Kubernetes Tuning 3: 50x Hatalarıyla Savaşmak
Kubernetes ve ALB ile yönettiğiniz uygulamalarınızda meydana gelen 502, 503 ve 504 hatalarını çözüyoruz.


Uzun, stresli ve baş ağrısı yapan bir sürecin daha sonuna gelmişken bu süre zarfında yaşadığım deneyimleri aktarmak istedim. Benzer hatalarla yüzleşen çok fazla kişi olduğunu düşündüğüm için de detaylı olarak senaryoları ve çözüm önerilerini bu yazıda ele alacağım.
Bu yazıda değineceğim 50x hataları; 502, 503 ve 504 olacak. Her birinin çalışan sisteme etkisi farklı olsa da zararlı oldukları su götürmez bir gerçek.
Hata kodlarına dair baktığım ilk kaynak AWS'nin kendi dökümanıydı fakat yeterince açık değildi. Bu sebeple her bir hata kodunu aynı senaryoları oluşturarak tek tek tespit ettim ve birazdan okuyacağınız methodları kullanarak çözdüm. Yine de aşağıdaki bağlantıdan sizde inceleyebilirsiniz.

Öncelikle kendi yaşadığım senaryolardan hangi hata kodu hangi durumda geliyor göz atalım ve aralarındaki farkları görelim. Hemen ardından da çözümlerini anlatalım.
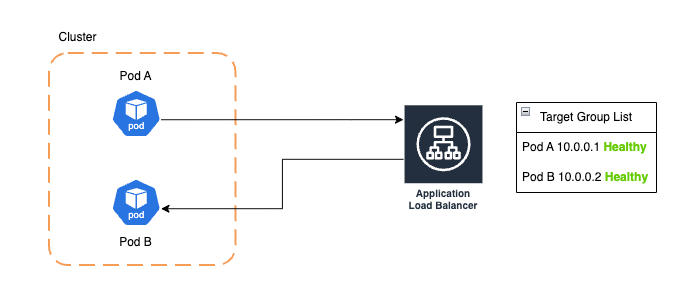
1. 502 Bad Gateway Hatası - Sebep
HTTP 502 hatası, en sık karşılaştığımız hata türüydü. Şimdi örnek bir senaryo üzerinden inceleyelim.
Pod Adaki uygulama,Pod Bdeki uygulamayla ALB üzerinden haberleşiyor. ALB, podların durumunu health check ile kontrol ediyor veHealthyişaretlenen podlara trafik akışına izin veriyor.
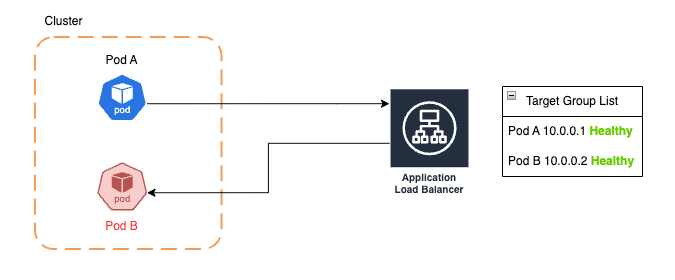
- Trafik akışı devam ederken herhangi bir sebeple
Pod B'nin kendisi veya içindekicontainererişilemez hale gelebilir. Bu sebepler şunlar olabilir:- Memory limiti aşılarak
OOMKilledmeydana gelebilir, - Container içinde çalışan app yanıt vermiyor hale gelebilir,
liveness probehata attığı için container restart edilmiş olabilir,- Pod isteyerek veya yanlışlıkla kill edilmiş olabilir,
- Yeni bir rolling update ile deployment güncelleniyor olabilir,
- Network problemleri sebebiyle pod ip adresi erişilemez hale gelebilir.
- Memory limiti aşılarak
Bunlar şimdiye kadar yaşadığım problemlerden aklıma gelenlerden. Özetle bunların benzeri birçok senaryoda uygulama erişilemez hale gelebilir.
Sorunda tam burada başlıyor. Pod B isteklere yanıt veremez hale geldi fakat ALB henüz health check periyodu gelmediği için veya ALB controller scrape zamanı gelmeden podun deregisteration işlemine başlayamadığı için podun halen sağlıklı ve ayakta olduğunu sanıyor ve istekleri yönlendirmeye devam ediyor. Sonuç olarak ise 502 hataları atılmaya başlanıyor.
Syn-ack şeması üzerinde de bu durumu kolaylıkla görebiliriz.
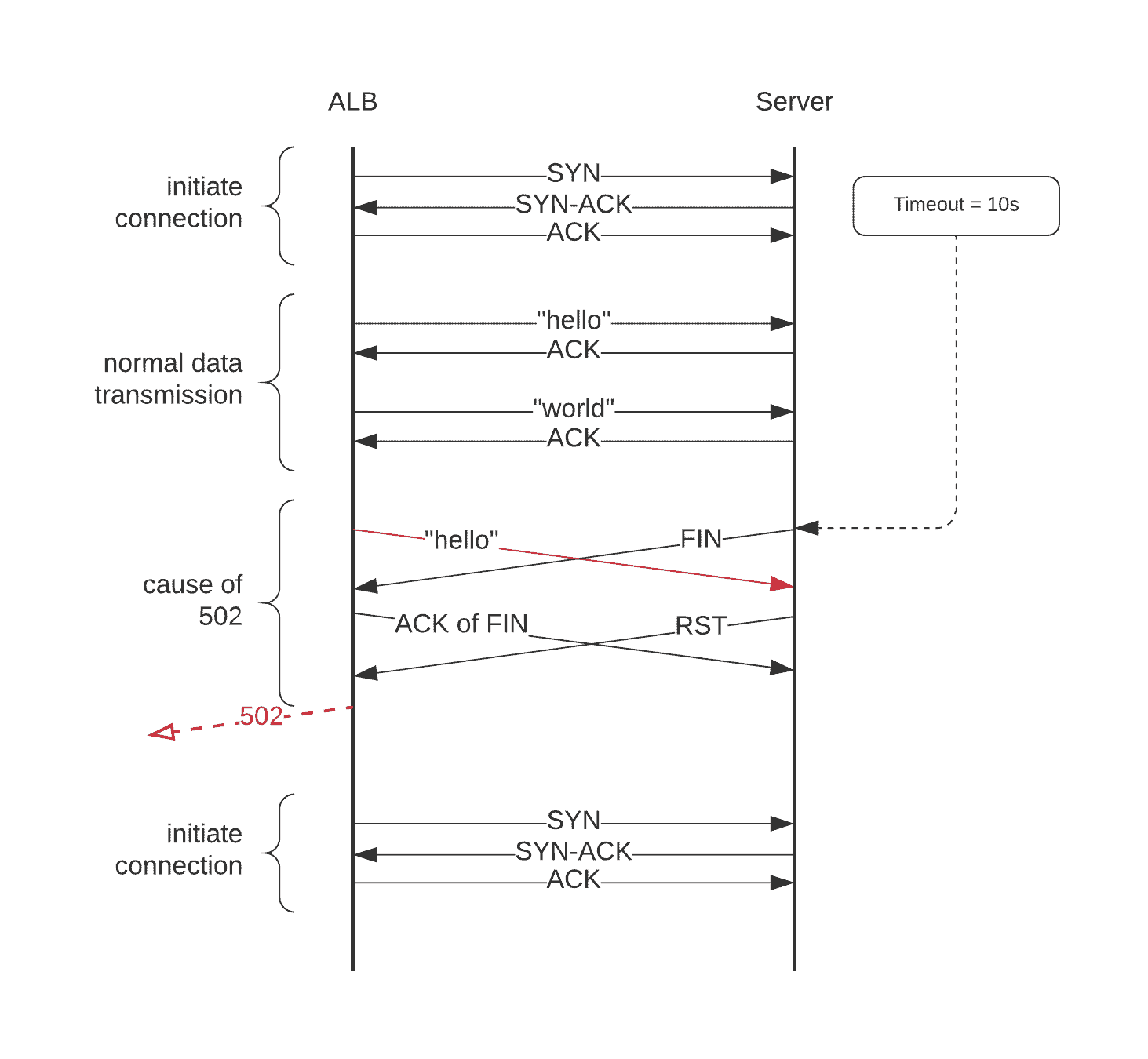
ALB bir servise bir istek gönderdiğinde, eğer aynı zamanda servis ALB soketine FIN segmenti göndermiş veya yukarıdaki senaryolardan biri yüzünden socket kapanmış olsun.
ALB soketi FIN'i alır, onaylar ve yeni bir el sıkışma prosedürü başlatır. Fakat bu esnada, servis tarafındaki socket, önceki (şimdi kapalı olan) bağlantıya ait olan bir isteği çoktan almıştır. Bunu işleyemediği için ALB'ye bir RST segmenti gönderir ve ardından ALB kullanıcıya bir 502 döndürür.
Benim en sık karşılaştığım senaryo ise OOM veya liveness probe'un success dönememesi sonucu pod içindeki container restart ediliyordu ve halen ALB bu pod ip adresine trafik yönlendirmeye devam ediyordu. Bu sebeplede bu podla haberleşen uygulamaların ilgili istekleri yoğun şekilde 502 hatası dönüyordu.
Ve büyük bir microservice mimarisinde tek bir pod bile binlerce requestin hata dönmesine sebep olabilir.

2. 502 Bad Gateway Hatası - Çözüm
Hatanın sebebini artık biliyoruz. Çözümü için ise uyguladığım ve işe yarayan yöntemleri listeliyorum:
2.1. Health check sürelerinin doğru ayarlanması
Bir pod artık yanıt veremez bir hale geldiğinde bunu hızlıca farkedip ilgili podu Unhealthy işaretlemeniz gerekir. Çok uzun scrape süreleri geç kalmanıza sebep olur. Bu yüzden ilk olarak health check ayarlarını gözden geçirmelisiniz.

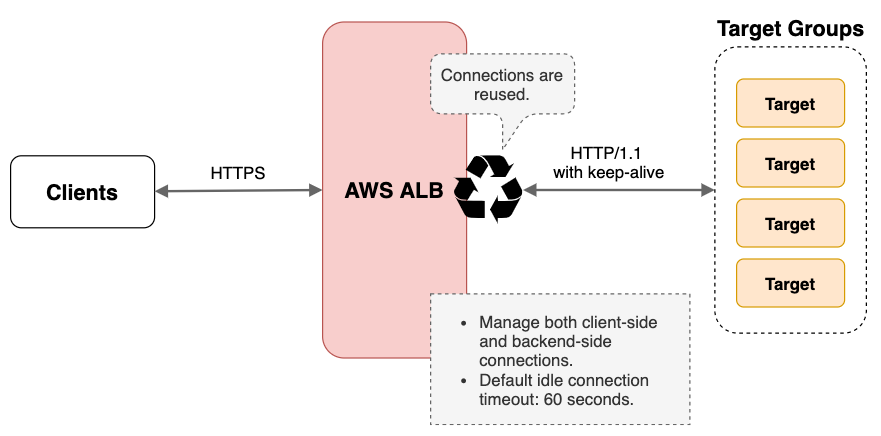
2.2. Connection idle timeout süresinin doğru ayarlanması
Connection idle timeout, ALB'nin bir bağlantıyı kapatmadan önce mevcut bir istemci veya hedef bağlantının veri gönderilmeden veya alınmadan ne kadar süre geçmesi gerektiğini belirtir.
Yani, eğer ALB bu süre içerisinde aktif bir trafik almazsa ilgili bağlantıyı kapatır. Peki sorun nerede?
Uygulamaların varsayılan keep-alive süreleri eğer siz özelleştirmediyseniz 60s dir. Örneğin Tomcat connectionTimeout değerine bakabilirsiniz.
Böyle bir yapılandırma da eğer ALB nin connection idle timeout değeri 60s den büyük olursa, uygulamanız bağlantıyı kapattığında, ALB halen trafik yönlendirmeye devam ediyor olacak ve hedefte uygulama olmadığı için 502 alacaksınız.
Çözüm için ALB nin connection idle timeout değerini uygulamanızın keep-alive timeout değerinden mutlaka küçük yapmalısınız!
Fakat connection idle timeout değerinin desteklediği en küçük değer 60s'dir. Bu sebeple eğer uygulamanızda default keep-alive süresini kullanıyorsanız bu süreyi artırmanız gerekiyor.
Örneğin bir uygulamamızda keep-alive süresini 180s ayarladığımız için bu uygulamaya trafik yönlendiren ALB nin değerini 150s olarak ayarladık.
server.jetty.connection-idle-timeout=180s
Detayları için AWS dökümanını da okumanızı tavsiye ederim.
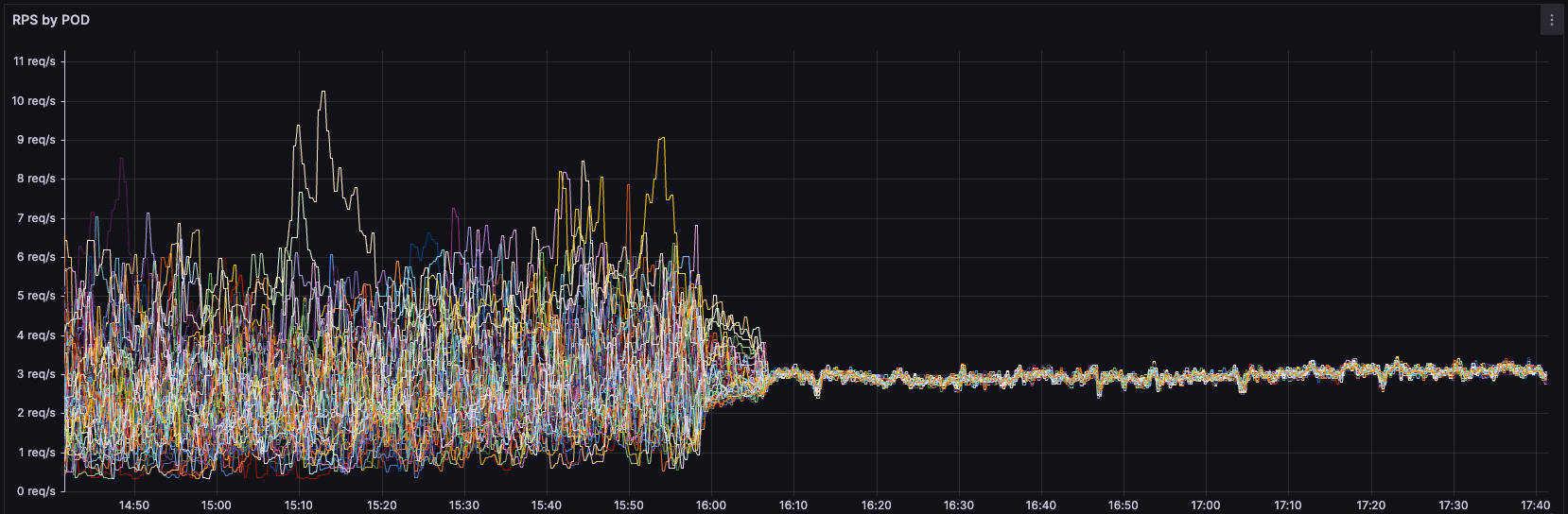
Ayrıca, aynı çalışmayı yaparak tıpkı bizim grafiklerdeki gibi 502 hatalarını elimine eden başka üç çalışmayı da aşağıdaki bağlantılardan okuyabilirsiniz.

2.3. Container Lifecycle'ına PreStop Hook Eklenmesi
Bu yöntem kulağa çirkin geliyor ama birazdan ne kadar önemli ve hayat kurtarıcı olduğunu göreceksiniz. Hadi başlayalım.
İlk bahsettiğim hata senaryolarının dışında, en basitinden;
- bir deployment'ın image'ini güncellediğinizde ve rolling update'i (veya recreate'i vs) tetiklediğinizde
- scaling mekanizması replica sayısını düşürdüğünde
- bir pod kill edildiğinde
502 hatasıyla karşılaşmanız çok olası. Şaşırtıcı gelebilir ama bunun sebebi, bir podun create edildiği lifecycle ile termination lifecycle periyodunun farklı olmasıdır.
Pod create edildiğinde tüm işlemler sıralı olarak şu şekilde yürür:
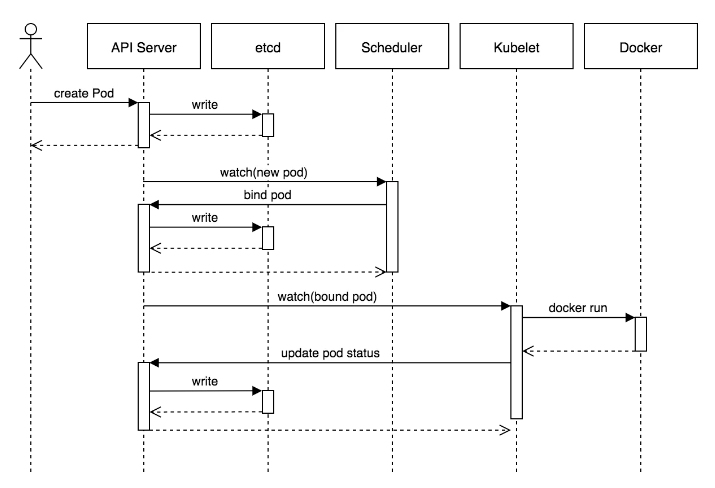
- İlk olarak istemci tarafından atılan istek
API Server'a düşer API Server, Pod nesnesinietcddb'e yazar. Yazma işlemi başarılı olduğunda,API Serverve istemciye bir onay gönderilir.API Serverartıketcddurumundaki değişikliği izler ve istemciye yansıtır.- Bu durumda,
kube-scheduler,API serverda yeni bir Pod nesnesinin oluşturulduğunu ancak herhangi bir node'a bağlı olmadığını görür. kube-scheduler, pod'a bir node atar veAPI Server'ı günceller.- Bu değişiklik daha sonra
etcddb sindeki durumu günceller.API Server'da bu node atamasınıPodnesnesine yansıtır. - Her node üzerindeki
Kubelet,API Server'ı izlemeye devam eden izleyicileri de çalıştırır. Hedef node'dakiKubelet, kendisine yeni birPodatandığını görür. Kubelet, Docker'ı çağırarakPod'u kendi node'unda başlatır ve container durumunuAPI Server'a geri günceller.API Serverpod durumunuetcd'de kalıcı hale getirir.
Akışta gördüğünüz üzere tüm işlemler sırayla ilerliyor. Fakat şimdi termination lifecycle'a baktığımızda göreceksiniz ki işlemler sıralı değil, paralel ilerliyor olacak.
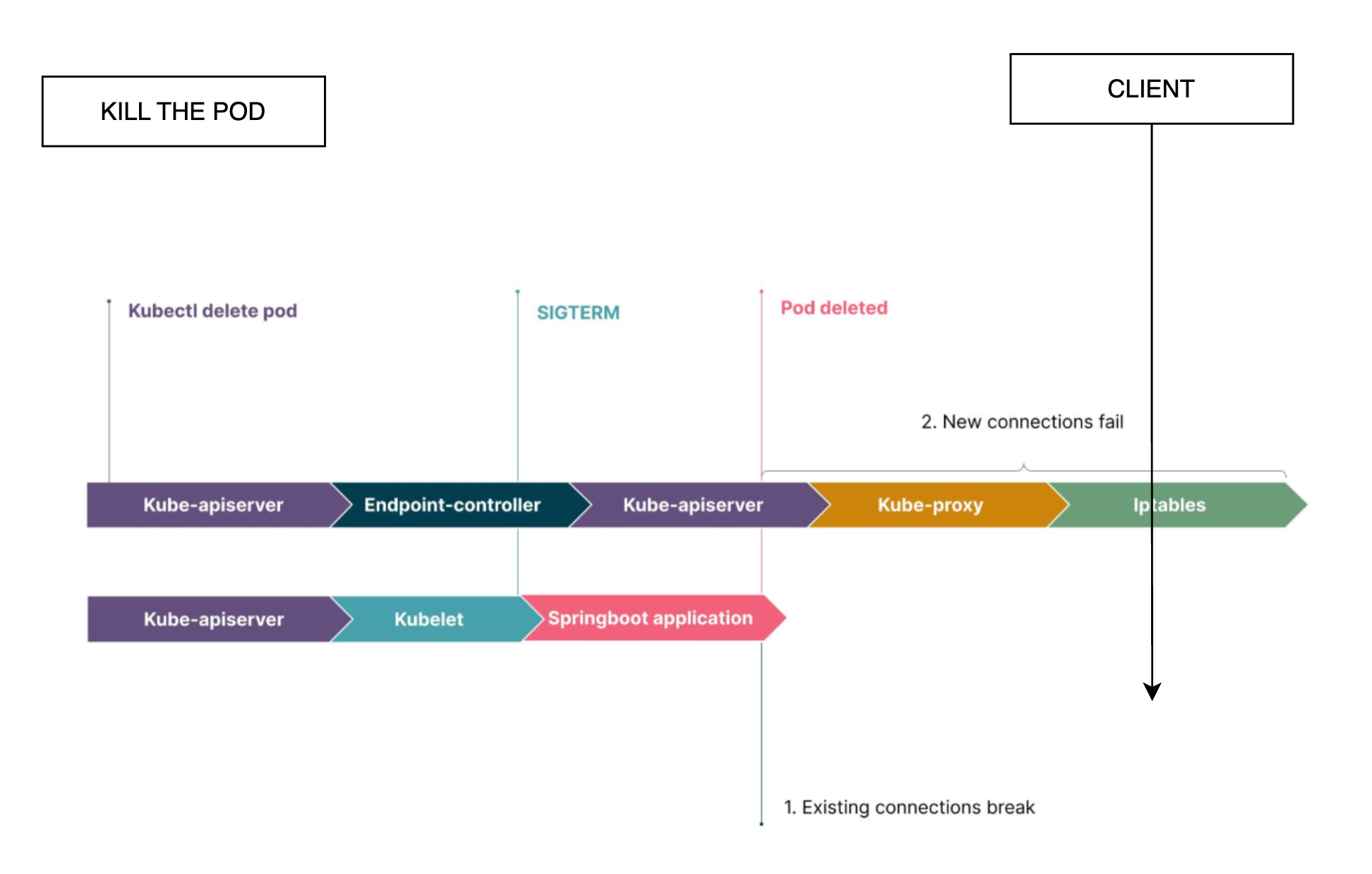
Yukarıdaki şemada gösterildiği üzere, bir pod termination sürecine girdiğinde, işlemler temel olarak iki paralel kanaldan aynı anda başlar:
1- Bir podun silinmesi:
API Server, pod termination isteğini alır ve podun durumunuEtcd'de Terminating olarak günceller,Kubeletnode üzerindeki depolama, ağ gibi container ile ilgili kaynakları temizler;Kubeletcontainer'a SIGTERM gönderir. Böylece container içindeki işlem için herhangi bir yapılandırma yoksa, container hemen sonlanır. Container varsayılan 30 saniye (terminationGracePeriodSeconds) içinde çıkamadıysa,KubeletSIGKILL gönderir ve container'ı zorla sonlandırır.
2- Ağ kurallarının temizlenmesi:
API Server, pod termination isteğini alır ve podun durumunuEtcd'de Terminating olarak günceller,Endpoint Controller, podun IP'siniEndpointnesnesinden silerKube-proxy, iptables kurallarınıEndpointnesnesindeki değişikliğe göre günceller ve artık trafiği silinen poda yönlendirmez.
Bu süreci Kubernetes dökümanından detaylı okumak için aşağıdaki bağlantıyı kullanabilirsiniz:

Peki burada sorun nerede?
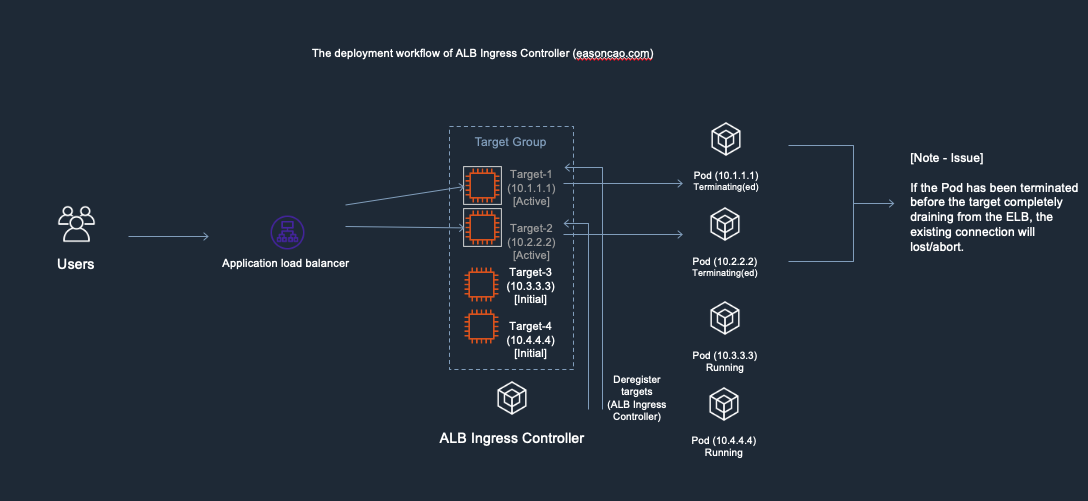
Aslında şema üzerinde çok net görünse de, bu iki paralel işlemden birincisi, yani podun sillinme işlemi daha erken bittiğinde, henüz iptables üzerinde podun ip adresi yer aldığı için trafik bu poda yönlendirilmeye devam edilecek. Fakat pod çoktan silindi ve bu sebeple 502 hatası fırlatılacak.
Benim senaryomda, bu iki paralel kanala ek olarak ALB Controller'ın pod'un silindiğini farketmesi ile ilgili ALB nin target grubundan pod ip adresini çıkarması süreci de mevcut.
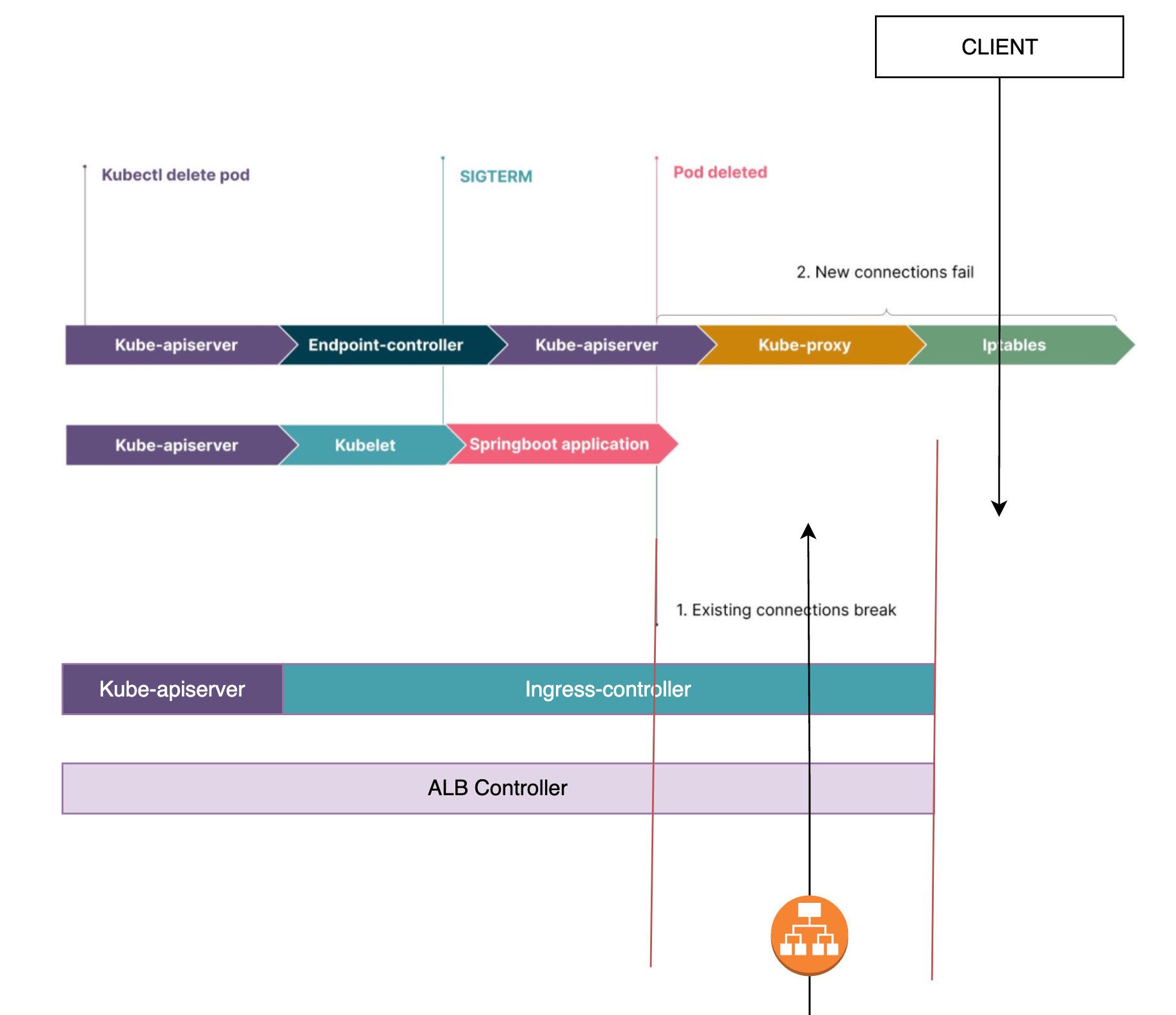
Çözüme geçmeden önce işin temelindeki sorunu net bir şekilde anladığımızı düşünüyorum. Artık preStop hook'un sorunumuzu nasıl çözeceğine bakalım.
İlk olarak normal Service nesnesinin, yani Görsel-8 deki senaryonun çözümü için container'ın lifecycle'ına preStop hook ekliyoruz.
lifecycle:
preStop:
exec:
command: ["sh", "-c", "sleep 10"]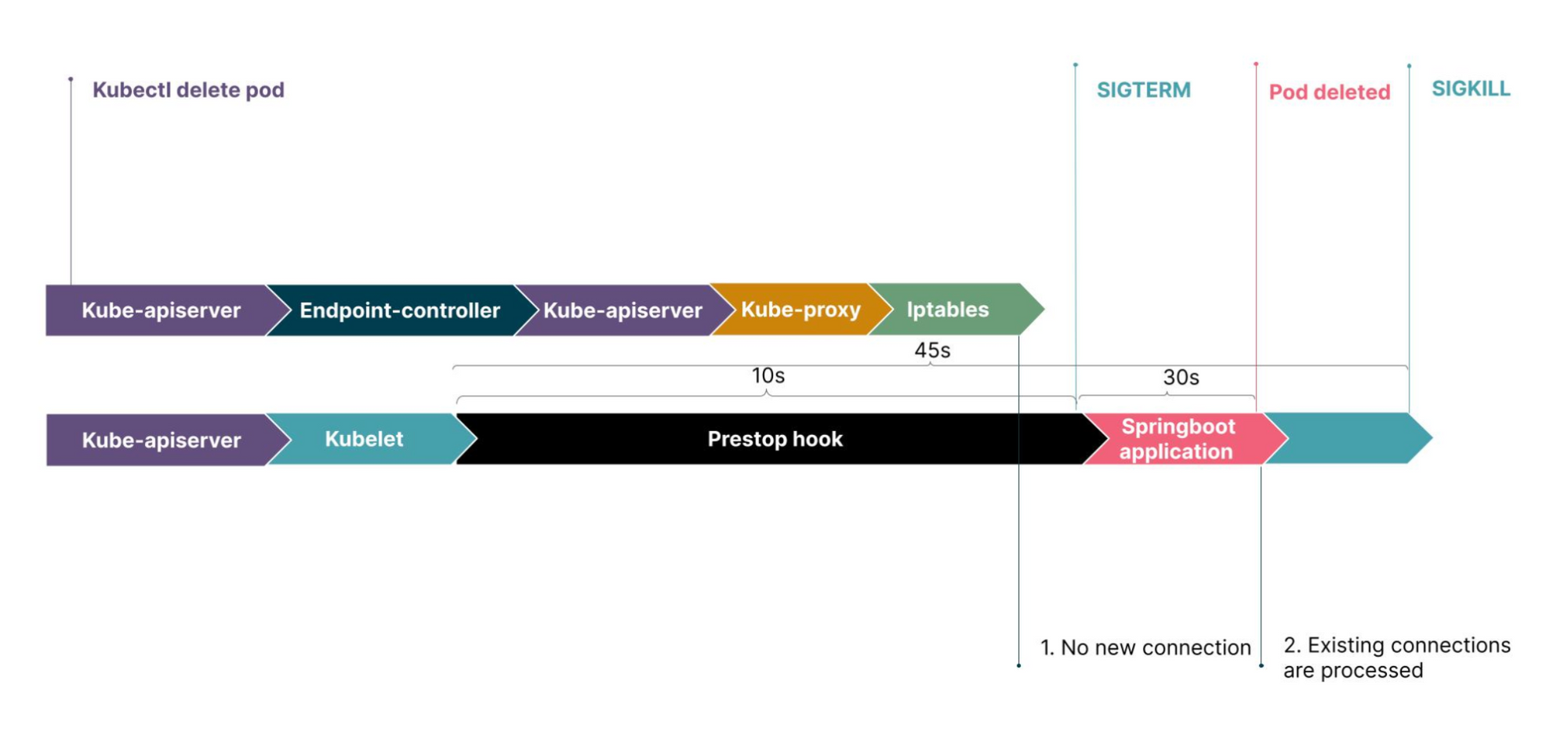
Artık bir pod termination isteği aldığında, ilk olarak preStop hook'taki komutu çalıştıracak ve ardından SIGTERM gönderecek. Bu komutu da basit olarak sleep komutu olarak ayarladığımızda, pod'umuz silinmeden önce belirttiğimiz süre kadar bekliyor olacak. Bu sırada ise diğer paralelde ilerleyen işlemler için bir müddet süre tanımış olacağız.
Bu süreyi cluster'ınızın büyüklüğüne, uygulamada yürütülen işlemlerin aldığı süreye göre kendiniz belirlemelisiniz. Fakat 10sn bir çok cluster için geçerli bir çözüm olacaktır. Tabi bizi anca 25sn kesti :)
terminationGracePeriodSeconds süresi, preStop süresini kapsar. Yani terminationGracePeriodSeconds süresini45sn, preStop süresini 10sn ayarladığınız bir örnekte SIGTERM sinyali 10. saniyede, SIGKILL sinyali 45. saniyede gönderilecek. İşlemleriniz gracefull bir şekilde kapatılması için ise 30 saniyeniz kalmış olacak.timeout-per-shutdown-phase parametresini ekleyerek aynı stratejiyi uygulayabilirsiniz.server:
shutdown: graceful
spring:
lifecycle:
timeout-per-shutdown-phase: 30sYukarıdaki yapılandırmayı kullanarak Spring Boot, SIGTERM aldıktan sonra artık yeni istek kabul etmeyeceğini ve zaman aşımı içinde devam eden tüm istekleri işlemeyi bitireceğini garanti eder. Zamanında bitiremese bile, ilgili bilgiler yine de loga kaydedilecek ve ardından çıkmaya zorlanacaktır.
preStop kullandığınızda, terminationGracePeriodSeconds süresini sleep ile belirlediğiniz süreden daha uzun tutunuz. Aksi halde SIGTERM ve SIGKILL aynı anda atılacak ve istekler graceful bir şekil yerine zorla sonlandırılmış olacak. Örneğin preStop 30sn, terminationGracePeriodSeconds 45sn kullanabilirsiniz.3. 503 Service Unavailable Hatası - Sebep
İkinci can sıkıcı hatamız olan 503 hatası, açıklamasından da belli olduğu üzere, trafiğin yönlendirileceği hedefler bulunamadığı zaman meydana geliyor. Yine kendi yaşadığım senaryolardan bazıları şunlar:
- ALB'de yanlış ayarlanan bir health check yüzünden tüm target'lar
Unhealthydurumunda olabilir,
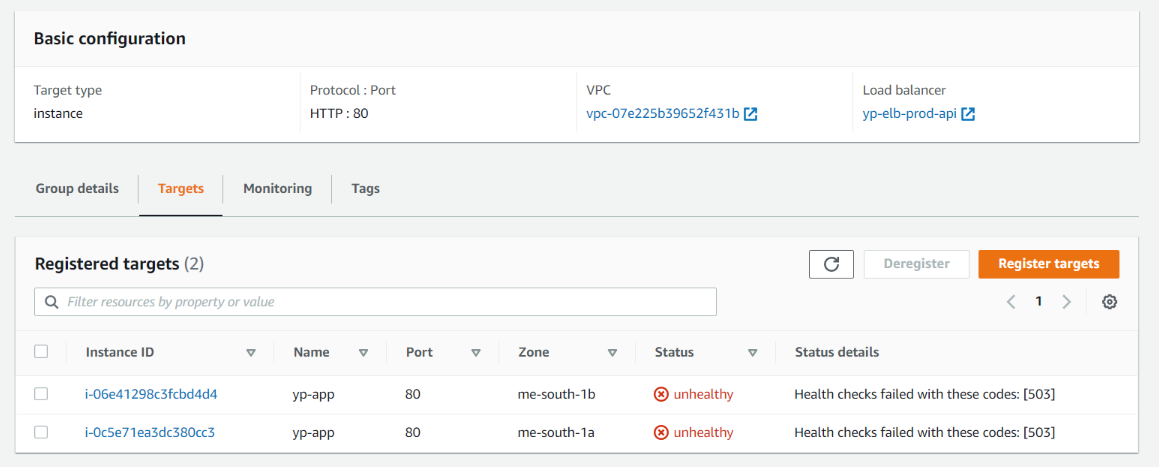
- Bir deployment'ın tüm podları aynı node üzerindeyken, bu node drain edildiğinde yine hiç
Healthydurumunda target olmayabilir. Yani yine üstteki maddede yer alan durum oluşuyor.
En bariz ve yaşadığım senaryolar bunlardı. Şimdi her birini teker teker çözelim.
4. 503 Service Unavailable Hatası - Çözüm
503 Service Unavailable hatasını çözebilmek için aşağıdaki alt başlıkları teker teker uygulayacağız.
4.1. Health check ayarlarının eklenmesi/düzeltilmesi
Bu ilk ve en basit olanı. Üstelik en bariz görünen hata ve çözümde yine burada. Uygulamanıza doğru bir readiness ve liveness probe eklemelisiniz ve Target Group içinde Healthy duruma geçtiğini gözlemlemelisiniz. Ardından 503 lerin çözüldüğünü göreceksiniz.
4.2. Podlar için PodDisruptionBudget ayarlanması
PodDisruptionBudget, Kubernetes v1.21 ile hayatımıza giren mükemmel yeteneklerden birisi. Cluster'ınızda High Availability sağlayabilmeniz için inanılmaz derecede işe yarıyor fakat ne yazık ki daha çoğu kişi tarafından bilinmiyor :(
PodDisruptionBudget, kısaca PDB, gönüllü eylemler (örneğin scaling down) veya gönülsüz eylemlerin (node arızaları gibi) neden olduğu bir kesinti sırasında kullanılabilir kalması gereken minimum pod sayısını belirten bir Kubernetes nesnesidir.
503 sebeplerinde söylediğim son seçenekte olduğu gibi, örneğin bir spot makine kapandığında veya bir node hata verip NotReady durumuna düştüğünde üzerinde bulunan tüm podlar drain edilir. Ve bir uygulamanın tüm podları bu node üzerindeyse, yeni podlar Healthy durumuna gelene kadar target group içinde Healthy target kalmadığı için 503 hatası alırsınız.
Bu bir rolling update vs olmadığı için maxSurge ve maxUnavailable gibi ayarlarınız işe yaramaz! Fakat PDB işe yarar!
Örneğin deployment'ınız için aşağıdaki yapılandırmada olduğu gibi bir PDB ayarladığınızda, node drain edilse bile belirlediğiniz oran kadar pod available kalacak şekilde drainin akışı K8S tarafından kontrol edilir.
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: test-app
spec:
minAvailable: 30%
selector:
matchLabels:
app: testHer zaman en az %30 kadar pod olduğu için 503 hatalarına elveda diyebiliyoruz :)
Ekstra olarak, bir uygulamanın tüm podlarını aynı node üzerine denk gelmesini podAntiAffinity veya PodSpreadTopology kullanarakta önleyebilirsiniz. Tabi eğer preferredDuringSchedulingIgnoredDuringExecution kullanırsanız bunu garanti edemezsiniz. Bu konuyla alakalı güzel bir blog yazısını aşağıya ekliyorum.
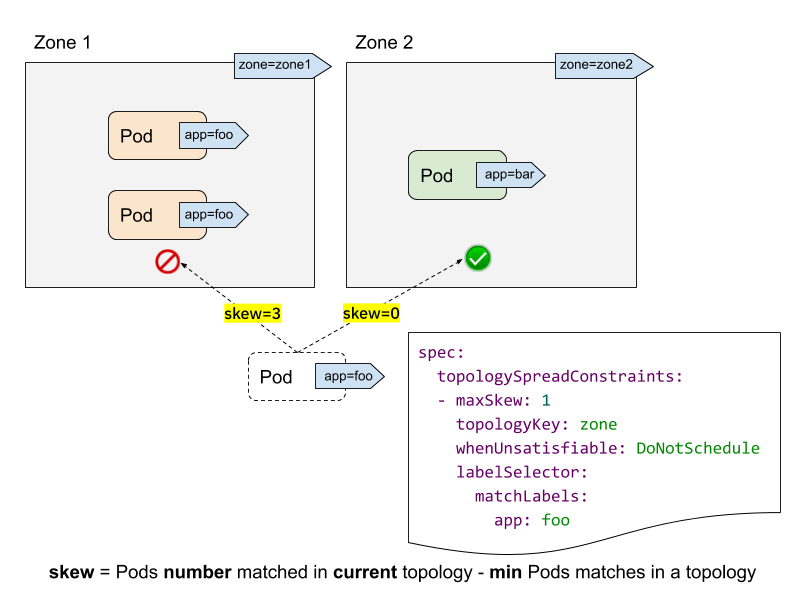
5. 504 Service Unavailable Hatası - Sebep
Son hatamız olan 504 Service Unavailable hatasıyla ise şu senaryolarda karşılaştım:
- Bir deployment, rolling update veya recreate ile güncellenirken, ALB'nin ilgili target group'unda hiç
Healthydurumda target bulunmayabilir. Bu 503 ile karıştırılabilir fakat 503 hatasında hepsiUnhealthydurumundaydı. Burada ise targetlar var fakat tarfiği karşılamaya hazır değiller. Böylece connection timeout süresi içinde (default 10sn) target'la bağlantı kuramaz ve 504 atar.
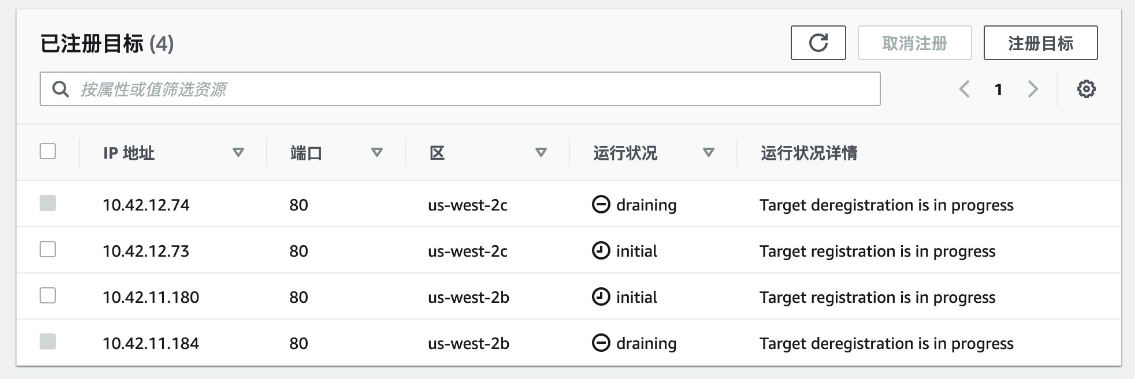
- Trafik bir poda yönlendirildikten sonra, henüz response dönmemişken, podun üzerinde olduğu node'un spot olması veya hata atması sebebiyle kapanması ve idle timeout süresi içinde response'un dönülememiş olması.
6. 504 Service Unavailable Hatası - Çözüm
Son hatamız olan 504 Service Unavailable hatasını çözmek için ise iki adım yeterli olacak. Hemen bakalım.
6.1. Pod Readiness Gate Özelliğinin Aktif Edilmesi
Load Balancer Controller kullananlar için bu özellik çok kritik. Neden mi?
Bir deployment'ın versiyonunu güncelleyerek rolling update veya recreate başlattığınızı düşünün. Veya spot makine kullandığınızda
Önce max surge kadar yeni pod geldi ve readiness probe'u geçerek Ready duruma geldi diyelim. Ardından eski podlar terminate edildi. Her ne kadar yeni podlar Ready görünsede ALB controller henüz bu podları target group'a ekleyememiş veya eklese bile halen Initial durumda kalmış olabilir. Tabi terminate edilen targetlarda bu sırada Draining durumunda.
502 preStop hook başlığında konuştuğumuz paralelde ilerleyen işlerin açtığı başka bir sorunda tam olarak bu.
Bu sorunu çözebilmek için Load Balancer Controller'ın Pod Readiness Gate özelliğini aktif hale getireceğiz. Aktif hale getirilmesi inanılmaz kolay, dökümana bakarak 5dk içerisinde halledebilirsiniz.
Artık yeni podlar oluşturulduğunda readiness probe'ları geçse bile Ready işaretlenmeyecek.

status:
conditions:
- lastProbeTime: null
lastTransitionTime: "2024-08-02T12:08:28Z"
message: corresponding condition of pod readiness gate "target-health.elbv2.k8s.aws/k8s-stage-xxxx-2060670e5b"
does not exist.
reason: ReadinessGatesNotReady
status: "False"
type: ReadyNe zamanki, ilgili target group içerisinde Healthy duruma geçerse, Pod Readiness Gate'in koyduğu condition'da ilgili poddan kaldırılacak ve pod Ready hale geldiği için trafik yönlendirilmeye başlanacak.
Böylece deploymentlarınızda bir daha 504 le karşılaşmamış olacaksınız. Aynı sorunu yaşayan Çinli bir arkadaşın yazısıda bu senaryoyu detaylı açıklıyor. Aşağıdaki bağlantıdan inceleyebilirsiniz.

6.2. Node Termination Handler ile nodeların graceful kapatılması
Maaliyetleri azaltabilmek adına spot makine kullananların karşılaştığı sorunlardan birisi de 504 hatalarıdır. Çünkü Spot makineler, AWS'nin dilediği bir anda 2dk içinde kapanıyor. Hatta daha az sürede bile kapandığı oluyor. Bununla alakalı açtığım bir issue bile var. Bu sebeple tüm podlar bir anda terminate ediliyor ve o sırada pod üzerinde olan requestler response dönemiyor. Böylece de 504 hataları atılıyor.
Bu sorunu çözmek için bir node'a termination sinyali geldiğince öncelikle üzerindeki podları graceful bir şekilde drain etmeliyiz ve ardından node'un kapanmasına geçmeliyiz.
Bu sinyali yakalayıp node'u graceful bir şekilde drain edebilmek için ise Node Termination Handler projesini Queue Processor modunda kullanıyoruz.
 aws
aws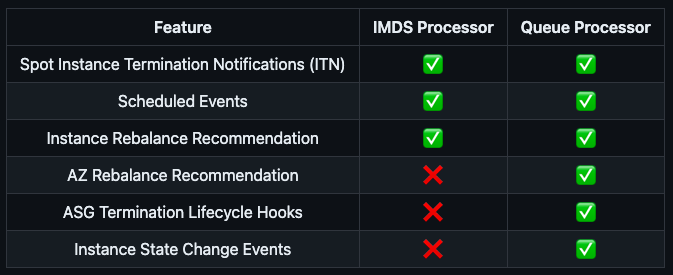
Tabloda gördüğünüz gibi, Queue processor, ASG Termination Lifecycle Hooks desteği ile bir node'a termination sinyali geldiğinde onu yakalar ve ilgili node'u drain eder.
Böylece o anki requestler tamamlanarak yeni trafik kabul edilmez ve response dönemeyen istekler kalmadığı için 504 hataları çözülmüş olur.
Örnek bir NTH loguna bakalım:
2024/04/30 20:43:53 INF Requesting instance drain event-id=asg-lifecycle-term-xx instance-id=i-xx kind=ASG_LAUNCH_LIFECYCLE node-name=ip-192-168-xx-xx.eu-west-1.compute.internal provider-id=aws:///eu-west-1a/i-xx
2024/04/30 20:43:58 INF Pods on node node_name=ip-192-168-xx-x.eu-west-1.compute.internal pod_names=["xx","yy", "zz"]
2024/04/30 20:43:58 INF Draining the node
2024/04/30 20:43:58 ??? WARNING: ignoring DaemonSet-managed Pods: xx, yy, zz
2024/04/30 20:43:58 ??? evicting pod xx
2024/04/30 20:43:58 ??? evicting pod yy
2024/04/30 20:43:58 ??? evicting pod zz
2024/04/30 20:44:32 INF Node successfully cordoned and drained node_name=ip-192-168-xx-xx.eu-west-1.compute.internal reason="ASG Lifecycle Termination event received. Instance will be interrupted at 2024-04-30 20:43:57.49 +0000 UTC \n"Entegre etmesi ise yine çok kolay. Helm ve bir adet SQS ile tüm kurulumu yapmanız oldukça kısa sürecek. Ardından 504 hatalarına elveda diyeceksiniz.
7. Özet
Çok can sıkıcı hale gelen 502, 503 ve 504 hatalarını yukarıdaki yöntemleri tek tek deneyerek ve gözlemleyerek çözdük. Fakat yinede arada bir 502 hatalarına denk geliyoruz. Peki neden?
Bizler her ne kadar sistemi bu çalışmalarla stabil hale getirmeye çalışsakta uygulamanın kendisinin doğru optimize edilememesi, yanlış kaynak kullanımları, memory leakler, hataların doğru handle edilememesi gibi sebepler yüzünden bir uygulama t anında birden kapanabiliyor veya yanıt veremez hale geliyor. Bu sebeple de aktif istekler hata kodları fırlatıyor.
Yine de bu çalışmalarla 50x hatalarının %95 kadarını çözdük. Geri kalan kısımlar için ise developer arkadaşların uygulamalarını optimize etmeleri gerekecek.
Sizinde bu süreç ile alakalı soruları veya önerileri varsa yorum alanına yazabilirsiniz. Bir sonraki tuning çalışmasında görüşmek üzere..



