Terraform Zero Downtime Deploy Etmek
Terraform ve AWS kullanarak sıfır kesinti süreli (zero downtime) deploy yapabilirsiniz.


Artık modülünüzün bir web server cluster dağıtmak için temiz ve basit bir API'si olduğuna göre, sorulması gereken önemli bir soru, bu kümeyi nasıl güncelleyeceğinizdir. Yani, kodunuzda değişiklik yaptığınızda küme genelinde yeni bir Amazon Machine Image (AMI) nasıl dağıtırsınız? Ve bunu kullanıcılarınız için kesintiye neden olmadan nasıl yaparsınız?
İlk adım, AMI'yi modüller modules/services/webserver-cluster/variables.tf'de bir giriş değişkeni olarak tanımlamaktır. Gerçek dünya örneklerinde, gerçek web sunucusu kodu AMI'de tanımlanacağı için ihtiyacınız olan tek şey budur. Ancak, bu yazıdaki basitleştirilmiş örneklerde, tüm web sunucusu kodu aslında User Data komut dosyasındadır ve AMI yalnızca bir vanilla Ubuntu görüntüsüdür. Ubuntu'nun farklı bir sürümüne geçmek çok fazla bir ekstra sağlamayacaktır, bu nedenle yeni AMI giriş değişkenine ek olarak, User Data komut dosyasının tek satırlı HTTP sunucusundan döndürdüğü metni kontrol etmek için bir giriş değişkeni de ekleyebilirsiniz:
variable "ami" {
description = "The AMI to run in the cluster"
type = string
default = "ami-0fb653ca2d3203ac1"
}
variable "server_text" {
description = "The text the web server should return"
type = string
default = "Hello, World"
}Şimdi, bu server_text değişkeninin döndürdüğü değeri <h1> etiketinde kullanmak için modules/services/webserver-cluster/user-data.sh Bash scripti güncellemeniz gerekiyor:
#!/bin/bash
cat > index.html <<EOF
<h1>${server_text}</h1>
<p>DB address: ${db_address}</p>
<p>DB port: ${db_port}</p>
EOF
nohup busybox httpd -f -p ${server_port} &Son olarak, module/services/webserver-cluster/main.tf'de başlatma yapılandırmasını bulun ve var.ami'yi kullanmak için image_id parametresini güncelleyin ve var.server_text'e geçmek için user_data parametresindeki templatefile çağrısını güncelleyin:
resource "aws_launch_configuration" "example" {
image_id = var.ami
instance_type = var.instance_type
security_groups = [aws_security_group.instance.id]
user_data = templatefile("${path.module}/user-data.sh", {
server_port = var.server_port
db_address = data.terraform_remote_state.db.outputs.address
db_port = data.terraform_remote_state.db.outputs.port
server_text = var.server_text
})
# Required when using a launch configuration with an auto scaling group.
lifecycle {
create_before_destroy = true
}
}Şimdi staging ortamında, live/stage/services/webserver-cluster/main.tf'de yeni ami ve server_text parametrelerini ayarlayabilirsiniz:
module "webserver_cluster" {
source = "../../../../modules/services/webserver-cluster"
ami = "ami-0fb653ca2d3203ac1"
server_text = "New server text"
cluster_name = "webservers-stage"
db_remote_state_bucket = "(YOUR_BUCKET_NAME)"
db_remote_state_key = "stage/data-stores/mysql/terraform.tfstate"
instance_type = "t2.micro"
min_size = 2
max_size = 2
enable_autoscaling = false
}Bu kod, aynı Ubuntu AMI'yi kullanır, ancak server_text değerini yeni bir değerle değiştirir. Plan komutunu çalıştırırsanız, aşağıdakine benzer bir şey görmelisiniz:
Terraform will perform the following actions:
# module.webserver_cluster.aws_autoscaling_group.ex will be updated in-place
~ resource "aws_autoscaling_group" "example" {
id = "webservers-stage-terraform-20190516"
~ launch_configuration = "terraform-20190516" -> (known after apply)
(...)
}
# module.webserver_cluster.aws_launch_configuration.ex must be replaced
+/- resource "aws_launch_configuration" "example" {
~ id = "terraform-20190516" -> (known after apply)
image_id = "ami-0fb653ca2d3203ac1"
instance_type = "t2.micro"
~ name = "terraform-20190516" -> (known after apply)
~ user_data = "bd7c0a6" -> "4919a13" # forces replacement
(...)
}
Plan: 1 to add, 1 to change, 1 to destroy.Gördüğünüz gibi, Terraform iki değişiklik yapmak istiyor: İlk olarak, eski launch configuration'ı güncellenmiş user_data'ya sahip yenisiyle değiştirmek; ve ikincisi, yeni launch configuration başvurmak için ASG'yi değiştirmek. Sorun şu ki, ASG yeni EC2 Instance'ları başlatana kadar yalnızca yeni launch configuration'a atıfta bulunmanın hiçbir etkisi olmayacaktır. Peki, ASG'ye yeni instance'ları dağıtması için nasıl talimat vermeliyiz?
Seçeneklerden biri, ASG'yi yok etmek (örneğin, terraform destroy çalıştırarak) ve sonra onu yeniden oluşturmaktır (örneğin, terraform apply çalıştırarak). Sorun şu ki, eski ASG'yi sildikten sonra, kullanıcılarınız yeni ASG gelene kadar kesinti yaşayacaktır. Bunun yerine yapmak istediğiniz sıfır kesintili dağıtımdır. Bunu başarmanın yolu, önce yedek ASG'yi oluşturmak ve ardından orijinali yok etmektir. Daha önce gördüğünüz create_before_destroy yaşam döngüsü ayarı tam olarak bunu yapıyor.
Sıfır kesinti süreli dağıtımı elde etmek için bu yaşam döngüsü ayarından nasıl yararlanabileceğiniz aşağıda açıklanmıştır:
- ASG'nin
nameparametresini, doğrudan launch configuration'ın adına bağlı olacak şekilde yapılandırın. Launch configuration her değiştiğinde (ki bu, AMI veya User Data güncellediğinizde olacaktır), adı değişir ve dolayısıyla ASG'nin adı değişir ve bu da Terraform'u ASG'yi değiştirmeye zorlar. - ASG'nin
create_before_destroyparametresinitrueolarak ayarlayın, böylece Terraform onu her değiştirmeye çalıştığında, orijinali yok etmeden önce yeni ASG'yi oluşturacaktır. - ASG'nin
min_elb_capacityparametresini kümeninmin_sizedeğerine ayarlayın, böylece Terraform, orijinal ASG'yi yok etmeye başlamadan önce yeni ASG'den en az o kadar sunucunun ALB'deki sağlık denetimlerini geçmesini bekleyecektir.
Güncellenmiş aws_autoscaling_group kaynağının modules/services/webserver-cluster/main.tf'de nasıl görünmesi gerektiği aşağıda açıklanmıştır:
resource "aws_autoscaling_group" "example" {
# Açıkça launch configuration adına bağlıdır, bu nedenle her değiştirildiğinde bu ASG de değiştirilir
name = "${var.cluster_name}-${aws_launch_configuration.example.name}"
launch_configuration = aws_launch_configuration.example.name
vpc_zone_identifier = data.aws_subnets.default.ids
target_group_arns = [aws_lb_target_group.asg.arn]
health_check_type = "ELB"
min_size = var.min_size
max_size = var.max_size
# ASG dağıtımını tamamlamayı düşünmeden önce en azından bu kadar çok instance'ın durum denetimlerini geçmesini bekler
min_elb_capacity = var.min_size
# Bu ASG'yi değiştirirken, önce yedeği oluşturun ve orijinali ancak bundan sonra silin.
lifecycle {
create_before_destroy = true
}
tag {
key = "Name"
value = var.cluster_name
propagate_at_launch = true
}
dynamic "tag" {
for_each = {
for key, value in var.custom_tags:
key => upper(value)
if key != "Name"
}
content {
key = tag.key
value = tag.value
propagate_at_launch = true
}
}
}plan komutunu yeniden çalıştırırsanız, şimdi aşağıdakine benzer bir şey göreceksiniz:
Terraform will perform the following actions:
# module.webserver_cluster.aws_autoscaling_group.example must be replaced
+/- resource "aws_autoscaling_group" "example" {
~ id = "example-2019" -> (known after apply)
~ name = "example-2019" -> (known after apply) # forces replacement
(...)
}
# module.webserver_cluster.aws_launch_configuration.example must be replaced
+/- resource "aws_launch_configuration" "example" {
~ id = "terraform-2019" -> (known after apply)
image_id = "ami-0fb653ca2d3203ac1"
instance_type = "t2.micro"
~ name = "terraform-2019" -> (known after apply)
~ user_data = "bd7c0a" -> "4919a" # forces replacement
(...)
}
(...)
Plan: 2 to add, 2 to change, 2 to destroy.Dikkat edilmesi gereken en önemli şey, aws_autoscaling_group kaynağının artık name parametresinin yanında zorunlu değiştirmeyi söylüyor olmasıdır; bu, Terraform'un onu yeni AMI veya User Data nızı çalıştıran yeni bir ASG ile değiştireceği anlamına gelir. Dağıtımı başlatmak için apply komutunu çalıştırın ve çalışırken sürecin nasıl çalıştığını düşünün.
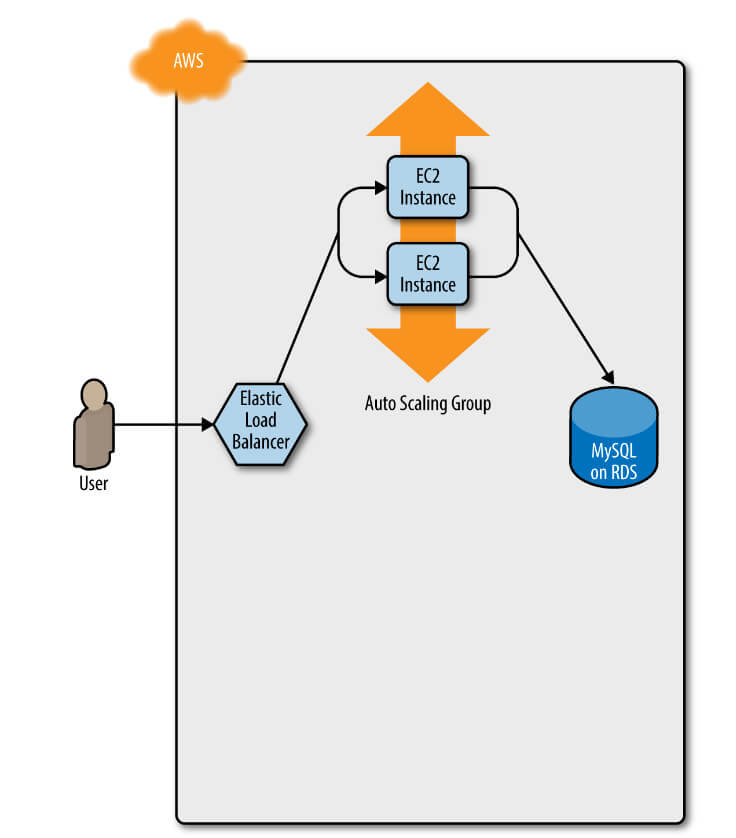
Orijinal ASG'nizin, örneğin kodunuzun v1'ini çalıştırarak başlarsınız (Şekil 1).
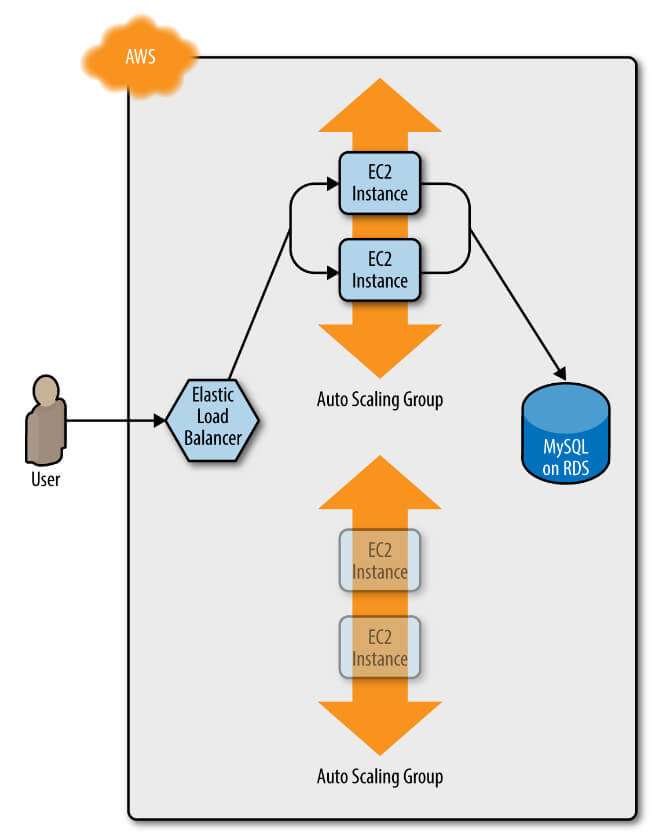
Kodunuzun v2'sini içeren bir AMI'ye geçmek gibi launch configuration'ınızın bazı yönlerinde bir güncelleme yapıp apply komutunu çalıştıralım. Bu, Terraform'u kodunuzun v2'si ile yeni bir ASG dağıtmaya başlamaya zorlar (Şekil 2).
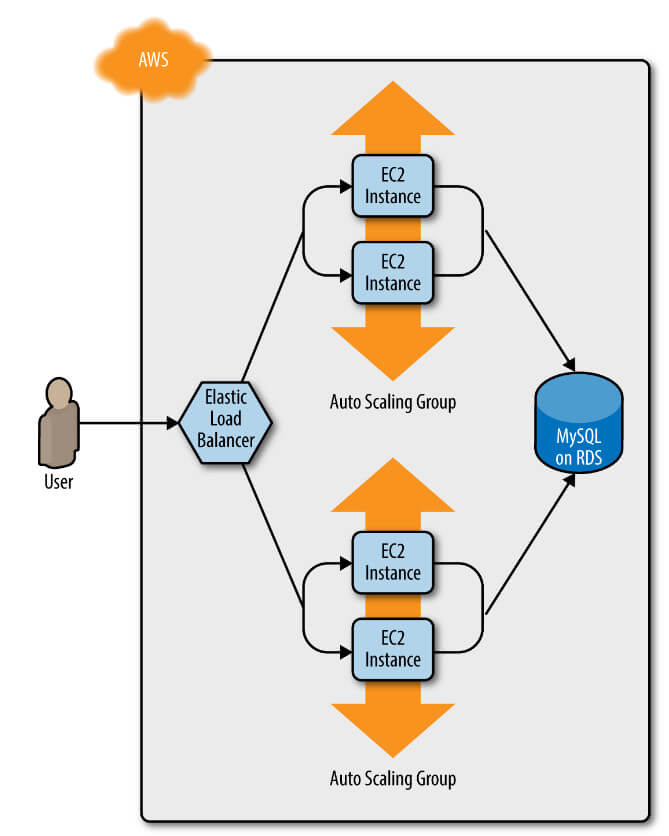
Bir veya iki dakika sonra yeni ASG'deki sunucular önyüklendi, veritabanına bağlandı, ALB'ye kaydoldu ve sağlık kontrollerinden geçmeye başladı. Bu noktada, uygulamanızın hem v1 hem de v2 sürümleri aynı anda çalışır; ve hangi kullanıcının ne gördüğü, ALB'nin onları nereye yönlendirdiğine bağlıdır (Şekil 3).
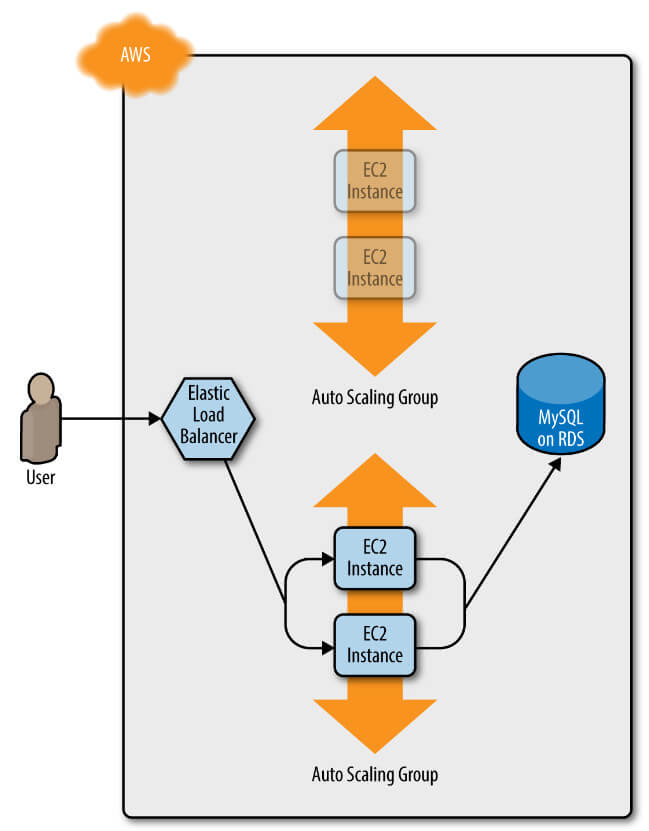
v2 ASG kümesindeki min_elb_capacity sunucuları ALB'ye kaydolduktan sonra Terraform, önce o ASG'deki sunucuların ALB'den kaydını silerek ve ardından kapatarak eski ASG'yi dağıtmaya başlayacaktır (Şekil 4).
Bir veya iki dakika sonra eski ASG gitmiş olacak ve yeni ASG'de çalışan uygulamanızın sadece v2'si kalacak (Şekil 5).
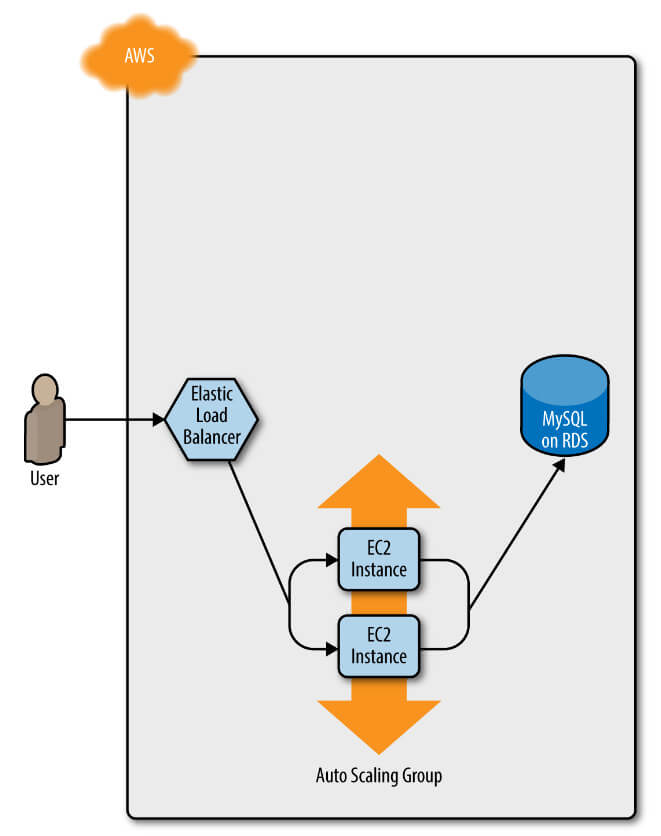
Tüm bu süreç boyunca, her zaman ALB'den gelen istekleri çalıştıran ve işleyen sunucular vardır, bu nedenle kesinti olmaz. ALB URL'sini tarayıcınızda açın ve Şekil 6 gibi bir şey görmelisiniz.
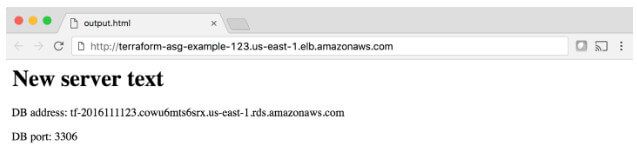
Başarılı! Yeni sunucu metni dağıtıldı. Eğlenceli bir deneme olarak, server_text parametresinde başka bir değişiklik yapın (örneğin, "foo bar" diyecek şekilde güncelleyin) ve apply komutunu çalıştırın. Ayrı bir terminal sekmesinde, Linux/Unix/macOS kullanıyorsanız, bir döngüde curl çalıştırmak, ALB'nize saniyede bir kez çağırmak ve sıfır kesinti süresi dağıtımını görmenizi sağlamak için bir Bash tek satırı kullanabilirsiniz. Örneğin:
$ while true; do curl http://<load_balancer_url>; sleep 1; doneİlk iki dakika içinde şunu görüyor olacaksınız: New server text. Bundan sonra, New server text ve foo bar metinleri karışık olarak gelmeye başlayacak. Bu, yeni Instance'ların ALB'ye kaydedildiği ve durum denetimlerini geçtiği anlamına gelir. Bir dakika, New server text mesajları kaybolacak ve yalnızca foo bar gözükmeye başlayacak. Çıktı iseşöyle görünecek:
New server text
New server text
New server text
New server text
New server text
New server text
foo bar
New server text
foo bar
New server text
foo bar
New server text
foo bar
New server text
foo bar
New server text
foo bar
foo bar
foo bar
foo bar
foo bar
foo barEk bir bonus olarak, dağıtım sırasında bir şeyler ters giderse, Terraform otomatik olarak geri dönecektir. Örneğin, uygulamanızın v2'sinde bir hata varsa ve önyükleme başarısız olursa, yeni ASG'deki Instance'lar ALB'ye kaydolmaz. Terraform, v2 ASG'nin min_elb_capacity sunucularının ALB'ye kaydolması için wait_for_capacity_timeout'a kadar (varsayılan 10 dakikadır) bekler, ardından dağıtımı bir hata olarak kabul eder, v2 ASG'yi siler ve bir hatayla çıkar (bu arada, v1'iniz orijinal ASG'de gayet iyi çalışmaya devam ediyor olacak).



