JDBC sürücüsünü doğrudan kullanmak ve uygulamanızı, kalıcı veriler üzerinde her yeni işlem gerçekleştirmesi gerektiğinde bağlantı gerektirecek şekilde implemente etmektir. Bu yaklaşımı genellikle Java temelleri öğreticilerinde bulabilirsiniz. Bir Java temelleri öğreticisinde JDBC'i öğrendiğinizde, örnekler genellikle aşağıdaki kod parçacığında sunulduğu gibi bir bağlantı elde etmek için DriverManager adlı bir sınıf kullanır:
Connection con = DriverManager.getConnection(url, username, password);getConnection() metodu, uygulamanızın erişmesi gereken veritabanını tanımlamak için ilk parametre için değer olarak sağlanan URL'yi ve veritabanına erişimi doğrulamak için kullanıcı adı ve parolayı kullanır (şekil 4). Ancak yeni bir bağlantı istemek ve her işlem için tekrar tekrar kimlik doğrulaması yapmak hem istemci hem de veritabanı sunucusu için kaynak ve zaman kaybıdır.
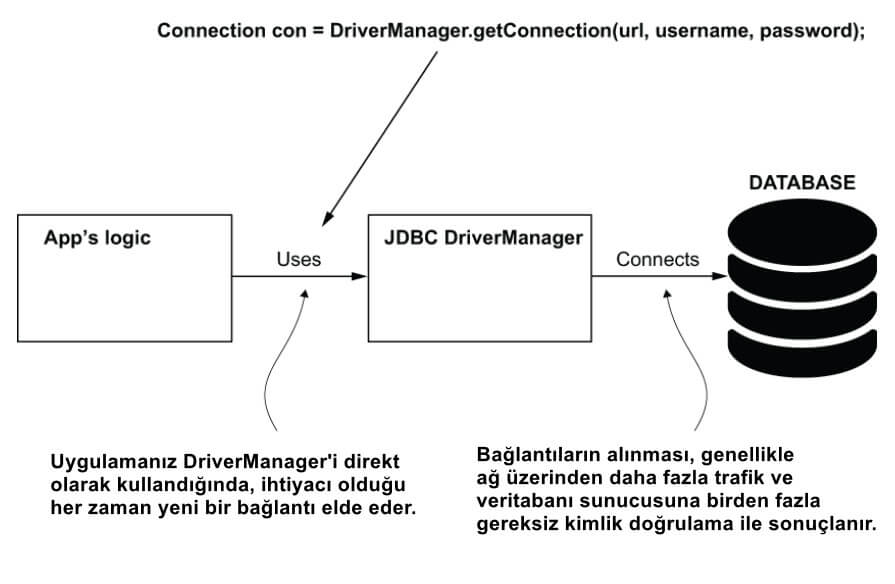
Uygulamanız veritabanı sunucusuna bağlantıları yeniden kullanabilir. Eğer mevcut bağlantılar istemiyorsa ve her seferinde yeni bağlantı oluşturuyorsa, uygulama gereksiz işlemler gerçekleştirerek daha az performans gösterir. Uygulamanın, mevcut bağlantıları kullanabilmek için bu bağlantıları yönetmekten sorumlu bir nesneye (data source) ihtiyacı vardır.
Veri kaynağı nesnesi, gereksiz işlem sayısını en aza indirmek için bağlantıları verimli bir şekilde yönetebilir. JDBC driver yöneticisini doğrudan kullanmak yerine, bağlantıları almak ve yönetmek için bir veri kaynağı kullanıyoruz (şekil 5).
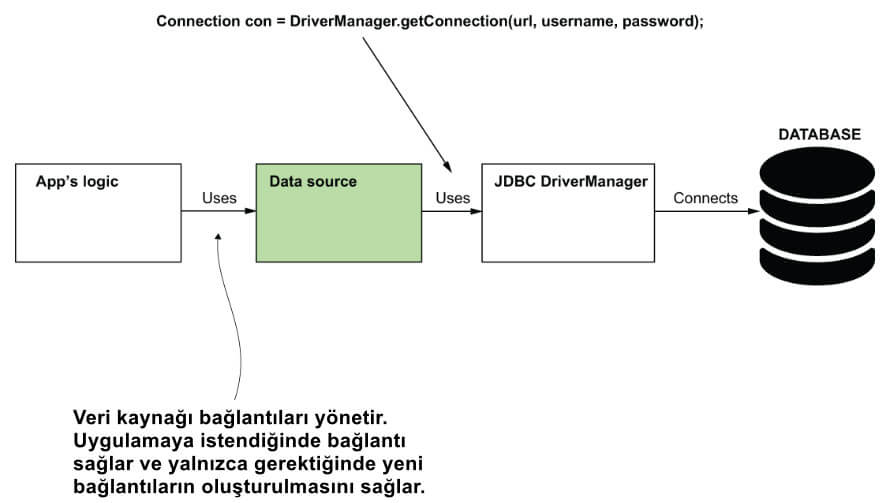
Sınıf tasarımına bir veri kaynağı (data source) eklemek, uygulamanın gereksiz işlemler için zaman ayırmasına yardımcı olur. Veri kaynağı bağlantıları yönetir, uygulamaya istendiğinde bağlantılar sağlar ve yalnızca gerektiğinde yeni bağlantılar oluşturur.
NOT: Veri kaynağı (data source), sorumluluğu uygulama için bir veritabanı sunucusuna olan bağlantıları yönetmek olan bir nesnedir. Uygulamanızın veritabanından verimli bir şekilde bağlantı talep etmesini sağlayarak persistence katmanı işlemlerinin performansını artırır.
Java uygulamaları için veri kaynağı uygulamaları için birden çok seçeneğiniz vardır, ancak günümüzde en çok kullanılanı HikariCP (Hikari connection pool) veri kaynağıdır. Spring Boot'un yapılandırması da HikariCP'yi varsayılan veri kaynağı uygulaması olarak görüyor ve örneklerde kullanacağımız şey bu olacak. Bu veri kaynağı hakkında daha fazla bilgiyi buradan edinebilirsiniz: https://github.com/brettwooldridge/HikariCP . HikariCP açık kaynaktır.
2. Kalıcı Verilerle Çalışmak İçin JdbcTemplate'i Kullanma
Bu bölümde, bir veritabanı kullanan ilk Spring uygulamamızı yazıyoruz ve Spring'in kalıcılık katmanını (persistence) implemente etmek için sağladığı avantajları tartışıyoruz. Uygulamanız, veritabanı sunucusuna bağlantıları verimli bir şekilde elde etmek için bir veri kaynağı kullanabilir. Ancak verilerle çalışmak için ne kadar kolay kod yazabilirsiniz? JDK tarafından sağlanan JDBC sınıflarını kullanmanın, kalıcı verilerle çalışmanın rahat bir yolu olduğu kanıtlanmamıştır. En basit işlemler için bile ayrıntılı kod blokları yazmanız gerekir. Java temelleri örneklerinde, bir sonraki snippet'te sunulan gibi bir kod görmüş olabilirsiniz:
String sql = "INSERT INTO purchase VALUES (?,?)";
try (PreparedStatement stmt = con.prepareStatement(sql)) {
stmt.setString(1, name);
stmt.setDouble(2, price);
stmt.executeUpdate();
} catch (SQLException e) {
// do something when an exception occurs
}Bir tabloya yeni bir kayıt eklemenin basit bir işlemi için bu kadar uzun bir kod bloğu! Ve catch bloğundaki mantığı atladığımı düşün. Ancak Spring, bu tür işlemler için yazdığımız kodu en aza indirmemize yardımcı olur. Spring apps ile kalıcılık katmanını uygulamak için çeşitli alternatifler kullanabiliriz. Bu ve sonraki yazımızda bunun en önemli alternatiflerini göreceğiz. Bu bölümde, JdbcTemplate adlı, JDBC'li bir veritabanıyla basitleştirilmiş bir şekilde çalışmanıza olanak sağlayan bir araç kullanacağız.
JdbcTemplate, Spring'in ilişkisel bir veritabanı kullanmak için sunduğu araçların en basitidir. Ayrıca sizi başka herhangi bir özel persistence framework'ü kullanmaya zorlamadığı için küçük uygulamalar için mükemmel bir seçimdir. JdbcTemplate, uygulamanızın başka bir bağımlılığa sahip olmasını istemediğinizde bir kalıcılık katmanı uygulamak için en iyi Spring seçimidir. Ayrıca, Spring uygulamalarının kalıcılık katmanını nasıl uygulayacağınızı öğrenmeye başlamanın mükemmel bir yolu olduğunu düşünüyorum.
JdbcTemplate'in nasıl kullanıldığını göstermek için bir örnek uygulayacağız. Şu adımları izleyeceğiz:
- DBMS için bir bağlantı oluşturacağız.
- Repository logic'i yazacağız.
- REST endpointlerinin eylemlerini uygulayan metodlarda repository metodlarını çağıracağız.
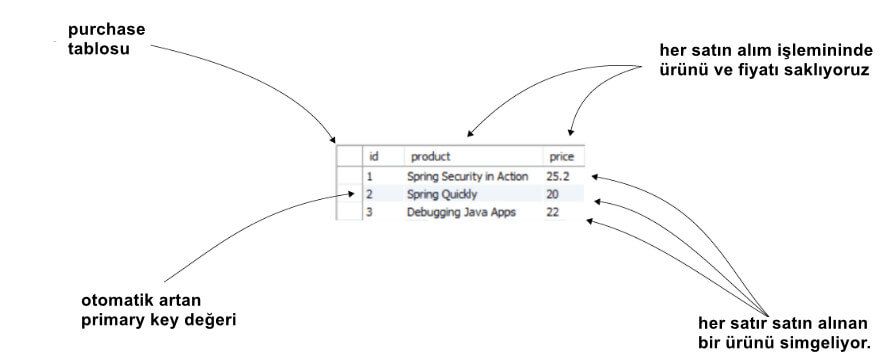
Bu uygulama için, veritabanında “production” isimli bir tablo olacak. Bu tablo, bir çevrimiçi mağazadan satın alınan ürünlerle ilgili ayrıntıları ve satın alma fiyatını saklıyor. Bu tablonun sütunları aşağıdaki gibidir (şekil 6):
- id — Tablonun primary key sorumluluğunu üstlenen auto-incrementing unique değer
- product — Satın alınan ürünün adı
- price — Satın alma ücreti
Bu yazının örnekleri seçtiğiniz herhangi bir ilişkisel veritabanı teknolojisine bağlı değildir. Aynı kodu seçtiğiniz başka bir teknolojiyle kullanabilirsiniz. Ancak, örnekler için belirli bir teknoloji seçmek zorunda kaldım. Bu yazıda, H2'yi (örnekler için mükemmel bir in-memory veritabanı) ve Mysql'i (yerel olarak kolayca yükleyebileceğiniz ücretsiz ve hafif bir teknoloji) kullanacağız (örneklerin in-memory bir şeyden başka bir şeyle çalıştığını kanıtlamak için). Örnekleri Postgresql, Oracle veya MSSQL gibi tercih ettiğiniz diğer ilişkisel veritabanı teknolojileriyle uygulamayı seçebilirsiniz. Böyle bir durumda, runtime için uygun bir JDBC sürücüsü kullanmanız gerekecektir (bu bölümde daha önce de belirtildiği gibi ve Java temel bilgileri'nden bildiğiniz gibi). Ayrıca, SQL sözdizimleri iki farklı ilişkisel veritabanı teknolojileri arasında farklı olabilir. Başka bir şey kullanmaya karar verirseniz, bunları seçtiğiniz teknolojiye uyarlamanız gerekir.
NOT: Uygulamanız H2 veritabanı için de bir JDBC sürücüsü kullanır. Ancak sürücüyü H2 için ayrı olarak eklemeniz gerekmez, çünkü pom'a eklediğiniz H2 veritabanı bağımlılığı ile birlikte gelir.
Yazacağımız uygulama için gereksinimler oldukça basit. İki endpoint'e sahip bir backend servisi geliştireceğiz. İstemciler, satın alma tablosuna yeni bir kayıt eklemek için bir endpoint'i ve satın alma tablosundaki tüm kayıtları almak için ikinci bir endpoint'i çağıracak.
Bir veritabanı ile çalışırken, (kural olarak) repository olarak adlandırdığımız sınıflarda kalıcılık katmanıyla ilgili tüm yetenekleri implemente ederiz. Şekil 7, yazmak istediğimiz uygulamanın sınıf tasarımını göstermektedir.
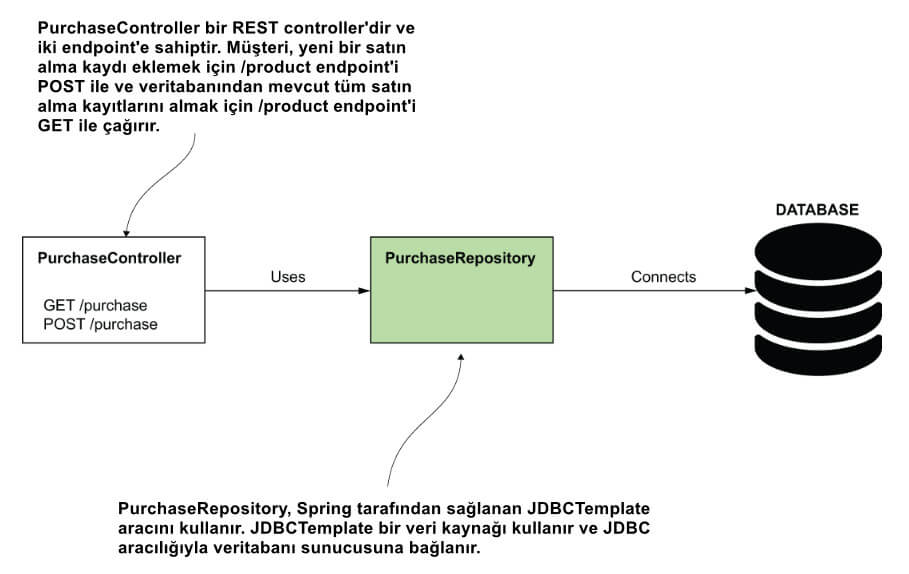
NOT: Repository, veritabanıyla çalışmaktan sorumlu bir sınıftır.
Gerekli bağımlılıkları ekleyerek uygulamayı her zamanki gibi başlatıyoruz. Bir sonraki kod parçacığı, projenin pom.xml'inde göründükleri gibi eklemeniz gereken bağımlılıkları gösterir.
<dependency> ❶
<groupId>org.springframework.boot</groupId> ❶
<artifactId>spring-boot-starter-web</artifactId> ❶
</dependency> ❶
<dependency> ❷
<groupId>org.springframework.boot</groupId> ❷
<artifactId>spring-boot-starter-jdbc</artifactId> ❷
</dependency> ❷
<dependency> ❸
<groupId>com.h2database</groupId> ❸
<artifactId>h2</artifactId> ❸
<scope>runtime</scope> ❹
</dependency>❶ REST endpointleri implemente etmek için web bağımlılığını kullanıyoruz.
❷ JDBC kullanarak veritabanlarıyla çalışmak için gerekli JDBC starter'ı ekleyerek gerekli Spring yeteneklerini elde ediyoruz.
❸ Bu örnekte hem in-memory bir veritabanı hem de onunla çalışacak bir JDBC sürücüsü elde etmek için H2 bağımlılığını ekliyoruz.
❹ Uygulamanın yalnızca çalışma zamanında (runtime) veritabanına ve JDBC sürücüsüne ihtiyacı vardır. Uygulamanın compile için onlara ihtiyacı yoktur. Maven'e bu bağımlılıkları yalnızca çalışma zamanında istediğimizi söylemek için scope etiketini "runtime" değeriyle ekliyoruz.
Bu örnek için bir veritabanı sunucunuz olmasa bile, H2 bağımlılığı veritabanını simüle eder. H2, bir uygulamanın işlevselliğini test etmek, ancak veritabanına bağımlılığını dışlamak istediğimizde hem örnekler hem de uygulama testleri için kullandığımız mükemmel bir araçtır.
Satın alma kayıtlarını saklayan bir tablo eklememiz gerekiyor. Teorik örneklerde, Maven projesinin resources klasörüne "schema.sql" adlı bir dosya ekleyerek bir veritabanı yapısı oluşturmak kolaydır (şekil 8).
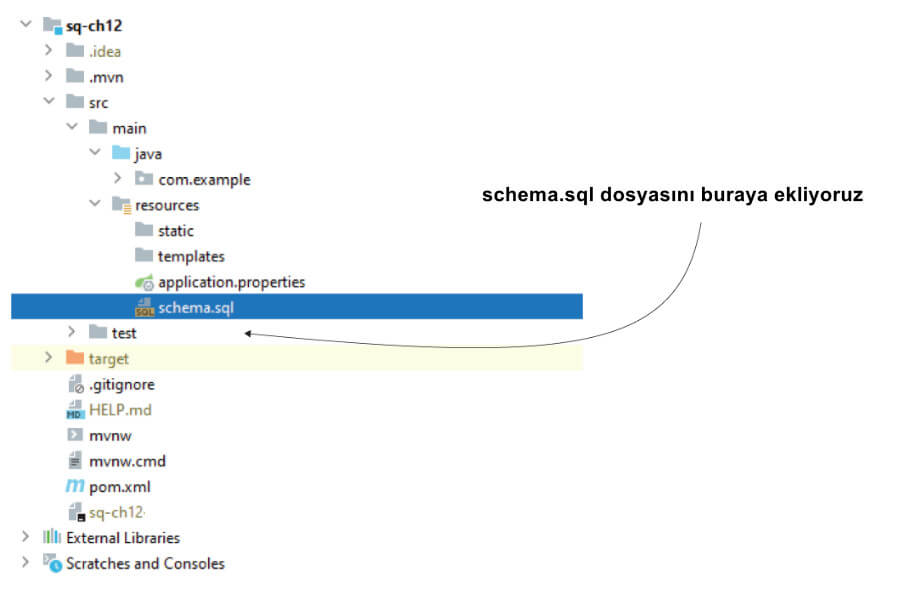
Maven projesinde, veritabanı yapısını tanımlayan sorguları yazabileceğiniz "schema.sql" dosyası resources klasöründedir. Spring, uygulama başladığında bu sorguları yürütür.
Bu dosyada, veritabanı yapısını tanımlamak için ihtiyacınız olan tüm yapısal SQL sorgularını yazabilirsiniz. Ayrıca geliştiricilerin bu sorguları “Data Description Language” (DDL) olarak adlandırdığını da görürsünüz. Şimdi projemize böyle bir dosya ekleyeceğiz ve bir sonraki kod snippet'inde sunulduğu gibi purchase tablosunu oluşturmak için sorguyu ekleyeceğiz:
CREATE TABLE IF NOT EXISTS purchase (
id INT AUTO_INCREMENT PRIMARY KEY,
product varchar(50) NOT NULL,
price double NOT NULL
);NOT: Veritabanı yapısını tanımlamak için bir schema.sql dosyası kullanmak yalnızca teorik örnekler için çalışır. Bu yaklaşım kolaydır çünkü hızlıdır ve bir öğreticide veritabanı yapısının tanımı yerine öğrendiğiniz şeylere odaklanmanıza olanak tanır. Ancak gerçek dünyadan bir örnekte, veritabanı komut dosyalarınızı sürümlendirmenize de izin veren bir bağımlılık kullanmanız gerekecektir. Flyway (https://flywaydb.org/) ve Liquibase'e (https://www.liquibase.org/) bakmanızı tavsiye ederim. Bunlar, veritabanı şeması sürüm oluşturma için çok popüler iki bağımlılıktır.
Uygulamamızdaki satın alma verilerini tanımlamak için bir model sınıfına ihtiyacımız var. Bu sınıfın örnekleri veritabanındaki purchase tablosunun satırlarıyla eşleşir. Böylece her instance öznitelik olarak bir id, name ve price'a sahip olur. Bir sonraki kod parçacığı Purchase modeli sınıfını gösterir:
public class Purchase {
private int id;
private String product;
private BigDecimal price;
// Omitted getters and setters
}Purchase sınıfı price özniteliğinin tipinin BigDecimal olduğunu ilginç bulabilirsiniz. Double olarak tanımlayamaz mıydık? İşte farkında olmanızı istediğim önemli bir şey var: teorik örneklerde, ondalık değerler için sıklıkla double kullanıldığını görürsünüz, ancak birçok gerçek dünya örneğinde, ondalık sayılar için double veya float kullanmak doğru bir şey değildir. Double ve float değerleriyle çalışırken, toplama veya çıkarma gibi basit aritmetik işlemler için bile hassasiyeti kaybedebilirsiniz. Bu etki, Java'nın bu değerleri bellekte saklama biçiminden kaynaklanır. Fiyatlar gibi hassas bilgilerle çalışırken, bunun yerine BigDecimal tipini kullanmalısınız. Dönüşüm konusunda endişelenmeyin. Spring'in sağladığı tüm temel özellikler Bigdecimal'in nasıl kullanılacağını bilir.
NOT: Ondalık değerleri doğru bir şekilde depolamak ve değerlerle çeşitli işlemleri yürütürken ondalık duyarlığı kaybetmediğinizden emin olmak istediğinizde, BigDecimal kullanın, double veya float kullanmayın!
Controller'da ihtiyaç duyduğumuzda kolayca bir PurchaseRepository instance'ı elde etmek için, bu nesneyi Spring Context'te bir bean haline getireceğiz. En basit yaklaşım daha önceki yazılarda da öğrendiğimiz gibi bir stereotype anotasyonu (@Component veya @Service gibi) kullanmaktır. Ancak @Component kullanmak yerine Spring, kullanabileceğimiz repository'lere odaklanmış bir anotasyon sağlar: @Repository. Daha önce service sınıfları için @Service kullanmayı öğrendiğiniz gibi, repository'ler için Spring'e context'ine bir bean eklemesi talimatı vermek için @Repository stereotype anotasyonunu kullanmalısınız. Aşağıdaki liste size repository sınıfı tanımını gösterir.
@Repository ❶
public class PurchaseRepository {
}❶ Spring context'ine bu sınıf tipinden bir bean eklemek için @Repository stereotype anotasyonunu kullanıyoruz.
Artık PurchaseRepository uygulama context'inde bir bean olduğuna göre, veritabanıyla çalışmak için kullanacağımız bir JdbcTemplate instance'ı enjekte edebiliriz. Ne düşündüğünüzü biliyorum! “Bu JdbcTemplate instance'ı nereden geliyor? Bu instance'ı zaten depomuza enjekte edebilmemiz için kim yarattı?” Bu örnekte, birçok production senaryosunda olduğu gibi, Spring Boot'un büyüsünden bir kez daha yararlanacağız. Spring Boot, pom.xml'de H2 bağımlılığını eklediğinizi gördüğünde, otomatik olarak bir veri kaynağı (data source) ve bir JdbcTemplate instance'ını yapılandırdı. Bu örnekte, onları doğrudan kullanacağız.
Spring Framework kullanıyorsanız ancak Spring Boot kullanmıyorsanız, DataSource bean'ini ve JdbcTemplate bean'ini tanımlamanız gerekir (daha önce öğrendiğiniz gibi yapılandırma sınıfındaki @Bean anotasyonunu kullanarak bunları Spring Context'e ekleyebilirsiniz). Bir sonraki başlıkta, bunları nasıl özelleştireceğinizi ve hangi senaryolar için kendi veri kaynağınızı ve JdbcTemplate instance'larınızı tanımlamanız gerektiğini göstereceğim. Aşağıdaki kod, uygulamanız için yapılandırılmış JdbcTemplate Spring Boot instance'ının nasıl enjekte edileceğini gösterir.
@Repository
public class PurchaseRepository {
private final JdbcTemplate jdbc;
public PurchaseRepository( ❶
JdbcTemplate jdbc) {
this.jdbc = jdbc;
}
}❶ Application Context'inden JdbcTemplate instance'ı almak için constructor injection kullanıyoruz.
Son olarak, bir JdbcTemplate instance'ımız var, böylece uygulamanın gereksinimlerini uygulayabiliriz. JdbcTemplate, veri güncelleme için herhangi bir sorguyu yürütmekte kullanabileceğiniz şu üç update() yöntemine sahiptir: INSERT, UPDATE veya DELETE. Bu metodlara sadece SQL'i ve ihtiyaç duyduğu parametreleri geçirmek yeterli olacaktır çünkü JdbcTemplate geri kalanıyla ilgilenir (bağlantı edinme, Statement oluşturma, SQLException'ı handle etme vb.). Aşağıdaki kod, PurchaseRepository sınıfına storePurchase() metodunu ekler. storePurchase() metodu, purchase tablosuna yeni bir kayıt eklemek için JdbcTemplate kullanır.
@Repository
public class PurchaseRepository {
private final JdbcTemplate jdbc;
public PurchaseRepository(JdbcTemplate jdbc) {
this.jdbc = jdbc;
}
public void storePurchase(Purchase purchase) { ❶
String sql = ❷
"INSERT INTO purchase VALUES (NULL, ?, ?)";
jdbc.update(sql, ❸
purchase.getProduct(),
purchase.getPrice());
}
}❶ Metod, depolanacak verileri temsil eden bir parametre alır.
❷ Sorgu bir dize olarak yazılır ve soru işaretleri (?) sorguların parametre değerlerinin yerini alır. ID için NULL kullanıyoruz, çünkü DBMS'yi bu sütun için değer oluşturacak şekilde yapılandırdık.
❸ JdbcTemplate update() metodu sorguyu veritabanı sunucusuna gönderir. Metodun aldığı ilk parametre sql sorgudur ve sonraki parametreler parametrelerin değerleridir. Bu değerler, sorgudaki her soru işaretinin yerini aynı sırada alır.
Birkaç kod satırıyla tablolara kayıt ekleyebilir, güncelleştirebilir veya silebilirsiniz. Veri almakta bundan daha zor değildir. Ekleme işlemi gelince, bir sorgu yazıp gönderirsiniz. Veri almak için bu kez bir SELECT sorgusu yazmalısınız. Ve JdbcTemplate'e verilerin Purchase nesnelerine (model sınıfınız) nasıl dönüştürüleceğini söylemek için bir RowMapper implement edersiniz. RowMapper, bir satırı (row) bir nesneye dönüştürmekten sorumludur. Örneğin, Purchase nesneleri olarak modellenen veritabanından verileri almak istiyorsanız, bir satırın Bir Purchase instance'ıyla eşlenme şeklini tanımlamak için bir RowMapper uygulamanız gerekir (Şekil 9).
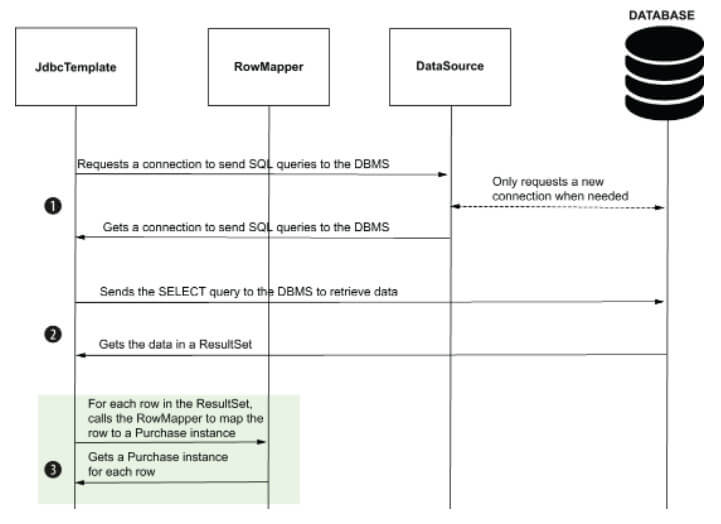
JdbcTemplate, ResultSet'i Purchase instance listesiyle değiştirmek için RowMapper'ı kullanır. ResultSet'teki her satır için JdbcTemplate, satırı bir Purchase instance'ıyla eşlemek için RowMapper'ı çağırır. Diyagram, JdbcTemplate'in SELECT sorgusunu göndermek için izlediği üç adımı da sunar: (1) DBMS bağlantısı alıp, (2) sorguyu gönderip sonucu alır ve (3) sonucu Purchase instance'ıyla eşler.
Aşağıdaki kod, purchase tablosundaki tüm kayıtları almak için bir repository metodunun nasıl implement edileceğini gösterir.
@Repository
public class PurchaseRepository {
// Omitted code
public List<Purchase> findAllPurchases() { ❶
String sql = "SELECT * FROM purchase"; ❷
RowMapper<Purchase> purchaseRowMapper = (r, i) -> { ❸
Purchase rowObject = new Purchase(); ❹
rowObject.setId(r.getInt("id")); ❹
rowObject.setProduct(r.getString("product")); ❹
rowObject.setPrice(r.getBigDecimal("price")); ❹
return rowObject; ❹
};
return jdbc.query(sql, purchaseRowMapper); ❺
}
}❶ Metod, veritabanından aldığı kayıtları Purchase nesneleri listesinde döndürür.
❷ purchase tablosundan tüm kayıtları almak için SELECT sorgusunu tanımlarız.
❸ JdbcTemplate'e sonuç kümesindeki bir satırın Purchase nesnesine nasıl eşlendiğini söyleyen bir RowMapper nesnesi oluşturuyoruz. Lambda ifadesinde, "r" parametresi ResultSet (veritabanından elde ettiğiniz veriler), "i" parametresi ise satır numarasını temsil eden bir int.
❹ Verileri bir Purchase instance'ı olarak ayarladık. JdbcTemplate, sonuç kümesindeki her satır için bu logic'i kullanır.
❺ SELECT sorgusunu query metodu kullanarak göndeririz ve JdbcTemplate'in Purchase nesnelerinde aldığı verileri nasıl dönüştüreceğini bilmesi için RowMapper nesnesini veririz.
Repository metodlarına sahip olduktan ve kayıtları veritabanında depolayıp alabildiğinizde, bu yöntemleri endpointler aracılığıyla göstermenin zamanı geldi demektir. Aşağıdaki kod size controller tarafını gösterir.
@RestController
@RequestMapping("/purchase")
public class PurchaseController {
private final PurchaseRepository purchaseRepository;
public PurchaseController( ❶
PurchaseRepository purchaseRepository) {
this.purchaseRepository = purchaseRepository;
}
@PostMapping
public void storePurchase(@RequestBody Purchase purchase) {
purchaseRepository.storePurchase(purchase); ❷
}
@GetMapping
public List<Purchase> findPurchases() {
return purchaseRepository.findAllPurchases(); ❸
}
}❶ Spring context'ten repository nesnesini almak için constructor injection kullanıyoruz.
❷ Veritabanında bir purchase kaydını depolamak için bir istemcinin çağırdıği bir endpoint oluşturuyoruz. Controller, HTTP request gövdesinden aldığı verileri kalıcı hale getirmek için repository'nin storePurchase() metodunu kullanır.
❸ purchase tablosundan tüm kayıtları almak için istemcinin çağırdıği bir endpoint oluşturuyoruz. Controller, veritabanından veri almak için repository'nin metodunu kullanır ve verileri HTTP response body ile istemciye döndürür.
Uygulamayı şimdi çalıştırırsanız, POST veya cURL kullanarak iki endpointi test edebilirsiniz.
Purchase tablosuna yeni bir kayıt eklemek için, bir sonraki snippet'te sunulduğu gibi HTTP POST ile /purchase endpointi çağırın:
curl -XPOST 'http://localhost:8080/purchase' \
-H 'Content-Type: application/json' \
-d '{
"product" : "Kerteriz Blog ile Spring Dersleri",
"price" : 48.5
}'Daha sonra, uygulamanın purchase kaydını doğru şekilde depoladığını kanıtlamak için HTTP GET /purchase endpointi çağırabilirsiniz. Sonraki snippet, request için cURL komutunu gösterir:
curl 'http://localhost:8080/purchase'İsteğin HTTP response body'si, bir sonraki snippet'te sunulduğu gibi veritabanındaki tüm purchase kayıtlarının bir listesidir:
[
{
"id": 1,
"product": "Kerteriz Blog ile Spring Dersleri",
"price": 48.5
}
]3. Veri Kaynağının (Data Source) Yapılandırmasını Özelleştirme
Bu bölümde, JdbcTemplate'in veritabanıyla çalışmak için kullandığı veri kaynağını özelleştirmeyi öğreneceksiniz. Önceki örneklerde kullandığımız H2 veritabanı, örnekler ve öğreticiler için ve bir uygulama için kalıcılık katmanını uygulamaya başlamada mükemmeldir. Ancak production uygulamalarında, in-memory veritabanından daha fazlasına ihtiyacınız vardır ve genellikle veri kaynağını da yapılandırmanız gerekir.
Gerçek dünya senaryolarında DBMS kullanmayı öğrenmek için önceki örneklerimizin aynısını MySQL sunucusu kullanacak şekilde değiştireceğiz. Örnekteki mantığın değişmediğini ve veri kaynağını farklı bir veritabanına işaret edecek şekilde değiştirmenin zor olmadığını gözlemleyeceksiniz. Takip edeceğimiz adımlar şunlardır:
- İlk bölümde bir MySQL JDBC driver'ı ekleyeceğiz ve bir MySQL veritabanına işaret etmek için "application.properties" dosyasını kullanarak veri kaynağı (data source) yapılandıracağız. Yine de Spring Boot'un, tanımladığımız özelliklere göre Spring Context'inde bir DataSource bean'i tanımlamasına izin vereceğiz.
- İkinci bölümde, özel bir DataSource bean'i tanımlamak için projeyi değiştireceğiz ve gerçek dünyadaki senaryolarda böyle bir şeye ne zaman ihtiyaç duyulduğunu tartışacağız.
3.1 Application.properties Dosyasında Veri Kaynağı (Data Source) Tanımlama
Bu bölümde, uygulamamızı bir MySQL DBMS'ye bağlayacağız. Çünkü uygulamalar harici veritabanı sunucularını kullanır ve bu nedenle bu beceriye sahip olmak size yardımcı olacaktır.
Bu bölümdeki örnekler için öncelikle bir MySQL sunucusu yüklemeniz ve bağlanacağınız bir veritabanı oluşturmanız gerekir. İsterseniz alternatif bir veritabanı teknolojisini de (Postgresql veya Oracle gibi) kullanabilirsiniz.
Bu dönüşümü gerçekleştirmek için iki basit adımı takip edeceğiz:
- H2'yi çıkarmak ve gerekli JDBC sürücüsünü eklemek için proje bağımlılıklarını değiştireceğiz.
- Yeni veritabanının bağlantı özelliklerini "application.properties" dosyasına ekleyeceğiz.
1. adım için, pom.xml dosyasındaki H2 bağımlılığını çıkarıyoruz. Ayrıca MySQL kullanıyorsanız MySQL JDBC sürücüsünü eklemeniz de gerekir. Projenin artık bir sonraki snippet'te sunulduğu gibi bağımlılıklara sahip olması gerekir:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId> ❶
<scope>runtime</scope>
</dependency>❶ MySQL JDBC sürücüsünü runtime bağımlılığı olarak ekliyoruz.
2. adım için, "application.properties" dosyası aşağıdaki kod snippet'i gibi görünmelidir. Veritabanı adresini tanımlamak için spring.datasource.url özelliğini ve uygulamanın kimlik doğrulaması yapmak ve DBMS'den bağlantı almak için ihtiyaç duyduğu kimlik bilgilerini tanımlamak adına spring.datasource.username ve spring.datasource.password özelliklerini eklemeliyiz. Ayrıca, Spring Boot'a "schema.sql" dosyasını kullanmasını ve purchase tablosunu oluşturmasını söylemek için spring.datasource.initialization-mode özelliğini "always" değeriyle kullanmamız gerekir. Bu özelliği H2 ile kullanmanıza gerek yoktur. H2 için, bu dosya varsa, Spring Boot varsayılan olarak "schema.sql" dosyasındaki sorguları çalıştırır:
spring.datasource.url=jdbc:mysql://localhost/spring_quickly?
useLegacyDatetimeCode=false&serverTimezone=UTC ❶
spring.datasource.username=<dbms username> ❷
spring.datasource.password=<dbms password> ❷
spring.datasource.initialization-mode=always ❸❶ Veritabanının adresini tanımlayan URL'yi yapılandırıyoruz.
❷ Kullanıcı bilgilerini kimlik doğrulaması yapmak ve DBMS'den bağlantı almak için yapılandırıyoruz.
❸ Spring'e "schema.sql" dosyasındaki sorguları çalıştırmasını öğretmek için başlatma modunu "always" olarak ayarladık.
NOT: Hassas verileri (parolalar gibi) properties dosyasında depolamak, production uygulamalarda iyi bir yöntem değildir. Bu tür özel detaylar gizli kasalarda saklanır. Bu kitapta gizli kasaları tartışmayacağız çünkü bu konu temellerin çok ötesinde yer alıyor. Ancak, şifreleri böyle açık bir şekilde tanımlamanın sadece örnekler ve öğreticiler için olduğunu bilmeni istiyorum.
Bu birkaç değişiklikle, uygulama artık MySQL veritabanını kullanır hale geldi. Spring Boot, "application.properties" dosyasında sağladığınız spring.datasource özelliklerini kullanarak DataSource bean'ini oluşturmayı bilir. Artık uygulamayı başlatabilir ve endpointleri test edebilirsiniz.
Purchase tablosuna yeni bir kayıt eklemek için, bir sonraki snippet'te sunulduğu gibi HTTP POST ile /purchase endpoint'i çağıralım:
curl -XPOST 'http://localhost:8080/purchase' \
-H 'Content-Type: application/json' \
-d '{
"product" : "Spring Security in Action",
"price" : 25.2
}'Daha sonra, uygulamanın satın alma kaydını doğru şekilde depoladığını kanıtlamak için HTTP GET /purchase endpoint'i çağıralım. Sonraki snippet, request için cURL komutunu gösterir:
curl 'http://localhost:8080/purchase'İsteğin HTTP response gövdesi, bir sonraki snippet'te sunulduğu gibi veritabanındaki tüm satın alma kayıtlarının bir listesini içerir:
[
{
"id": 1,
"product": "Spring Security in Action",
"price": 25.2
}
]3.2 Özel DataSource Bean'i Kullanmak
"application.properties" dosyasında bağlantı ayrıntılarını sağlarsanız, Spring DataSource bean'inin nasıl kullanılacağını bilir. Çoğu zaman bu yeterlidir ve her zamanki gibi sorunlarınızı çözen en basit çözümle gitmenizi öneririm. Ancak diğer durumlarda, DataSource bean'ini oluşturmak için Spring Boot'a güvenemezsiniz. Böyle bir durumda, bean'i kendiniz tanımlamanız gerekir. Bean'i kendiniz tanımlamanız gereken bazı senaryolar şunlardır:
- Yalnızca çalışma zamanında alabileceğiniz bir koşulu temel alan belirli bir DataSource implementasyonu kullanmanız gerekiyorsa.
- Uygulamanız birden fazla veritabanına bağlanır, bu nedenle birden fazla veri kaynağı oluşturmanız ve qualifier kullanarak bunları ayırt etmeniz gerekiyorsa.
- DataSource nesnesinin belirli parametrelerini, uygulamanızın yalnızca çalışma zamanında sahip olduğu belirli koşullarda yapılandırmanız gerekiyorsa. Örneğin, uygulamayı başlatdığınız ortama bağlı olarak, performans iyileştirmeleri için bağlantı havuzunda daha fazla veya daha az bağlantı olmasını isterseniz.
- Uygulamanız Spring Boot yerine Spring Framework kullanıyorsa.
Merak etmeyin! DataSource, diğer bean'ler gibi Spring Context'i içine eklediğiniz bir bean'dir. Spring Boot'un sizin için implementasyonu seçmesine ve DataSource nesnesini yapılandırmasına izin vermek yerine, bir yapılandırma sınıfındaki @Bean anotasyonlu bir yöntem tanımlarsınız ve nesneyi context'e kendiniz eklersiniz. Bu şekilde, nesnenin oluşturulması üzerinde tam denetime sahip olursunuz.
Spring Boot'un DataSource instance'ını properties dosyasından oluşturmasına izin vermek yerine konfigürasyon sınıfımıza @Bean anotasyonlu bir metod tanımlayarak bu instance'ı kendimiz context'e ekleyeceğiz. Sonraki kod, yapılandırma sınıfını ve @Bean açıklamalı yöntemin tanımını gösterir.
@Configuration
public class ProjectConfig {
@Value("${custom.datasource.url}") ❶
private String datasourceUrl;
@Value("${custom.datasource.username}") ❶
private String datasourceUsername;
@Value("${custom.datasource.password}") ❶
private String datasourcePassword;
@Bean ❷
public DataSource dataSource() { ❸
HikariDataSource dataSource = ❹
new HikariDataSource();
dataSource.setJdbcUrl(datasourceUrl); ❺
dataSource.setUsername(datasourceUsername); ❺
dataSource.setPassword(datasourcePassword); ❺
dataSource.setConnectionTimeout(1000); ❻
return dataSource; ❼
}
}❶ Bağlantı ayarlarını yapılandırılabilir hale getirmek, bunları kaynak kodun dışında tanımlamaya devam etmek için iyi bir fikirdir. Bu örnekte, bunları "application.properties" dosyasında tutuyoruz.
❷ Spring'e döndürülen değeri context'ine eklemesini söylemek için metoda @Bean anotasyonu ekleriz.
❸ Metod bir DataSource nesnesi döndürür. Spring Boot, Spring Context'inde zaten bir DataSource varsa, bir DataSource daha yapılandırmaz.
❹ Bu örnek için data source implementasyonu olarak HikariCP'yi kullanacağız. Ancak, bean'i kendiniz tanımladığınızda, projeniz için gereken diğer konfigürasyonları da kendiniz yapılandırmalısınız.
❺ Veri kaynağındaki bağlantı parametrelerini ayarladık.
❻ Diğer özellikleri de yapılandırabilirsiniz (belirli koşullarda altında). Bu durumda, bağlantı zaman aşımını (veri kaynağının bir bağlantı alamamayı düşünmeden önce ne kadar süre beklediği) örnek olarak kullanıyorum.
❼ DataSource instance'ını döndürür ve Spring bunu context'ine ekler.
@Value anotasyonu kullanarak enjekte edeceğiniz özellikler için değerleri yapılandırmayı unutmayın. "application.properties" dosyasında bu özellikler bir sonraki kod snippet'i gibi görünmelidir. Bu isimleri seçtiğimizi ve Spring Boot özellikleri olmadığını vurgulamak için kasıtlı olarak adlarındaki "custom" kelimesini kullandım. Bu özelliklere herhangi bir ad verebilirsiniz:
custom.datasource.url=jdbc:mysql://localhost/spring_quickly?
useLegacyDatetimeCode=false&serverTimezone=UTC
custom.datasource.username=root
custom.datasource.password=Purchase tablosuna yeni bir kayıt eklemek için, bir sonraki snippet'te sunulduğu gibi HTTP POST ile /purchase endpoint'i çağırın:
curl -XPOST 'http://localhost:8080/purchase' \
-H 'Content-Type: application/json' \
-d '{
"product" : "Spring Security in Action",
"price" : 25.2
}'Daha sonra, uygulamanın purchase kaydını doğru şekilde depoladığını kanıtlamak için HTTP GET /product endpointi çağırabilirsiniz. Sonraki snippet, request için cURL komutunu gösterir:
curl 'http://localhost:8080/purchase'İsteğin HTTP response gövdesi, bir sonraki snippet'te sunulduğu gibi veritabanındaki tüm satın alma kayıtlarının bir listesini içerir:
[
{
"id": 1,
"product": "Spring Security in Action",
"price": 25.2
}
]4. Özet
- Java uygulaması için Java Development Kit (JDK), uygulamanın ilişkisel bir veritabanına bağlanması gereken nesnelerin soyutlamalarını sağlar. Uygulamanın her zaman bu soyutlamaların implementasyonlarını sağlayan bir runtime bağımlılığı eklemesi gerekir. Bu bağımlılığı JDBC driver olarak adlandırıyoruz.
- Veri kaynağı (data source), veritabanı sunucusuna bağlantıları yöneten bir nesnedir. Veri kaynağı olmadan, uygulama performansını etkileyerek çok sık bağlantı ister.
- Varsayılan olarak, Spring Boot, uygulamanızın veritabanına bağlantıyı kullanma biçimini en iyi duruma getirmek için bir bağlantı havuzu kullanan HikariCP adlı bir veri kaynağı uygulaması yapılandırır. Uygulamanıza yardımcı oluyorsa farklı bir veri kaynağı uygulaması kullanabilirsiniz.
- JdbcTemplate, JDBC kullanarak ilişkisel bir veritabanına erişmek için yazdığınız kodu basitleştiren bir Spring aracıdır. JdbcTemplate nesnesi, veritabanı sunucusuna bağlanmak için bir veri kaynağına bağlıdır.
- Tablodaki verileri değiştiren bir sorgu göndermek için JdbcTemplate nesnesinin update() metodunu kullanırsınız. Verileri almak üzere SELECT sorguları göndermek için JdbcTemplate'in query() metodlarından birini kullanırsınız. Kalıcı verileri değiştirmek veya almak için genellikle bu tür işlemleri kullanmanız gerekir.
- Spring Boot uygulamanızın kullandığı veri kaynağını özelleştirmek için java.sql.DataSource türünde özel bir bean yapılandırırsınız. Spring Context'inde bu tür bir bean bildirirseniz, Spring Boot varsayılan bir tane yapılandırmak yerine sizinkini kullanır. Özel bir JdbcTemplate nesnesine ihtiyacınız varsa aynı yaklaşımı kullanırsınız. Genellikle Spring Boot tarafından sağlanan varsayılanları kullanırız, ancak belirli durumlar bazen çeşitli iyileştirmeler için özel yapılandırmalara veya implementasyonlara ihtiyaç duyarız.
- Uygulamanızın birden çok veritabanına bağlanmasını istiyorsanız, her biri kendi JdbcTemplate nesnesiyle ilişkilendirilmiş birden çok veri kaynağı nesnesi oluşturabilirsiniz. Böyle bir senaryoda, uygulama context'teki aynı tipteki nesneleri ayırt etmek için @Qualifier anotasyonu kullanması gerekir.