Snowflake ID Nedir? ID Server Nasıl Çalışır?
Snowflake ID, sort edilebilen, düşük bit sayısı sayesinde performanslı çalışan benzersiz kimlikler üretebilmeye yarayan projedir.


Veritabanı kayıtları için benzersiz (unique) tanımlayıcılar oluşturmak, verileri uygun bir şekilde saklamamıza ve zamanı geldiğinde daha kolay ortaya çıkarmamıza olanak tanıyan kritik bir niteliktir.
Bu benzersiz tanımlayıcılar, kod tarafından rastgele veya veritabanı tarafından çoğunlukla auto increment olarak ayarlanan bir integer(!) type ve primary key'den meydana gelir. Haliyle işler basitken okunması kolay ve az yer kaplayan bir alan olarak görevini yerine getirirler.
Fakat kod veya veritabanı tarafından oluşturulan kimliklerde bazı sorunlar ortaya çıkar. Örneğin veritabanında bir kaydı oluşturmadan önce bu benzersiz kimliği bilememek, dağıtık DB sistemlerde kimliklerin çakışma ihtimali, enumeration attack ile tahmin edilebilme gibi sorunlar bunların başında yer alıyor.
integer type kullanıyor. Proje başlangıcında 4 byte ve 2147483647 limit size fazlasıyla yeter gibi gözükse bile proje büyüyüp limite yaklaştığınız da ne olacak? Bunun için en azından bigint ile 9223372036854775807 sayısına ulaşana kadar rahat etmek daha doğru bir seçenek. Sonuçta depolama alanı daha kolay halledilebilir. Tabi eğer 4 byte ı nasıl doldurabiliriz, gereksiz bir not diyenler için 2038 de görüşmek üzere :) bkz. Year 2038 problemŞimdi bu sorunları nasıl çözebileceğimize gelelim. Bu yazıda, işe yarayan en yaygın üç yöntemi tartışacağım ve en son neden Snowflake kullanmamız gerektiğinden bahsedeceğim.
1- Universal Unique Identifier — UUID
Universal Unique Identifier, yıllardır yazılımda kullanılan iyi bilinen bir kavramdır. UUID, kontrollü ve standartlaştırılmış bir şekilde oluşturulduğunda, çakışma olasılığını neredeyse tamamen ortadan kaldıran son derece geniş bir anahtar alanı sağlayan 128 bitlik bir sayıdır.
UUID; zaman, node'un MAC adresi veya namespace'in MD5'i gibi birkaç farklı bölümden oluşan bir kimliktir. Tüm bu kombinasyonlara uyum sağlamak için yıllar boyunca UUID spesifikasyonunun birden fazla versiyonu mevcuttur.
UUID'ler genellikle 16 octet'in (16*8 = 128 bit) 32 hexadecimal karaktere dönüştürüldüğü kurallı bir metin biçiminde temsil edilir:

Görüldüğü gibi, UUID'lerin en ilginç özelliği, yalıtılmış olarak üretilebilmeleri ve yine de dağıtılmış bir ortamda benzersizliği garanti edebilmeleridir. Ek olarak, altta yatan kimlik oluşturma algoritması karmaşık değildir ve herhangi bir senkronizasyon gerektirmez. Bu nedenle dağıtık ortamlarda rahatlıkla kullanılabilirler:
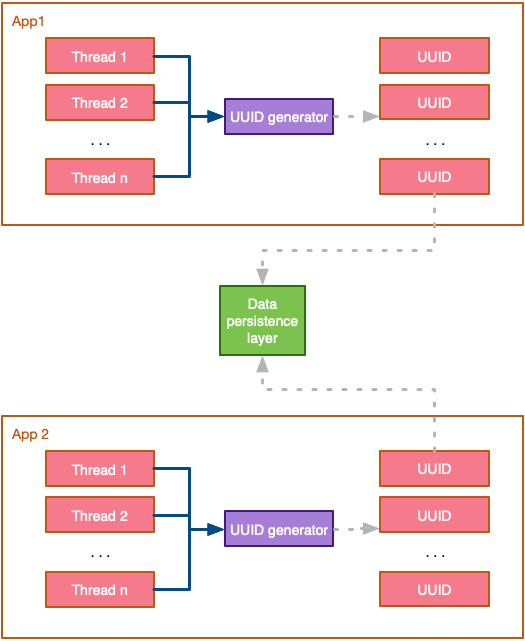
🚧 Bu eşsiz benzersizlik, UUID'leri dağıtık ortamlarda en sık kullanılan kimlik oluşturma tekniklerinden biri haline getirir. Ancak, eskiden bigint ile 8 byte (64bit) bir alan kullanıyorken UUID ile 16 byte (128bit) bir alan kullanmaya başlamış oluyoruz. Bu da ek depolama alanı ve sorgulama performansınızın olumsuz yönde etkileyebileceğini anlamına gelir. Üstelik en kritik noktası, artık verilerinizi ID ye göre sort edemezsiniz!
2- Persistence Layer Generated IDs
Uygulama düzeyinde benzersiz kimlikler oluşturmak istemediğinizde yaygın bir yaklaşım, veritabanınızın bununla ilgilenmesine izin vermektir. Tüm yeni RDBMS'ler, benzersiz bir tanımlayıcının oluşturulmasına olanak tanıyan bir tür veri tipi sağlar. Postgresql SERIAL, MySQL ve MariaDB AUTO_INCREMENT, MongoDB ObjectID, MS SQL Server IDENTITY ile bu benzersiz kimlik üretme işlemini sağlar. Kimliğin gerçek temsili farklı veritabanı uygulamaları arasında farklılık gösterir, ancak benzersizlikle ilgili semantik aynı kalır.
🚧 Veritabanı tarafından oluşturulan kimlikler, uygulama kodunda benzersiz kimlikler oluşturmak zorunda kalma sorununu azaltır. Ancak, önünde çok yoğun bir uygulama bulunan büyük bir veritabanı kümesi çalıştırıyorsanız, bu yaklaşım gereksinimleriniz için yeterince performanslı olmayabilir.
🚧 Veritabanı tarafından oluşturulan kimlikleri kullanırken başka bir sorun ise, oluşturulan kimliğin veritabanına gidiş dönüş olmadan kodunuz tarafından bilinmemesidir:
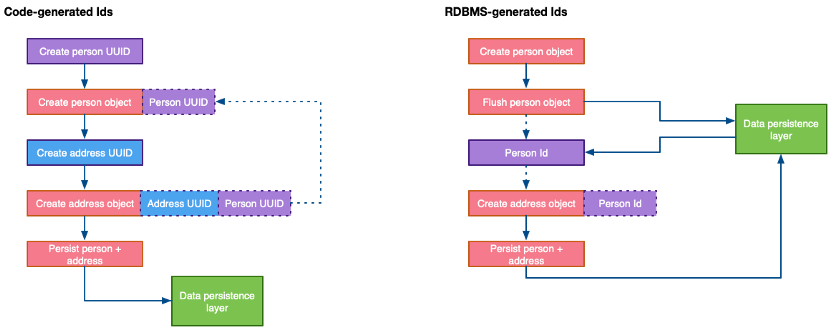
Yukarıdaki örnek şemayı incelediğinizde RDBMS'ye ekstra gidiş-dönüş uygulamanızı yavaşlatabilir ve kodunuzun gereksiz yere daha karmaşık görünmesine neden olabilir, ancak modern ORM çerçeveleri, kullandığınız temel RDBMS ürününün sırasıyla standartlaştırılmış bir şekilde bunu yapmanıza yardımcı olabilir.
3- Snowflake ID & ID server
2013 senesinde, Twitter'a saniyede atılan tweet satısı ortalama 5700 tweet'ten 143199 tweet'e kadar yükseldiğinde, yalnızca geniş sunucu altyapılarına ölçeklemekle kalmayıp aynı zamanda depolama için kimlikler üreten bir çözüme ihtiyaç duyulmuş.

Bu olay üzerine Twitter, <2ms'lik bir yanıt oranıyla işlem başına saniyede en az 10000 kimlik üreten bir çözüm aramaya başlamış. Bu çözüm şu 3 şartı yerine getirmeliymiş;
- Kimlik sunucuları, aralarında hiçbir ağ koordinasyonu gerektirmemeli
- Oluşturulan kimlikler kabaca zaman sıralı olmalı.
- Son olarak, depolamayı minimumda tutmak için kimlikler küçük boyutlu olmalı.
Zor gözüküyor değil mi :) Fakat bu olay ve yukarıdaki koşullar doğrultusunda ortaya Snowflake projesi çıkmış:
Bir kimlik sunucusu (ID server), dağıtık altyapınız için benzersiz kimlikler oluşturmakla ilgilenir. Kimlik sunucunuzun uygulanmasına göre, kimlikler oluşturan tek bir sunucu veya saniyede çok sayıda kimlik oluşturan bir sunucu kümesi olabilir.
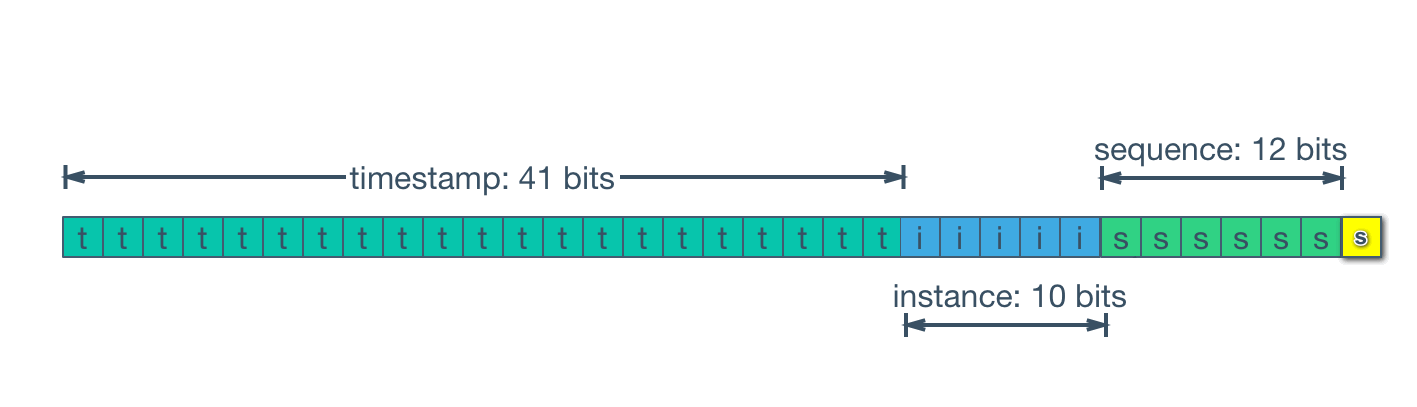
Snowflake standartları ile ID server tarafından oluşturulan bir kimlik şu alanları içerir:
- Zaman damgası — 41 bit
- Makine kimliği — 10 bit
- Sıra numarası — 12 bit
- Extra bit - 1 bit
Kimlik sunucusuna sahip bir çözüm, kod tarafından oluşturulan kimliklere benzer şekilde çalışır:
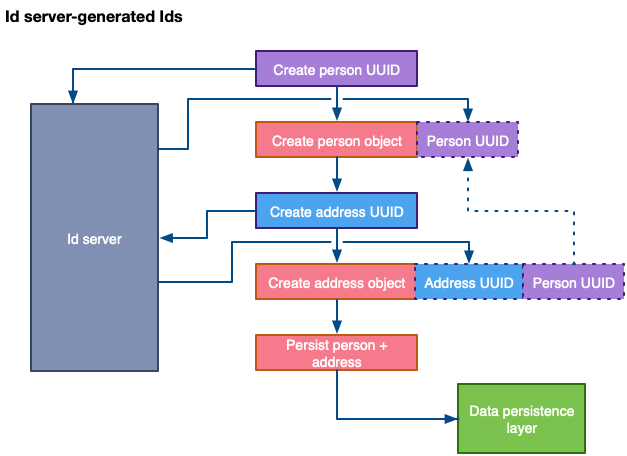
🎯 Fark edebileceğiniz gibi, ID sunucusuna gidiş dönüş nedeniyle performans hala düşmektedir, ancak bu ek gecikme, karmaşık veritabanı işlemlerini içermediğinden, bir nesneyi RDBMS'ye yazıp okumaya nispeten çok daha azdır.
🎯 Oluşturulan kimlik 8 byte (64bit)'ten oluşur. Bu da performans ve kapasite açısından UUID ye göre büyük avantaj sağlar.
🎯 Bir kimlik sunucusu, karmaşık, yüksek gecikme süresine neden olan bir altyapı oluşturmadan benzersiz kimliklerinizin nasıl ve nerede oluşturulacağını kontrol etmenizi sağlayan bir çözüm sağlar.
Özet
Benzersiz tanımlayıcılar oluşturmak, sonunda verileri kalıcı hale getirmesi gereken tüm uygulamalar için bir zorunluluktur.
Bu makalede, yaygın olarak kullanılan üç yaklaşımı tartıştık. Snowflake'in ise diğer yöntemlere göre avantajlarına özellikle değindik. Yine de uygulamanızda benzersiz kimlikler oluşturmak için bir strateji belirlemek, verilerinize, veritabanı seçeneğinize ve ağ altyapınıza bakmanız gerekir. Herkese uyan tek bir çözüm olmadığından, seçeneklerinizi değerlendirmeli ve gereksinimlerinize ve elde etmek istediğiniz ölçeğe uygun olanı seçmelisiniz.



