Kubernetes Tuning 1: Service Nesnesini Devreden Çıkararak RPS'i Nasıl %80 Düşürdük?
Kubernetes Tuning serisinin ilk yazısı olan Service nesnelerini devreden çıkararak nasıl RPS değerlerini önemli ölçüde düşürdüğümüzü anlatıyorum.

Kubernetes Service nesnesi, ortada birden fazla pod olduğunda onlarla iletişime geçebilmemiz için bize tek bir giriş noktası vererek işleri kolaylaştırır. Peki trafiği podlara eşit dağıtma konusunda gerçekten de verimli çalışıyor mu? Hadi detaylıca inceleyelim.
Service nesneleri, aynı hizmeti sağlayan bir pod grubuna tek ve sabit bir giriş noktası oluşturur. Böylece bir frontend uygulaması, iletişime geçeceği pod ip adreslerinin ne olduğunu bilmesine gerek kalmadan sadece tek bir ip ve port adresi ile yüzlerce dinamik pod havuzuna rahatlıkla erişim sağlayabilir.
Service nesnesi için detaylı yazıma aşağıdaki bağlantıdan ulaşabilirsiniz.

Service nesnesinin aslında fiziksel bir karşılığı yoktur. Clusterınızda yer alan nodelar üzerinde netstat -ntlp komutu çalıştırdığınızda service nesnelerinin sahip olduğu ip ve portları göremediğinizi farkedeceksiniz. Öyleyse trafik nasıl akmaya devam ediyor?
Tam burada devreye kube-proxy girer. Service ip adresleri, cluster veritabanında depolanır (default etcd veya farklı bir db) ve kube-proxy tarafından düzenli olarak okunarak iptables rewrite kuralları oluşturulur. Böylece ilgili service ip adresine denk gelen bir istek geldiğinde, bu istek iptables kurallarına göre hedeflere yani podlara yönlendirilir.
Iptables'in nasıl çalıştığına dair zevkli bir yazıya şu bağlantıdan ulaşabilirsiniz.

Artık sorunlu kısıma yavaş yavaş gelelim. Kube-proxy'nin modlarından biri olan ve default gelen iptables, round robin algoritmasını içermez çünkü load balancing için değil, firewall'lar için tasarlanmıştır. Fakat yukarıdaki yazıyı okuduysanız, statistic modülünün random veya nth modlarıyla birlikte load balancing yeteneği iptables'a kazandırılır.
Öyleyse sorun ortadan kalktı mı? Hayır.
Kube-proxy, O(n) complexity ile iptables tablosunu düzenler. Bu sebeple service ve bu service nesnelerinin yönlendireceği pod sayısı arttıkça, iptables tablosunun işlenmesi de uzun zaman almaya başlayacaktır. İlk performans sorunları da burada kendini göstermeye başlar.
Bu sorunu Kube-proxy modlarından O(1) complexity'e sahip olan ve doğal olarak round robin ve daha bir çok load balancing algoritmasına sahip olan IPVS modu ile çözebiliyoruz.
IPVS, direkt olarak load balancing için tasarlanmıştır ve Kubernetes'in kendi dökümanında da net olarak söylediği gibi daha düşük bir latency ve yönlendirme kurallarında daha performanslı sonuçlar sağlar.
Özetle kube-proxy modunuzu değiştirerek aşağıdaki bağlantıda yer alan sonuçlardaki gibi bir performans artışı yaşayabilirsiniz.

Öyleyse sorun ortadan kalktı mı? Yine Hayır.
Sahi, sorun neydi ki?
Artık sorunun kendisini tanımlayalım. Kubernetes Service nesnesini kullanarak ve kube-proxy'nin modlarından yararlanarak bir load balancing yapmaya çalıştığımızda, eğer HTTP keep-alive aktif olan uygulamalarınız varsa load balancing tamamen anlamını yitirir hale geliyor.
Frontend uygulamanız, bir backend uygulamasına HTTP istek attığında, yeni bir TCP bağlantısı açılır ve istek sonunda kapanır. Her istekte bu açma kapama işlemi tekrarlandığı için latency süresi de doğal olarak artar.
Her HTTP isteğinde bir TCP bağlantısı açmak yerine eski bağlantıyı kapatmayıp belirlediğimiz süre boyunca aynı bağlantıyı kullanarak bu latency süresini azaltırız. Ve neredeyse herkes iyi bir çözüm olduğu için bunu yapabilmeyi sağlayan HTTP keep-alive yeteneğini uygulamalarında kullanır. Bu gerçekten iyi bir çözümdür ve latency süresini önemli ölçüde azaltır.

Tabi çok ciddi bir sorunu da beraberinde getirir. Uygulamalarınız keep-alive kullanarak TCP bağlantısını sonlandırmadığı sürece aynı kaynaktan gelen tüm istekler aynı poda düşmeye devam eder!

Iptables veya IPVS hangi modu kullanırsanız kullanın, halen açık bir TCP bağlantınız olduğu için hedef seçme kuralları tekrar işletilmez ve trafik TCP bağlantısı kapanana kadar aynı pod üzerinden akmaya devam eder. Bu şekilde latency süresini düşüreyim derken scability yeteneğinizi kaybetmiş olursunuz. Hatta tüm istekler aynı poda geldiği için yoğun trafik altında podun kaynak yetersizliği yüzünden azalttığınız latency süresinin çok daha fazlasıyla yüz yüze bile gelebilirsiniz. Nerede kaldı load balancing :)
Peki bunu nasıl çözebiliriz?
- HTTP keep-alive özelliğini kapatabilir ve böylece her istekte kuralların işletilerek yeni bir hedef pod seçilmesi sağlanabilir. Tabi latency süreniz tekrar uzar. Kulağa hoş bir yöntem gibi gelmiyor.
- Kubernetes API aracılığıyla ilgili Service nesnesine sorularak endpointlerinin (yani hedef pod adresleri, bakınız daha önce anlattım) listesi uygulamanın içinden elde edilir ve service adresi yerine bu hedefler arasından her istekte yeni bir tanesi seçilerek istekler atılır. Tabi bu bir nevi load balancing işini kendinizin yapması demek (client-side load balancing) ve böyle bir iş yüküne değer mi? Hiç sanmıyorum. Ayrıca sadece HTTP değil, gRPC, RSockets vs birçok haberleşme protokolü var. Hangi birini implement edeceksiniz?
- Bir önceki maddede bahsettiğim implementasyonları yapan ve başarılı şekilde çalışan Istio, Linkerd, Traefik meshing gibi birçok meshing projesi var. Fakat zaten HPA, VPA, Karpenter vs gibi birçoğuyla boğuşurken sistemi daha karmaşık hale getirmek ve ekstra onların sorunlarıyla ve optimizasyonlarıyla uğraşmak ne kadar efektif bir çözüm sayılabilir? Bu maddede duraktan inenler olabilir ama ben basitlikten yanayım ve devam ediyorum.
- Hadi Service nesnesini aradan çıkaralım 👹
Service Nesnesini Aradan Çıkarmak
Kubernetes Service nesnesini iki senaryo için çokça kullanıyoruz. Bu senaryoları detaylı inceleyip performanslarını artıralım.
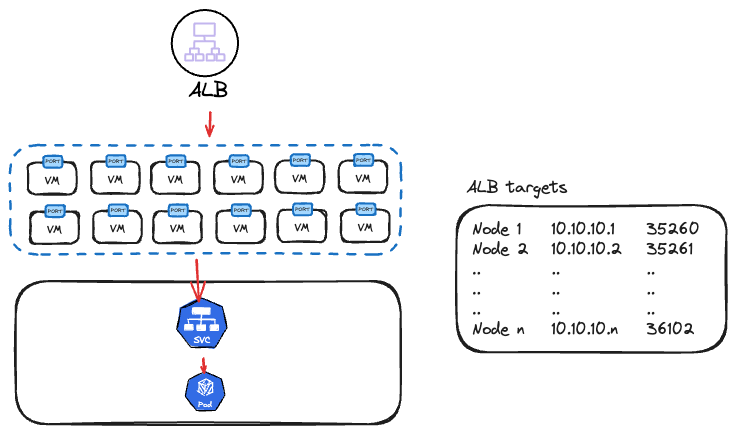
1. ALB üzerinden gelen trafiği Nodeport ile yönlendirmek (!)
Cluster dışından frontend uygulamamıza erişmek istediğimizde ve bu uygulama birden fazla pod üzerinde çalıştığında Service nesnemizin tipini genelde Nodeport verip node ip adresleri üzerinden onlara erişmeye çalışırız.
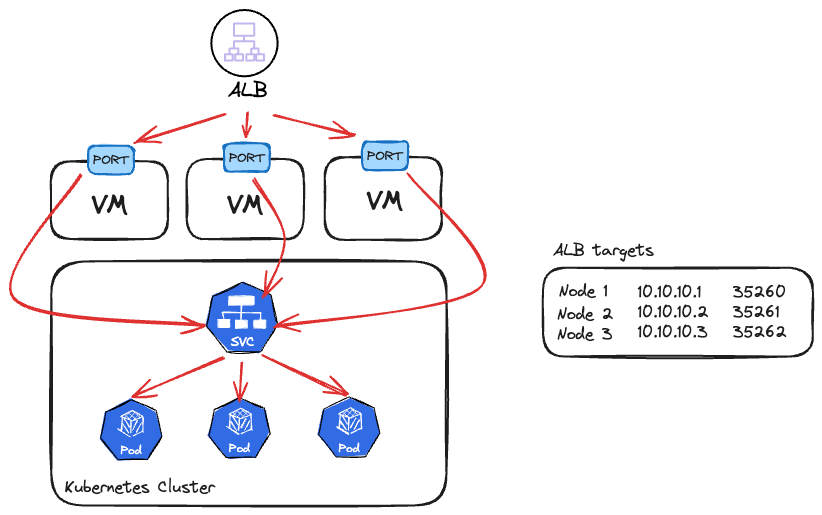
Bu yöntemi kullanırken, nodeları ALB'e manual olarak tek tek eklemek yerine ALB Controller tercih ederiz. Çünkü nodelar spot makineler gibi dinamik olabilir veya service güncellemelerinde her seferinde manual işlem yapmak istemeyiz.
ALB Controller kurulumda ise çok büyük oranla instance modu tercih ediliyor ve işleyiş Şekil 3'te çizdiğim şema gibi çalışmaya başlıyor.
Şimdi bu senaryodaki sorunları listeleyelim:
- Node port üzerinden gelen trafik Service nesnesi ile yönlendirildiği için yukarıda anlattığımız keep-alive sorununu yaşıyoruz ve aslında ALB kullanmamıza rağmen load balancing nimetlerinden yararlanamamış oluyoruz.
- Clusterınızda 100 adet node olduğunu varsayalım. Fakat erişmeye çalıştığınız service altında sadece 1 adet pod var. Bu bir adet pod için ALB target group içine 100 tane node ip adresi ve portunu kaydediyorsunuz. Halbuki sadece bir adet hedef mevcut. Bu da hem daha fazla latency (hedef pod aynı node üzerinde yer almayabilir), hemde target group kurallarının şişmesi demek. Ekstra olarak service nesnesi halen devrede olduğundan yine keep-alive sorununa takılacağımızı artık söylemiyorum bile.
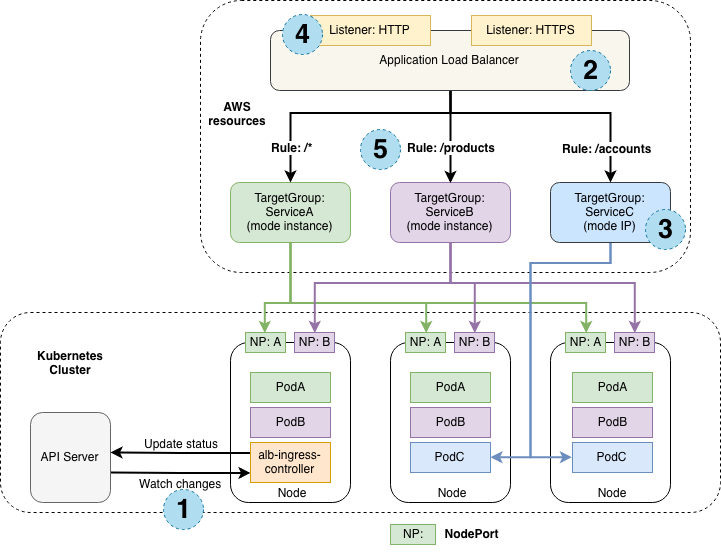
Çözüme gelirsek, bu genele yayılmış yanlış kullanımı düzeltmek için ilk yapacağımız şey ALB controller modunu instance tipinden ip tipine çevirmek olacak. Böylece artık target group içine node ip adresleri ve portları yerine direkt ilgili Service altındaki pod ip adresleri ve portları yazılacak ve Service üzerinden değil, direkt pod ip adresine erişim sağlayacağız.
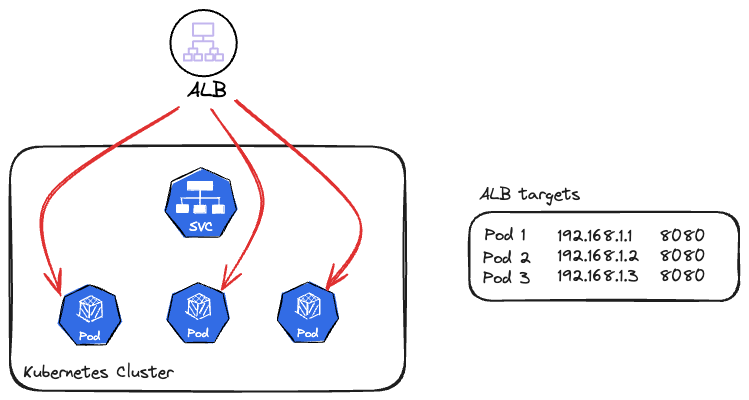
Bu sayede Service nesnesi devreden çıkmış olacak ve load balancing gerçek anlamda ALB nin sorumluluğunda kalacak. Ayrıca keep-alive olsa bile ALB hedef ip adresleri arasında gerçek bir round robin algoritması uygulayabilecek.
Üstelik Ingress nesnenize ekleyeceğiniz basit bir anotasyon ile ip mod geçişini yapmanız oldukça kolay bir iş.
annotations = {
...
"alb.ingress.kubernetes.io/target-type" = "ip"
...
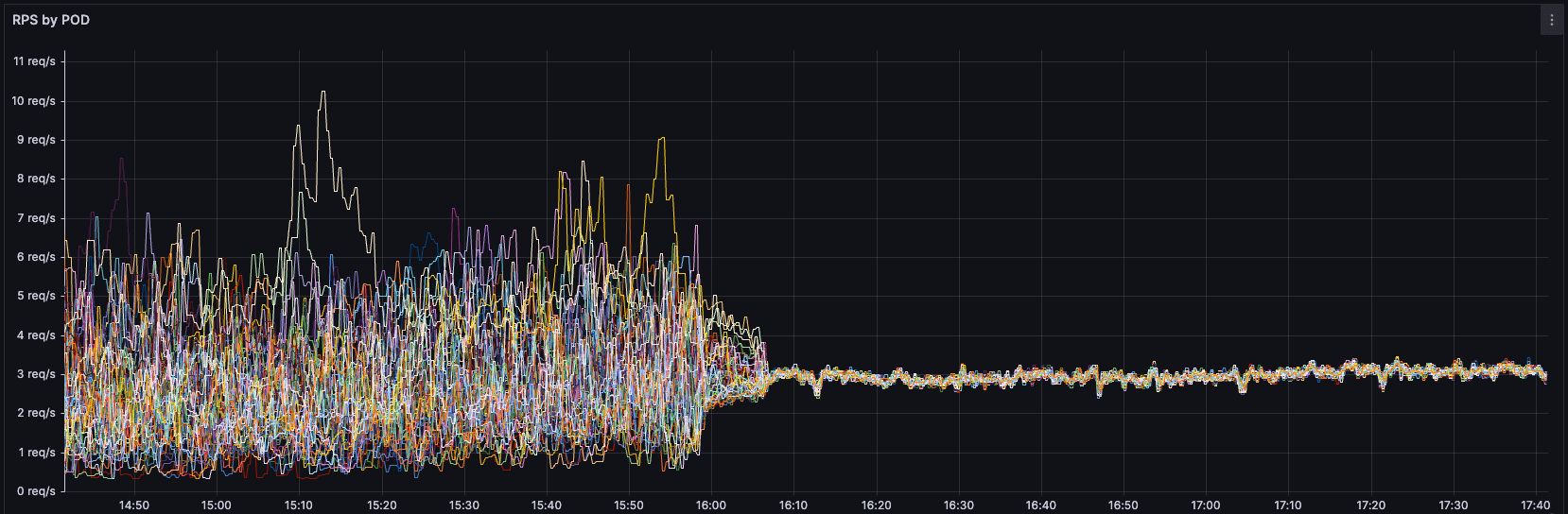
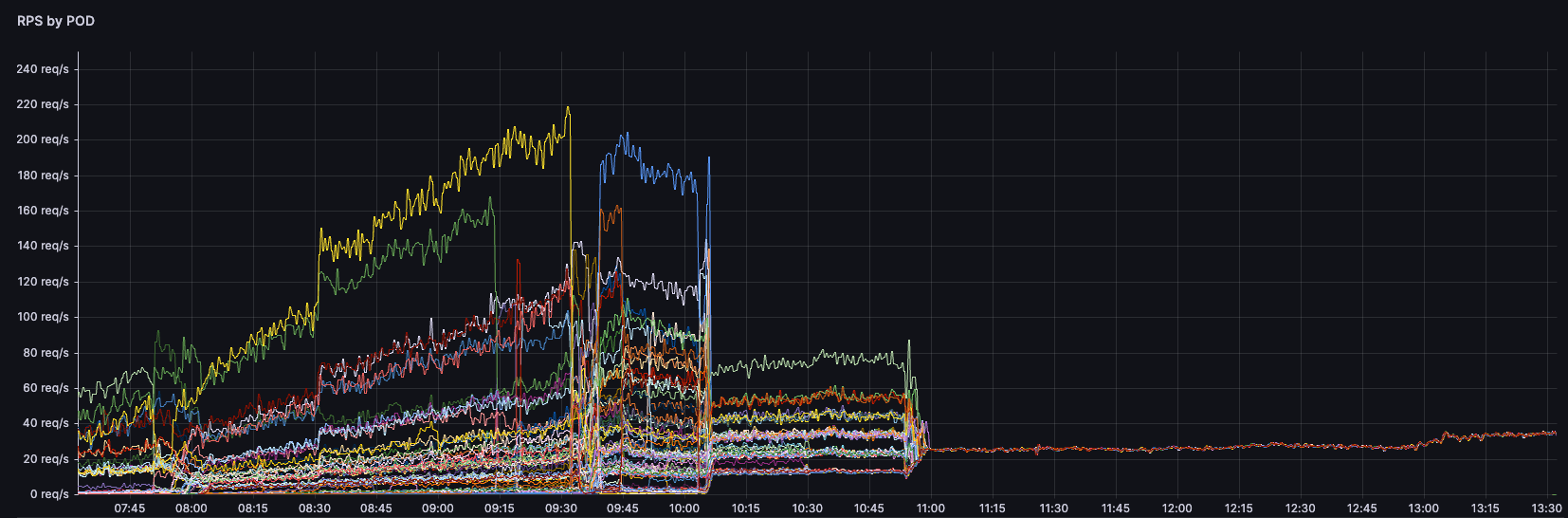
}Şimdi en heyecanlı kısmına gelelim. Böyle yaptığımızda bizi nasıl bir sonuç bekliyor? Biz kendi ip mode geçişimizi yaptığımızda podlarımızın RPS grafiği tam da şöyle oldu:
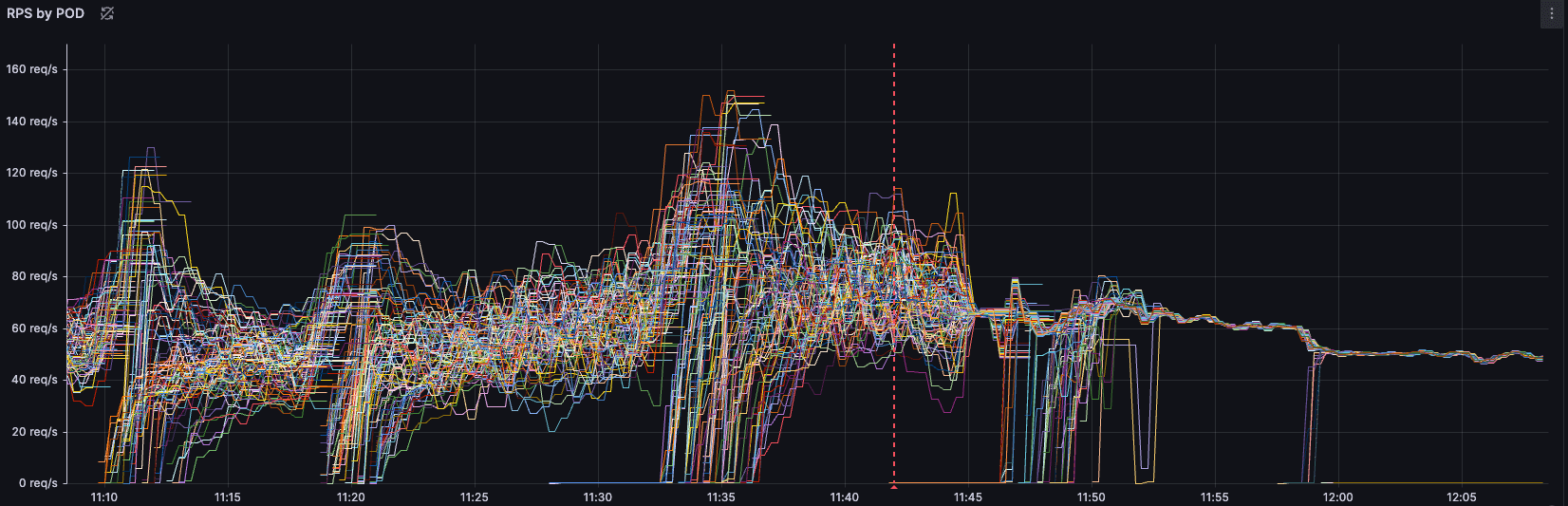
Saat 11:45 civarında ip mode geçişini yaptığımızda, artık tüm podların saniyede aldığı istek sayısı tutarlı ve dengeli bir hale gelmeye başladı. Daha öncesinden keep-alive bağlantılar sebebiyle bir poda TCP bağlantı açıldığında aynı kaynaktan gelen tüm istekler yine aynı poda gitmeye devam ediyordu.
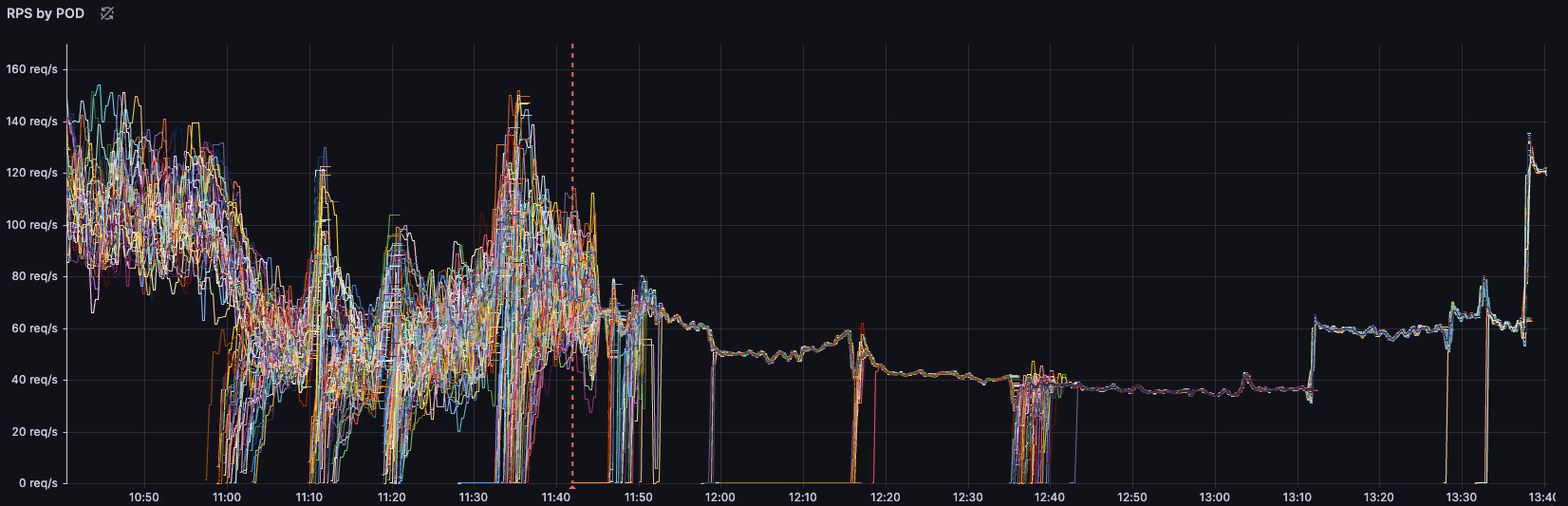
Bu da bazı podları 150 RPS değerlerine çıkarırken bazı podların yatış pozisyonunda kalmasına sebep oluyordu. Grafikten de göreceğiniz gibi dengesiz bir RPS dağılımı bu geçişle birlikte dengeli bir hale geldi ve yükü tüm podlar üzerine eşit dağıttı. RPS değeri yüksek olan podlardaki resource kullanımını ve limitler sebebiyle doğan pressure ve performans problemleri de bir anda çözülmüş oldu. Artık uygulama daha performanslı ve düşük latency ile çalışmaya başladı.
İlk madde dışarıdan aldığımız trafik üzerineydi. Şimdi internal haberleşme kısmını ele alalım.
2. Uygulamalar Arası Haberleşmeyi Service Nesnesi Üzerinden Yapmak (!)
Microservice mimarisine sahip ekosisteminizde uygulamalarımızın haberleşmesi için yine Service nesnelerini kullanıyoruz. Bu oldukça mantıklı çünkü bir uygulama, iletişime geçeceği diğer uygulamaya ait yüzlerce podun ip adresini bilemez. Tek bir giriş noktası olan hedef uygulamaya ait Service nesnesi üzerinden haberleşmeye çalışır.
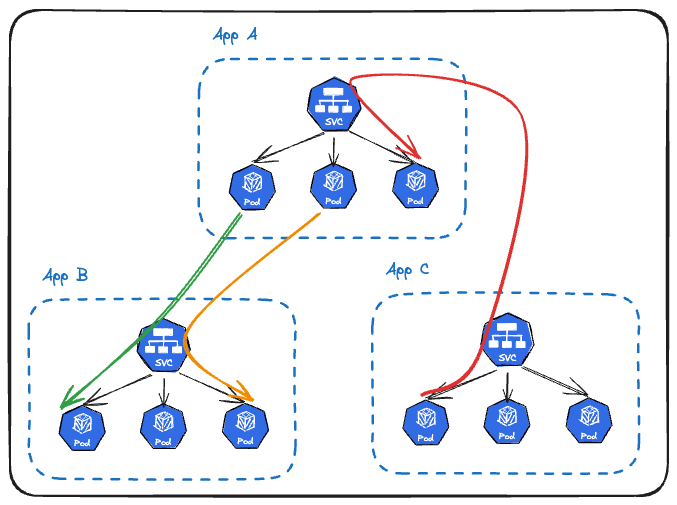
Aynı şeyleri tekrar yazmaya gerek yok. Görselde farkedeceğiniz üzere Service nesneleri yine keep-alive yüzünden doğru bir load balancing yapamayacak ve App C nin Pod 1 inden App A ya atılan istekler hem aynı kırmızı ok üzerinden aynı poda düşmeye devam edecek.
Bu sorunu çözmek için yine ALB controller'ın ip mode özelliğini kullanacağız.
Neden internal trafiği ALB'e taşıyıp tekrar cluster içine sokalım diyenleri duyuyorum. Fakat işini doğru yapamayan bir mekanizma varsa neden onu kullanmakta ısrarcı olalım ki?
Öyleyse uygulamalarımızın properties dosyalarındaki hedef adres olarak kullandığımız internal service adreslerini (ör: service-a.namespace.svc.local) artık ip mode kullanan load balancer adresimizle değiştirmeye başlayabiliriz.
Bu değişiklik sonrası şemamız şuna dönmüş olacak:
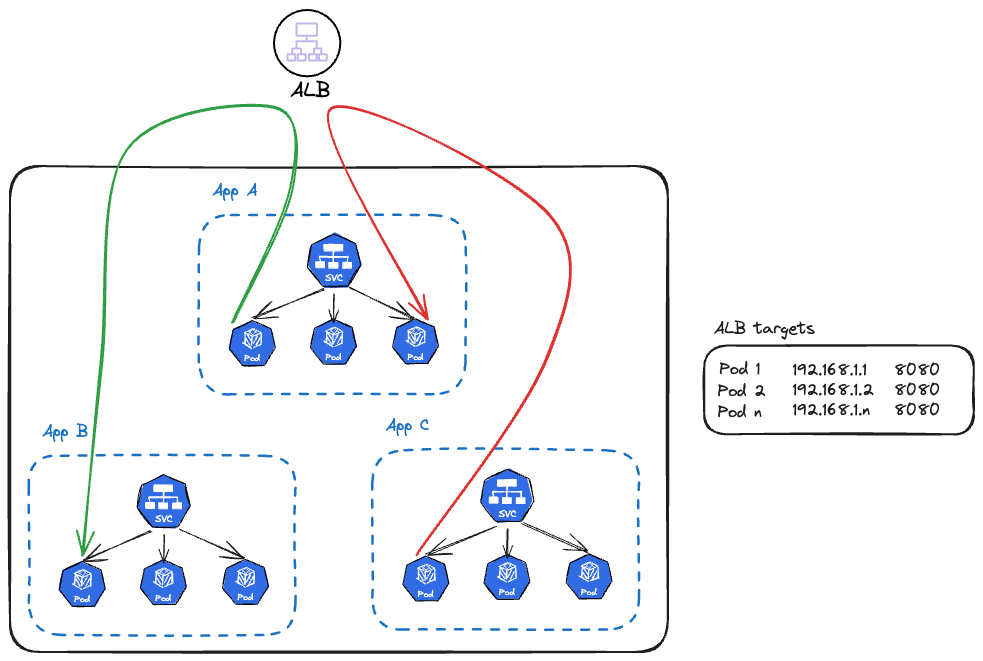
Biz bu değişikliği yaptığımızda sonuçlar yine muhteşem oldu. Internal iletişimde trafik alan podlarımızın RPS değerleri yine stabil ve dengeli hale gelmeye başladı.
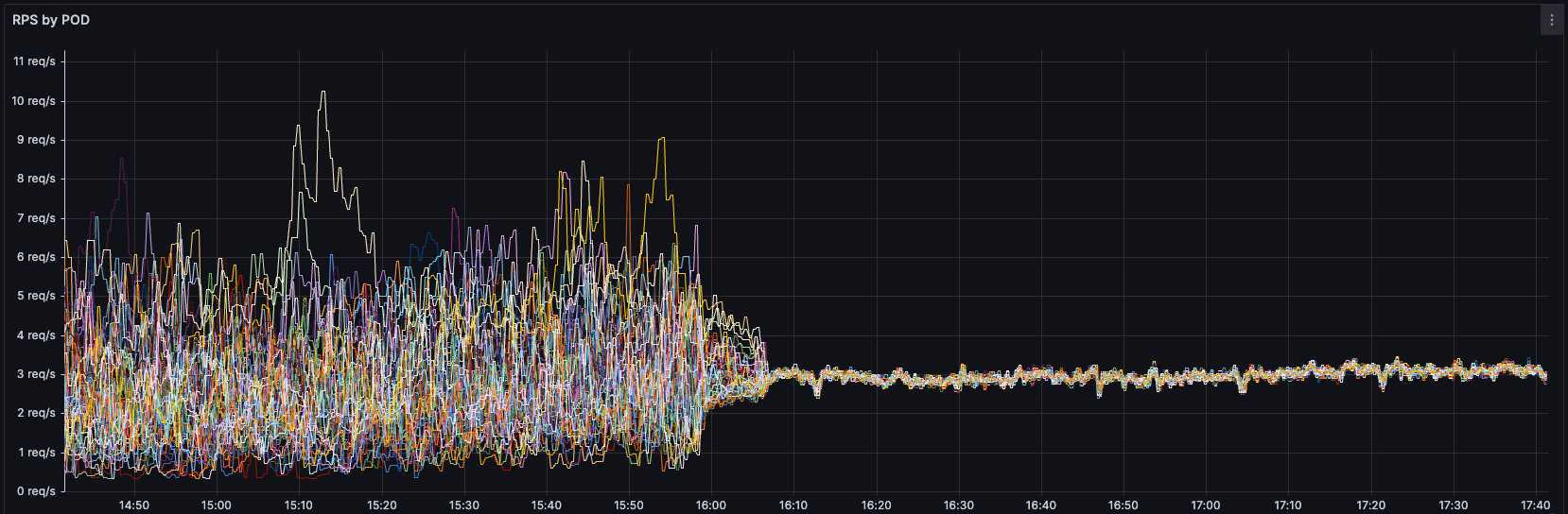
Bu grafikler gibi bir çok uygulamamız artık daha stabil ve kararlı çalışıp eşit bir trafik dağılımına sahip olmaya başladı. Tabi bunun bize getirdiği avantajlarda şunlar oldu:
- Round robin uygulaması gerçek anlamıyla uygulanmaya başlandığı için tüm podlara eşit trafik dağılımı sağlandı
- RPS değerleri yüksek olan ve ağır trafik altında ezilen podlar, kaynak sınırlamaları sebebiyle düşük performansla çalışıyorlardı. Artık aynı değerde sahip oldukları kaynaklarla daha düşük latency ve daha yüksek performans sunabiliyorlar
- Özellikle Nodeport tipindeki servislerin trafiği önce bir node'dan diğer node'a taşımaları (hedef pod aynı node üzerinde olmayabilir) sebebiyle gelen latency ve network maaliyeti önemli ölçüde azaldı
- Grafiklerimiz bir insanın hayatına kadın eli değmişçesine düzenli bir hale geldi ve ortaya görsel bir şölen çıkardı :)
Bu deneyimi sizlerle paylaşarak neredeyse kimsenin farkında olmadığı bir durum için farkındalık oluşturmak istedim. Umarım faydalı olmuştur.