Kafka Topic, Partition, Producer, Consumer, Offset, Broker ve Cluster Nedir?
Kafka temel konularının tümünü tek bir başlık altında bulabileceğiniz detaylı bir rehber hazırladık.


Apache Kafka'nın ne olduğunu, kullanım senaryolarını ve nasıl kurulacağını öğrendiğimize göre, daha derine inelim ve tüm Kafka temel başlıkları üzerinden geçelim. Bu yazımızda Kafka topic, partition, offset, producer, consumer, broker, cluster, replication ve Zookeeper kavramlarıyla ilgili temel bilgileri ele alacağız.

Öncesinde hızlı bir hatırlatma için şu iki yazımıza göz atabilirsiniz:


1. Kafka Topic Nedir?
Veritabanlarının veri kümelerini düzenlemek ve bölümlere ayırmak için tablolara sahip olduğu gibi, Kafka da ilgili mesajları düzenlemek için topic kavramını kullanır.
Bir topic, adıyla tanımlanır. Örneğin, bir uygulamadan alınan logları içeren logs adlı bir topic'e sahip olabiliriz. Benzer şekilde satış gerçekleştiği anda satın alma verilerini içerebilen purchases isimli bir topic'e de sahip olabiliriz.
Topicler kabaca SQL tablolarına benzer. Ancak SQL tablolarından farklı olarak Kafka topicler üzerinde sorgular çalıştıramazsınız. Bunun yerine, verileri kullanmak için Kafka producerlar ve consumerlar yaratmalıyız. Topiclerdeki veriler, binary tipinde key-value çiftleri biçiminde depolanır.
Kafka topicleri herhangi bir tipte herhangi bir mesaj içerebilir ve tüm bu mesajlar dizisine data stream denir.
Kafka topiclerindeki veriler varsayılan olarak bir hafta sonra silinir (varsayılan message retention period değeri) ve bu değer yapılandırılabilir. Eski verileri silmeye yönelik bu mekanizma, topicleri zaman içinde recycle ederek bir Kafka kümesinin disk alanının tükenmemesini sağlar.
1.1 Kafka Topic Örneği
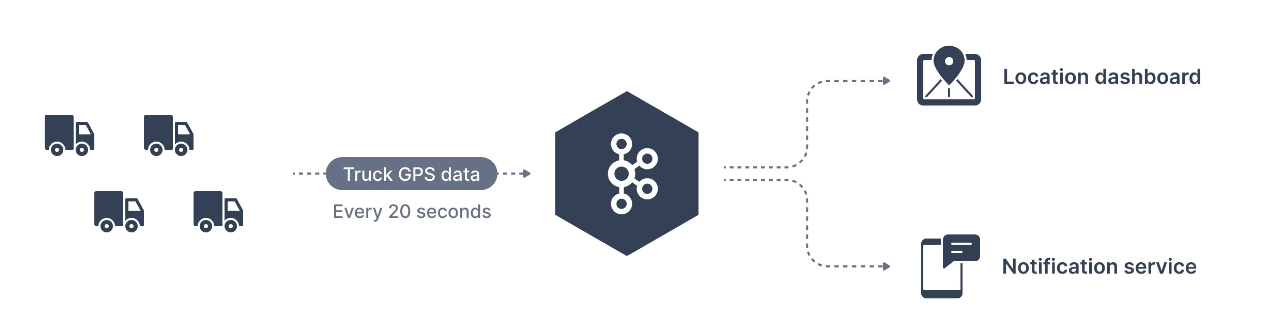
Bir trafik şirketi, kamyon filosunu takip etmek istiyor. Her kamyon, konumunu Kafka'ya bildiren bir GPS bulucu ile donatılmıştır. Kamyonların konumlarını yayınladıkları - truck_gps adında bir topic oluşturabiliriz. Her kamyon Kafka'ya her 20 saniyede bir mesaj gönderebilir ve gönderilen her mesaj kamyon kimliğini ve kamyon konumunu (enlem ve boylam) içerecektir. Topic uygun sayıda partitiona ayrılabilir (örneğin 10). Topic'in farklı consumerları olabilir. Örneğin, bir panoda kamyon konumlarını görüntüleyen bir uygulama veya önemli bir olay meydana geldiğinde bildirim gönderen başka bir uygulama.
2. Kafka Partition Nedir?
Topicler birkaç partition'a ayrılmıştır. Tek bir topic'in birden fazla partition'ı olabilir. Uygulamalarda çokça 100 partition'a sahip topiclere denk gelebilirsiniz.
Bir topic'in partition sayısı, topic oluşturulurken belirtilir. Partitionlar, 0'dan N-1'e kadar numaralandırılır ve burada N toplam partition sayısıdır. Aşağıdaki şekil, her birinin sonuna iletilerin eklendiği üç partition'lı bir topic'i göstermektedir.
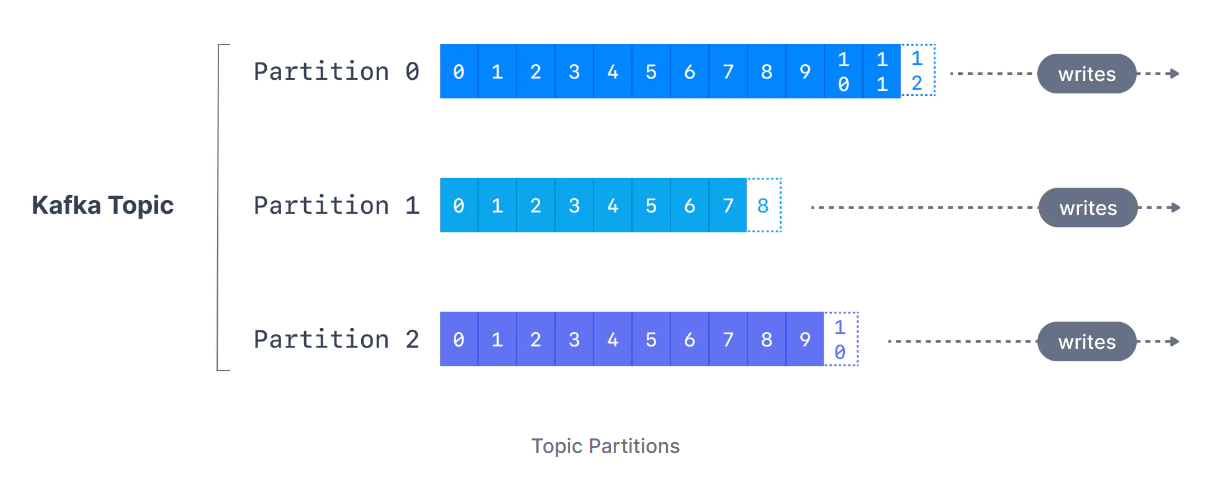
Offset, Kafka'nın bir partition'a yazılırken her iletiye eklediği bir tamsayı değeridir. Belirli bir bölümdeki her mesajın benzersiz bir offset numarası vardır.
3. Kafka Offset Nedir?
Apache Kafka offset, bir mesajın bir Kafka partition içindeki konumunu temsil eder. Her partition için offset numaralandırma 0'dan başlar ve belirli bir Kafka partition gönderilen her mesaj için artırılır. Bu, Kafka offsetlerinin yalnızca belirli bir parititon için bir anlamı olduğu anlamına gelir. Örneğin, partition 0'daki offset 3, partition 1'deki offset 3 ile aynı verileri temsil etmez.
Kafka topiclerindeki mesajların zamanla silindiğini (yukarıda görüldüğü gibi) bilsek de offsetler asla tekrar kullanılmaz. Hiç bitmeyen bir sırayla sürekli olarak artırılırlar.
4. Kafka Producer Nedir?
Kafka ile bir topic oluşturulduktan sonra sıradaki adım topic'e veri göndermektir. Kafka producerların devreye girdiği yer burasıdır.
Topiclere veri gönderen uygulamalar, Kafka producerlar olarak bilinir. Uygulamalar, Apache Kafka'ya yazmak için genellikle bir Kafka client library entegre ederler. Python, Java, Go ve diğerleri dahil olmak üzere günümüzde popüler olan hemen hemen tüm programlama dilleri için mükemmel client libraryler mevcuttur.
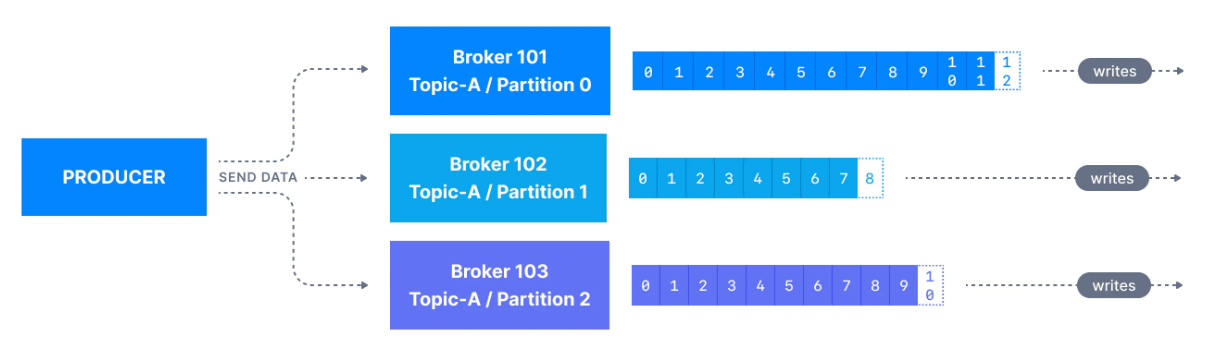
Bir Kafka producer, bir topic'e mesaj gönderir ve mesajlar, key hashing gibi bir mekanizmaya göre partitionlara dağıtılır (aşağıda daha fazla detay vereceğim).
Bir mesajın bir Kafka topic'e başarılı bir şekilde yazılabilmesi için, bir producer'ın bir onay düzeyi (acks) belirtmesi gerekir. Bu konu, topic replication bölümünde derinlemesine anlatılacaktır.
4.1. Message Key
Her event mesajı opsiyonel olarak bir key ve bir value çifti içerir.
Key'in producer tarafından belirtilmemesi durumunda (key=null), mesajlar bir topic içindeki partitionlar arasında eşit olarak dağıtılır. Bu, mesajların sırayla gönderildiği anlamına gelir (partition p0, sonra p1, sonra p2, vb... sonra tekrar p0'a vb.).
Bir key gönderilirse (key != null), aynı key'i paylaşan tüm mesajlar her zaman aynı Kafka partition'a gönderilir ve saklanır. Key, bir mesajı tanımlayan herhangi bir şey olabilir (bir dizi, sayısal değer, binary değer, vb.)
Kafka mesaj keyleri, aynı partition'ı paylaşan tüm mesajlar için mesaj sıralamasına ihtiyaç duyulduğunda yaygın olarak kullanılır. Örneğin, bir filodaki kamyonları izleme senaryosunda, kamyonlardan gelen verilerin her bir kamyon düzeyinde sıralı olmasını istiyoruz. Bu durumda key'i truck_id olarak seçebiliriz. Aşağıda gösterilen örnekte, truck_id_123 kimliğine sahip kamyondan gelen veriler her zaman p0 bölümüne gidecektir.

Birkaç başlık sonra key hashleme sürecini (hangi anahtarın hangi bölüme gideceğini belirleme süreci) öğreneceksiniz.
4.2. Mesaj Yapısı
Kafka mesajları producer tarafından oluşturulur. Bir Kafka mesajı aşağıdaki unsurlardan oluşur:
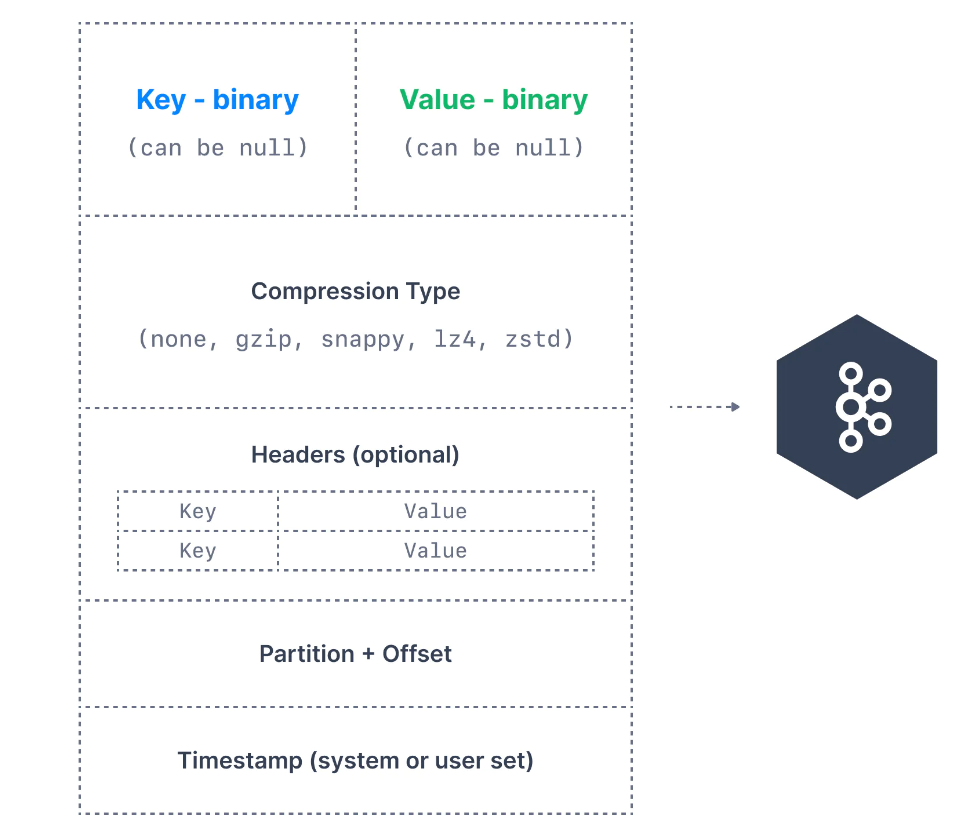
- Key: Kafka mesajında isteğe bağlıdır ve boş olabilir. Key bir dizi, sayı veya herhangi bir nesne olabilir ve ardından key binary formata serialize edilir.
- Value: Mesajın içeriğini temsil eder ve boş da olabilir. Değer formatı isteğe bağlıdır ve daha sonra binary formata serialize edilir.
- Compression Type: Kafka mesajları sıkıştırılabilir. Sıkıştırma türü, mesajın bir parçası olarak belirtilebilir. Seçenekler
none,gzip,lz4,snappyvezstd'dir. - Headers: Key-value çiftleri biçiminde isteğe bağlı Kafka mesaj başlıklarının bir listesi olabilir. Özellikle tracking için, mesajla ilgili meta verileri belirtmek üzere başlıklar eklemek yaygın bir uygulamadır.
- Partition + Ofset: Bir mesaj bir Kafka topic'e gönderildiğinde, bir partition numarası ve bir offset kimliği alır. Topic+partition+offset kombinasyonu, mesajı benzersiz bir şekilde tanımlar.
- Timestamp: Mesaja kullanıcı veya sistem tarafından bir zaman damgası eklenebilir.
4.3. Mesaj Serializer
Birçok programlama dilinde, key ve value, kodun okunabilirliğini büyük ölçüde artıran nesneler olarak temsil edilir. Ancak Kafka brokers (sunucular), mesajların key-value çiftlerini byte array olarak bekler. Producer'ın, bu nesneleri binary'e dönüştürmesine serialization adı verilir.
Aşağıda gösterildiği gibi, bir integer key ve bir string value olan bir mesajımız var. Key bir integer olduğundan, onu bir byte array'e dönüştürmek için bir IntegerSerializer kullanmamız gerekir. Value için ise, bir string olduğundan StringSerializer'dan yararlanmalıyız.
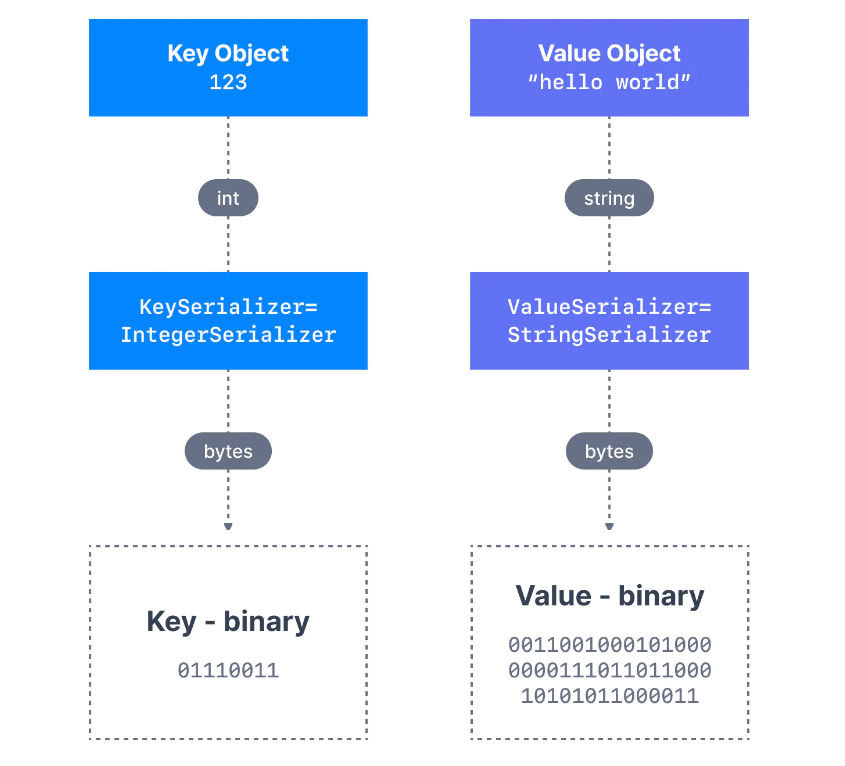
Apache Kafka için Java cliend SDK'sının bir parçası olarak, string (JSON'un yerini alır), integer, float gibi birkaç serializer zaten mevcuttur. Diğer serializerların kullanıcılar tarafından yazılması gerekebilir. Ancak yaygın olarak dağıtılan Kafka serializer da mevcuttur ve Confluent Schema Registry sayesinde JSON-Schema, Apache Avro ve Protobuf gibi formatlar için verimli bir şekilde yazılabilir.
4.4. Mesaj Key Hashing
Kafka partitioner, bir kayıt alan ve o kaydın hangi partition'a gönderileceğini belirleyen bir code logictir.

Bu anlamda, partition bir mesajı belirli bir topic partition'a yönlendirmek için mesaj key hashing kullanır. Bir hatırlatma olarak, aynı key'e sahip tüm mesajlar aynı bölüme gidecektir.
Varsayılan Kafka partitioner, meraklılar için aşağıdaki formülle murmur2 algoritması kullanılarak keyleri hashler:
targetPartition = Math.abs(Utils.murmur2(keyBytes)) % (numPartitions - 1)Producer sınıfı olan partitioner.class ile varsayılan partitioner'ı override etmek mümkündür, ancak ne yaptığınızı bilmiyorsanız tavsiye edilmez.
5. Kafka Consumer Nedir?
Kafka topiclerinden veri okuyan uygulamalar consumer olarak bilinir. Uygulamalar, Apache Kafka'dan okumak için bir Kafka client library entegre eder. Python, Java, Go ve diğerleri dahil olmak üzere günümüzde popüler olan hemen hemen tüm programlama dilleri için mükemmel client libraryler mevcuttur.
Consumerlar, Apache Kafka'da aynı anda bir veya daha fazla partitiondan okuyabilir ve veriler aşağıda gösterildiği gibi her partitiondaki sırayla okunur.
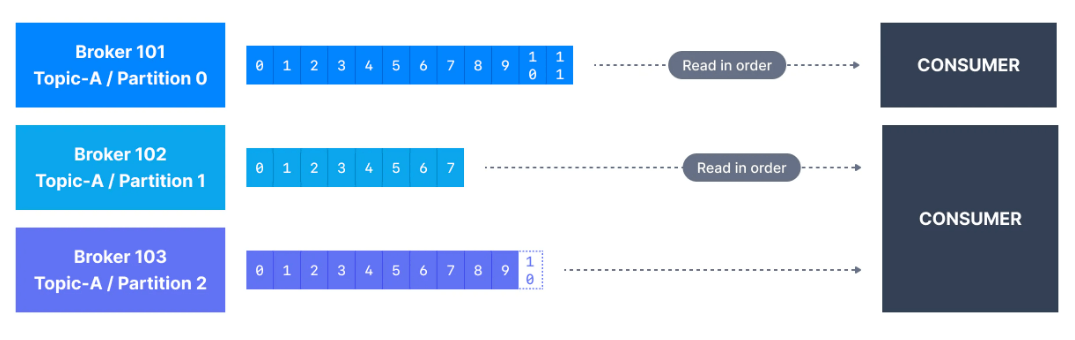
Bir consumer, verileri her zaman daha düşük bir offsetten daha yüksek bir offsete okur ve verileri geriye doğru okuyamaz.
Consumer birden fazla partitiondan veri okuyorsa, aynı anda kullanıldıkları için birden çok partitionda mesaj sırası garanti edilmez, ancak mesajın okunma sırası her bir partition içinde yine de garanti edilir.
Varsayılan olarak, Kafka consumerlar yalnızca Kafka'ya ilk kez bağlandıktan sonra üretilen verileri okurlar. Bu, Kafka'da tarihsel verileri okumak için, uygulama bölümünde göreceğimiz gibi, komutun girdisi olarak belirtilmesi gerektiği anlamına gelir.
Kafka consumerların bir "pull model" uyguladıkları da bilinmektedir. Bu, Kafka brokerlarn consumerlara sürekli olarak veri göndermesi yerine, Kafka consumerların veri okumak için Kafka brokerlarından veri talep etmesi gerektiği anlamına gelir. Bu uygulama, consumerların topiclerin okunma hızını kontrol edebilmeleri için yapılmıştır.
5.1. Mesaj Deserializer
Daha önce de gördüğümüz gibi Kafka producerlar tarafından gönderilen veriler önce serialize edilmekteydi. Bu sefer, Kafka consumerlar tarafından alınan verilerin uygulamanızda kullanılabilmesi için doğru şekilde deserializer edilmesi gerekir.
- Producer bir String'i
StringSerializerkullanarak serialize ettiyse, consumer'ınStringDeserializerkullanması gerekir - Producer bir Integer'i
IntegerSerializerkullanarak serialize ettiyse, consumer'ınIntegerDeserializerkullanması gerekir
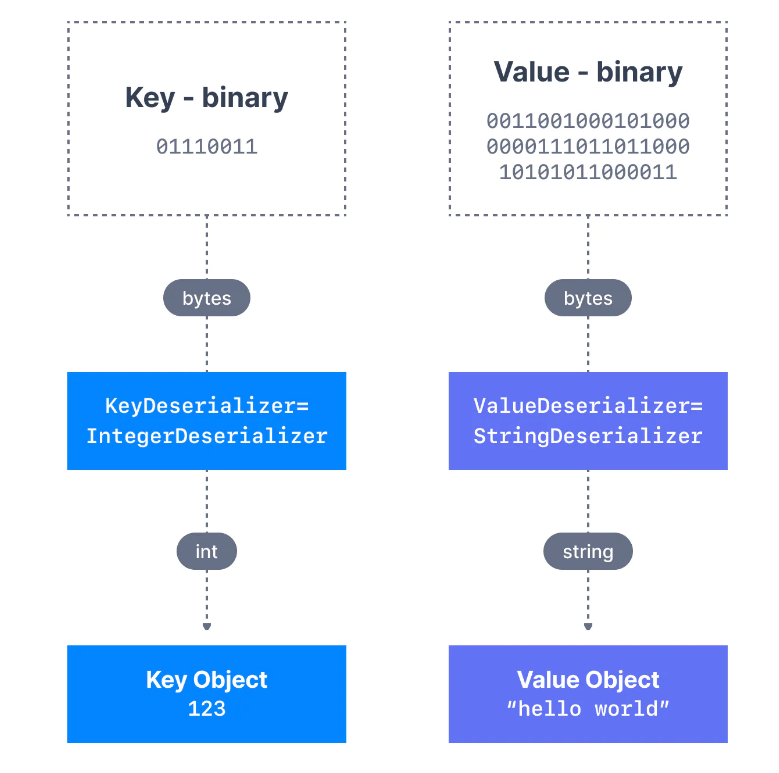
Bir topic'in serialize ve deserialize formatı, topic yaşam döngüsü boyunca değişmemelidir. Bir topic veri biçimini (örneğin JSON'dan Avro'ya) değiştirmeyi düşünüyorsanız, yeni bir topic oluşturmak ve bu yeni topic'ten yararlanmak için uygulamalarınızı taşımak en iyi uygulama olarak kabul edilir.
Doğru şekilde deserialize eilememesi, uygulamalarına flowun bozulmasına veya tutarsız verilere neden olabilir ve bu hataları ayıklamak zordur. Bu yüzden kodunuzu ilk kez yazarken bunu düşünmek en iyisidir.
6. Kafka Consumer Grupları ve Offset Nedir?
Consumerların Kafka topic partitionlarındaki verileri bireysel olarak consume ettiklerini gördük, ancak yatay ölçeklenebilirlik amacıyla Kafka topiclerinin grup olarak kullanılması önerilir.
6.1. Consumer Grupları
Aynı uygulamanın parçası olan ve dolayısıyla aynı "mantıksal işi" yapan consumerlar, bir Kafka consumer grubu olarak gruplandırılabilir.
Bir topic genellikle birçok partitiondan oluşur. Bu partitionlar, Kafka consumerlar için bir paralellik birimidir.
Bir Kafka consumer grubunu kullanmanın faydası, grup içindeki consumerların okuma işini farklı partitionlardan okuyacak şekilde koordine olacak olmasıdır.
6.2. Consumer Grup ID
Kafka consumerlara aynı belirli grubun parçası olduklarını belirtmek için, consumer tarafında group.id ayarını belirtmeliyiz.
Kafka consumerlar, consumerları bir partitiona atamak ve yük dengelemenin aynı gruptaki tüm consumerlar arasında gerçekleştirilmesini sağlamak için otomatik olarak bir GroupCoordinator ve bir ConsumerCoordinator kullanır.
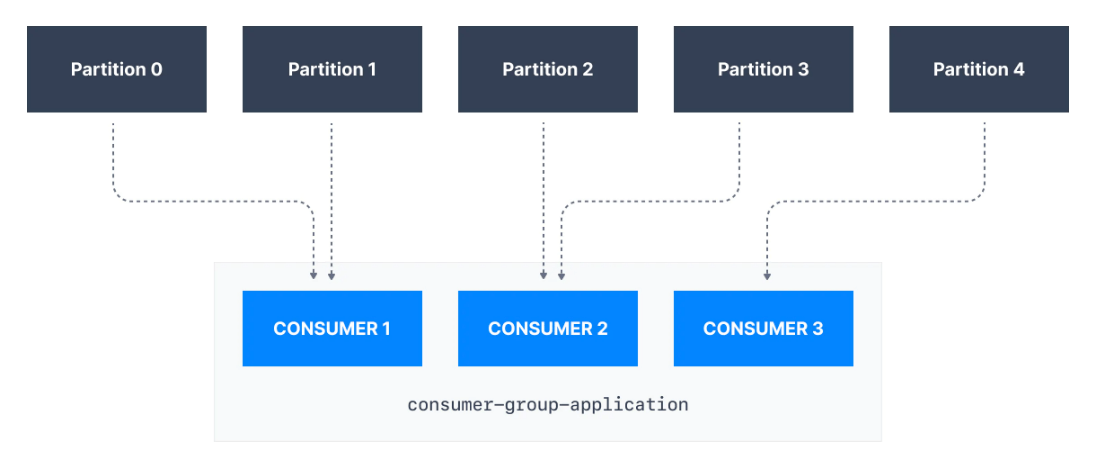
Her topic partition'ın, consumer grubu içindeki yalnızca bir consumera atandığını, ancak consumer grubundaki bir consumera birden çok partition atanabileceğini unutmayınız.
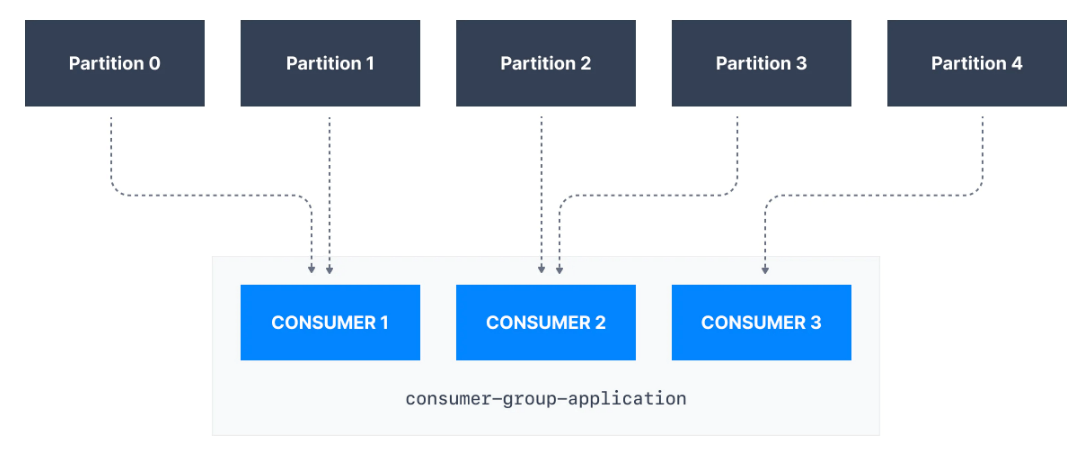
Yukarıdaki örnekte, consumer-group-application-1 consumer grubunun Consumer 1'ine Partition 0 ve Partition 1 atanırken, Consumer 2'ye Partition 2 ve Partition 3 atanır ve son olarak Consumer 3'e Partition 4 atanır. Bu sebeple Consumer 1 Partition 0 ve Partition 1'den, Consumer 2, Partition 2 ve Partition 3'ten ve Consumer 3, Partition 4'ten mesajlar alır.
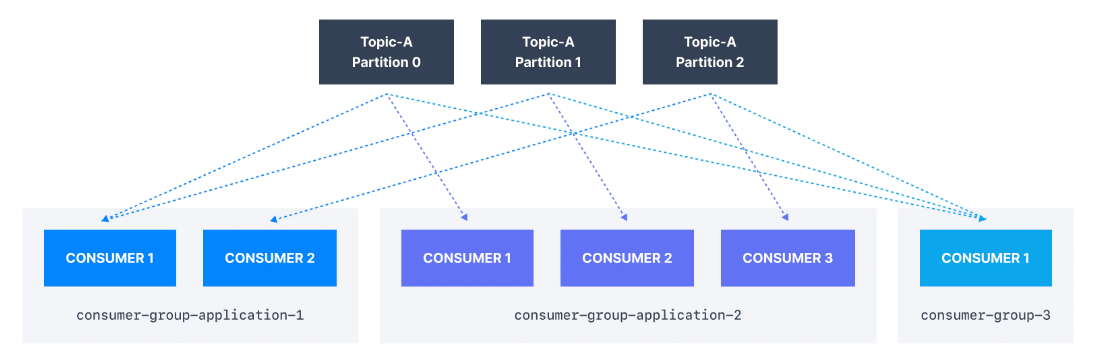
Kafka topiclerini okuyan uygulamalarınızın (consumer grupları) her biri (birçok consumerdan oluşabilir) farklı bir group.id belirtmelidir. Bu, birden fazla uygulamanın (consumer grubunun) aynı topicten aynı anda consume edebileceği anlamına gelir:
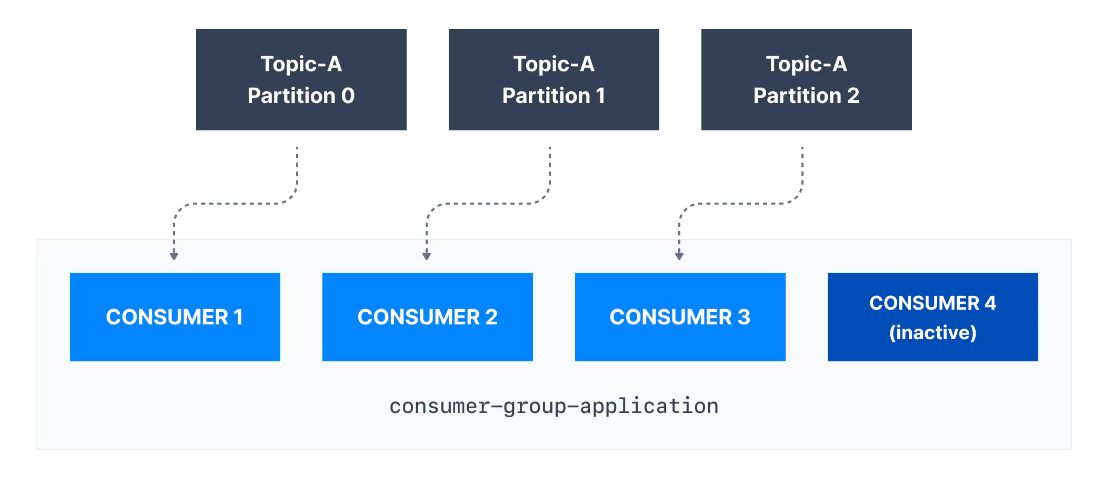
Bir topic'in partition sayısından daha fazla consumer varsa, bazı consumerlar aşağıda gösterildiği gibi pasif kalacaktır. Genellikle, bir consumer grubunda partition sayısı kadar consumer olur. Daha yüksek verim için daha fazla consumer istiyorsak, topic'i oluştururken daha fazla partition oluşturmalıyız. Aksi takdirde consumerların bir kısmı atıl kalabilir.
6.3. Consumer Offset
Kafka brokerlar, belirli bir consumer grubunun en son hangi iletileri başarıyla işlediğini takip eden __consumer_offsets adlı internal bir topic kullanır.
Bildiğimiz gibi, bir Kafka topic'teki her mesajın bir partition ID ve bir offset ID'si vardır.
Bu nedenle, bir consumer'ın bir topic partition'ının ne kadarını okuduğunu gösteren "checkpoint" değerini güncellemek için, consumer düzenli olarak en son işlenen mesajı commitler. Bu aynı zamanda consumer offset olarak da bilinir.
Aşağıdaki şekilde, consumer grubundan bir consumer, offset 4262'ye kadar mesajları consume etmiştir. Bu nedenle consumer offseti 4262 olarak ayarlanmıştır.
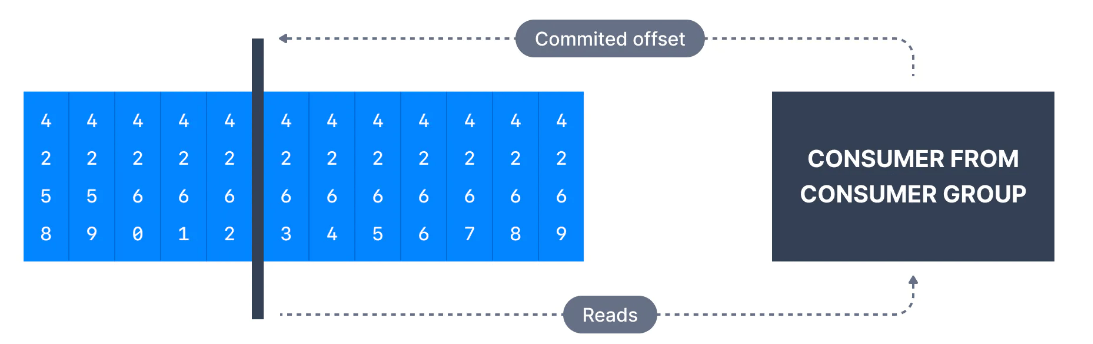
Client libraylerin çoğu sizin için periyodik olarak otomatik olarak Kafka'ya commitler atar ve sorumlu Kafka broker __consumer_offsets topic'e yazmayı sağlar. Bu nedenle consumerlar bu topic'e doğrudan yazamazlar.
Commit işlemi, consume edilen her mesaj için yapılmaz (çünkü bu verimsiz olur) ve bunun yerine periyodik olarak yapılır.
Belirli bir offsetin commitlenmesi, daha düşük bir offsete sahip önceki tüm mesajların da işlenmiş olarak kabul edildiği anlamına gelir.
6.3.1 Consumer Offsetleri Neden Kullanmalıyız?
Offsetler birçok uygulama için kritik öneme sahiptir. Bir Kafka consumer çökerse, yeniden dengeleme gerçekleşir ve en son kaydedilen offset, geri kalan Kafka consumerların mesajları okumaya ve işlemeye nereden yeniden başlayacaklarını bilmelerine yardımcı olur.
Bir gruba yeni bir consumer eklenmesi durumunda, başka bir consumer grubu yeniden dengeleme gerçekleştirir ve consumerlara verileri nereden okumaya başlayacaklarını bildirmek için consumer offset kullanılır.
Bu nedenle, consumer offsetler düzenli olarak commit edilmelidir.
6.3.2 Consumer Offset Semantiği
Varsayılan olarak Java consumerlar, .poll() çağrıldığında her auto.commit.interval.ms'de (varsayılan olarak 5 saniye) otomatik olarak offsetleri (enable.auto.commit=true özelliği tarafından kontrol edilir) commit eder.
Bu mekanizmanın ayrıntıları, Delivery Semantics for Consumers'de ele alınmıştır.
Bir consumer, offset commit'i kendisi yapmayı tercih edebilir (enable.auto.commit=false). Ne zaman commit etmeyi seçtiğine bağlı olarak, consumer'ın kullanabileceği 3 delivery semantikler vardır. Bunlar;
- At most once:
- Offsetler, mesaj alınır alınmaz işlenir.
- İşlem yanlış gider ve hata meydana gelirse mesaj kaybolur (tekrar okunmaz).
2. At least once: (tavsiye edilir)
- Offsetler, mesaj işlendikten sonra commitlenir.
- İşlem yanlış gider ve hata meydana gelirse, mesaj tekrar okunacaktır.
- Bu, iletilerin yinelenerek işlenmesine neden olabilir. Bu nedenle, veri işlemenin idempotent (yani aynı mesajı iki kez işlemek herhangi bir istenmeyen etki yaratmaz) olduğundan emin olmak gerekir.
3. Exactly once:
- Bu, yalnızca transactions API'si kullanılarak Kafka topic'ten Kafka topic'e workflow için elde edilebilir. Kafka Streams API'si, bu API'nin kullanımını basitleştirir ve
process.guarantee=exactly_once_v2(Kafka < 2.5'te tamexactly_once) ayarını kullanarak tam olarak bir kez etkinleştirir
7. Kafka Broker Nedir?
Tek bir Kafka sunucusuna Kafka Broker adı verilir. Kafka broker, Java Sanal Makinesi'nde (Java sürüm 11+) çalışan bir programdır ve genellikle Kafka broker olması amaçlanan bir sunucu yalnızca gerekli programı çalıştırır, başka hiçbir şeyi çalıştırmaz.
7.1. Kafka Broker ve Topic İlişkisi
Kafka brokerlar, verileri, üzerinde çalıştıkları sunucunun diskindeki bir dizinde depolar. Her topic partition, topic'in ilişkili adıyla kendi alt dizininde yer alır. Kafka'nın verileri nasıl depoladığına dair daha geniş bilgiyi ilerleyen yazılarımızda anlatacağız.
Topiclerde yüksek aktarım hızı ve ölçeklenebilirlik elde etmek için Kafka topicleri partitionlara ayrılır. Bir clusterda birden çok Kafka broker varsa, yük dengeleme ve ölçeklenebilirlik elde etmek için belirli bir topic'in partitionları brokerlar arasında eşit olarak dağıtılır.
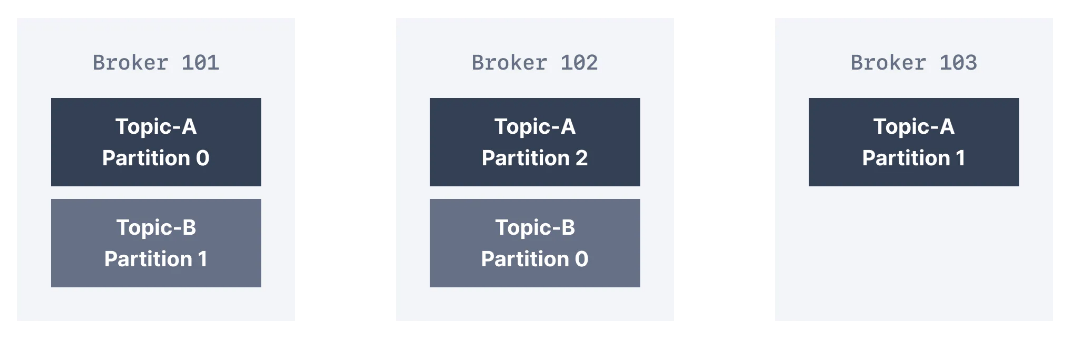
Yukarıdaki diyagramda, gösterilen iki topic vardır. Bunlar, cluster'ın kullanılabilir üç broker'ı arasında eşit olarak dağıtılır. Alternatif olarak, bir topic'in clusterdaki broker sayısından daha az (veya daha fazla) partition'ı olabilir.
Broker ID ile partition ID arasında bir ilişki yoktur. Kafka, partitionları kullanılabilir brokerlar arasında eşit olarak dağıtma konusunda iyi bir iş çıkarır. Belirli bir broker'in aşırı yüklenmesi nedeniyle cluster'ın dengesiz hale gelmesi durumunda, Kafka yöneticilerinin cluster'ı yeniden dengelemesi ve partitionları taşıması mümkündür.
7.2. Kafka Clientlar Bir Kafka Cluster'a Nasıl Bağlanır?
Kafka clusterdan ileti göndermek veya almak isteyen bir client, clusterdaki herhangi bir brokera bağlanabilir. Clusterdaki her broker'ın diğer tüm brokerlar hakkında meta verileri vardır ve client'ın de bunlara bağlanmasına yardımcı olur. Bu nedenle clusterdaki herhangi bir brokera bootstrap server da denir.
Bootstrap sunucusu, clusterdaki tüm brokerların listesinden oluşan bir meta verisini client'a döndürür. Daha sonra, gerektiğinde, client veri göndermek veya almak için tam olarak hangi brokera bağlanacağını bilecek ve hangi brokerların ilgili topic partition'da o veriyi içerdiğini doğru bir şekilde bulacaktır.
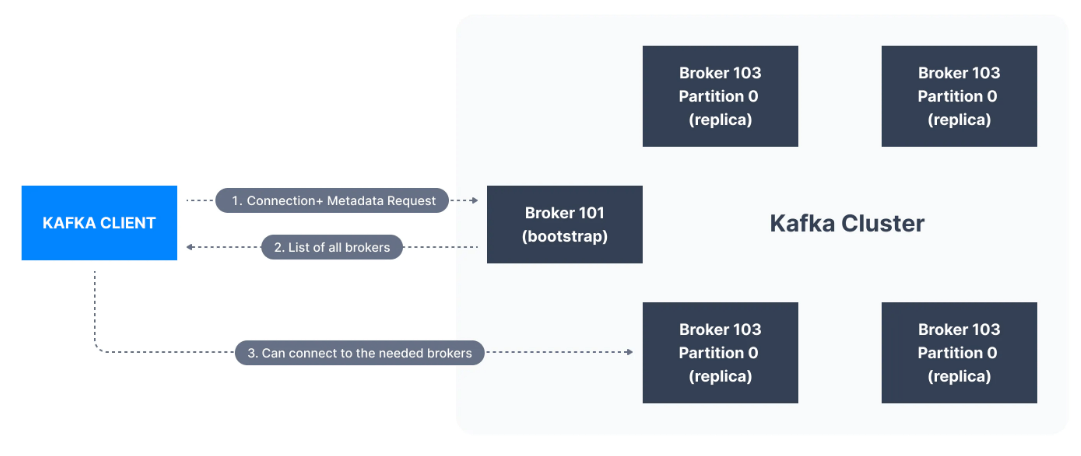
Pratikte, Kafka client'ın bağlantı URL'sinde en az iki bootstrap sunucusuna başvurması yaygın olan kullanımdır. Bunlardan birinin kullanılamaması durumunda, diğeri bağlantı isteğine yanıt vermelidir. Bu, Kafka clientların (ve geliştiricilerin/DevOps'un) Kafka clusterdaki her bir broker'ın adresinin farkında olması gerekmediği, yalnızca clientların bağlantı dizesinde iki veya üçünün farkında olması ve bunlara başvurması gerektiği anlamına gelir.
8. Kafka Cluster Nedir?
Birlikte çalışan Kafka brokerlar topluluğuna Kafka Cluster denir. Bazı clusterlar yalnızca bir broker içerirken bazıları da üç veya potansiyel olarak yüzlerce broker içerebilir. Netflix ve Uber gibi şirketler, verilerini işlemek için yüzlerce veya binlerce Kafka brokeri çalıştırıyor.
Clusterdaki bir broker, benzersiz bir sayısal kimlikle tanımlanır. Aşağıdaki şekilde, Kafka cluster üç Kafka brokerdan oluşur.

9. Kafka Stream Nedir?
Harici sistemlerden Kafka'ya veri ürettikten sonra, stream processing uygulamalarını kullanarak bunları işlemek isteyebiliriz. Stream processing uygulamaları, gerçek zamanlı analitik sağlamak için Apache Kafka gibi stream veri depolarından yararlanırlar.
Örneğin, Twitter'daki tüm tweet'lerin data stream'i olan twitter_tweets adlı bir Kafka topic başlığımız olduğunu varsayalım. Bu topic'te şunları yapmak isteyebiliriz:
- Önemli tweet'leri yakalamak için yalnızca 10'dan fazla beğeni veya yanıtı olan tweet'leri filtrelemek
- Her hashtag için her 1 dakikada bir alınan tweet sayısını saymak
- Trend olan konuları ve etiketleri gerçek zamanlı olarak almak için ikisini birleştirmek
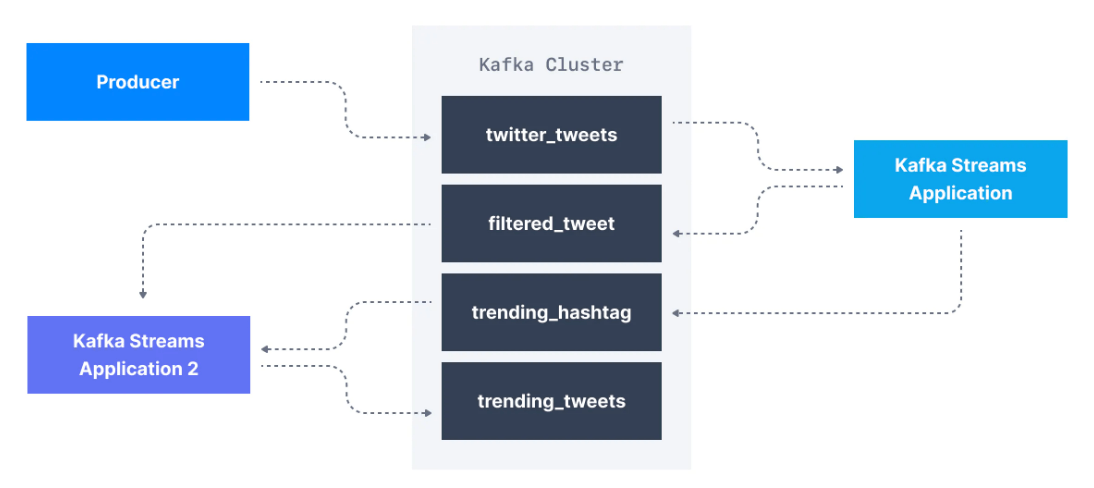
Apache Kafka'da topic düzeyinde transformation gerçekleştirmek için, çok karmaşık producer ve coınsumer kodu yazmak yerine bu kullanım senaryosu için tasarlanmış stream libraryler kullanabiliriz.
Bu senaryoda, Apache Kafka ile birlikte yayınlanan bir stream processing framework olan Kafka Streams libraryden yararlanabiliriz. Kafka Streams için duymuş olabileceğiniz alternatifler, Apache Spark veya Apache Flink'tir.
10. Kafka Connect Nedir?
Apache Kafka'ya veri yazmak için Kafka producerlardan yararlanmamız gerektiğini gördük. Zamanla, birçok şirketin aynı veri kaynağı türlerini (veritabanları, sistemler vb.) kulandığı ve bu nedenle açık kaynak standartlaştırılmış kod yazmanın daha iyi ve yardımcı olabileceği fark edildi. Aynı düşünce Kafka consumerlar için de geçerli.
Kafka Connect, popüler sistemleri Kafka ile entegre etmemizi sağlayan bir araçtır. Verileri Kafka'ya yazmak ve Kafka'dan diğer veri depolarına veri aktarmak için mevcut bileşenleri yeniden kullanmamıza olanak tanır.
Popüler Kafka connector örnekleri şunlardır;
- Kafka Connect Source Connector (producerlar): Veritabanları (Debezium connector aracılığıyla), JDBC, Couchbase, GoldenGate, SAP HANA, Blockchain, Cassandra, DynamoDB, FTP, IOT, MongoDB, MQTT, RethinkDB, Salesforce, Solr, SQS, Twitter, vb. …
- Kafka Connect Sink Connector (consumerlar): S3, ElasticSearch, HDFS, JDBC, SAP HANA, DocumentDB, Cassandra, DynamoDB, HBase, MongoDB, Redis, Solr, Splunk, Twitter

11. Kafka Topic Replication Nedir?
Kafka'nın popülaritesinin ana nedenlerinden biri de, broker hataları karşısında sunduğu esnekliktir. Makineler arızalanır ve çoğu zaman bunun ne zaman olacağını tahmin edemez veya önleyemeyiz. Kafka, uptime ve veri doğruluğunu korurken bu hatalara dayanacak temel bir özellik olarak replication ile tasarlanmıştır.
11.1. Kafka Topic Replikasyon Faktör
Replikasyon, aynı veriyi birden fazla broker'a yazarak veri kaybını önlemeye yardımcı olur.
Kafka'da replikasyon, verilerin yalnızca bir broker'a değil, birçok broker'a yazılması anlamına gelir.
Replikasyon faktör ise bir topic ayarıdır ve topic oluşturma zamanında belirtilir.
- Replikasyon faktör
1olduğunda, replikasyon olmadığı anlamına gelir. Çoğunlukla geliştirme amacıyla kullanılır. Production ortamındaki Kafka clusterlarda bu değerden kaçınılmalıdır. - Replikasyon factor
3, broker kaybı ile replication overhead'i arasında doğru dengeyi sağladığı için yaygın olarak kullanılan bir değerdir.
Üç brokerdan oluşan aşağıdaki clusterda, replikasyon faktör 2'dir. Bir ileti Broker 101'de Topic-A'nın Partition 0'ına yazıldığında, replikasyon olarak Partition 0'a sahip olduğu için Broker 102'ye de yazılır.
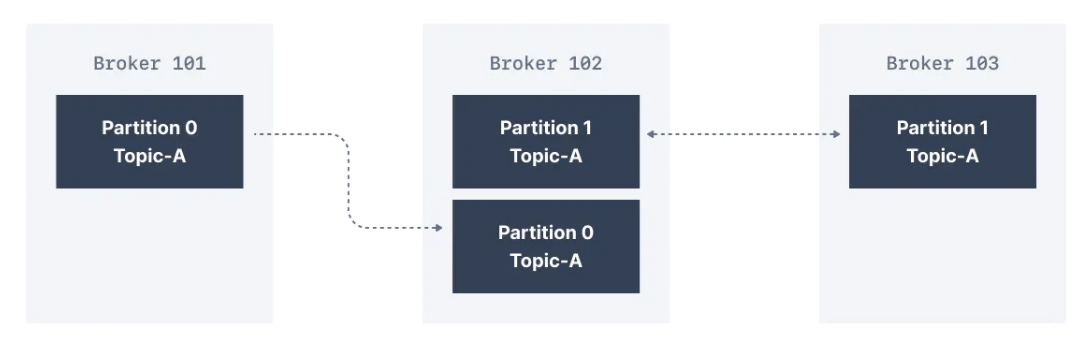
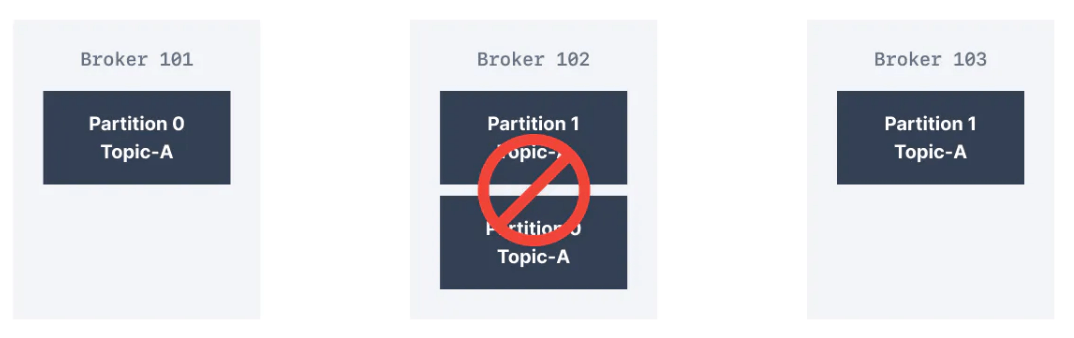
2 olan bir replikasyon faktör sayesinde, bir broker'ın hata durumuna dayanabiliriz. Bu, aşağıda gördüğünüz gibi Broker 102 hata verirse, Broker 101 ve Broker 103'ün hala ilgili verilere sahip olacağı anlamına gelir.
11.2. Kafka Partition Lider ve Replika Nedir?
Belirli bir topic partition için, cluster tarafından clientlara veri gönderme ve alma işlemlerinden sorumlu olmak üzere bir Kafka broker atanır. Bu broker, ilgili topic partition'ın lider broker'ı olarak bilinir. Bu partition için replika verileri depolayan diğer tüm brokerlara ise replika adı verilir.
Bu nedenle, her partition'ın bir lideri ve birden çok replikası vardır.
11.3. In-Sync Replika (ISR) Nedir?
ISR, bir parition'ın lider broker'ıyla güncel olan bir replikadır. Liderle güncel olmayan herhangi bir replica in-sync sayılmaz.
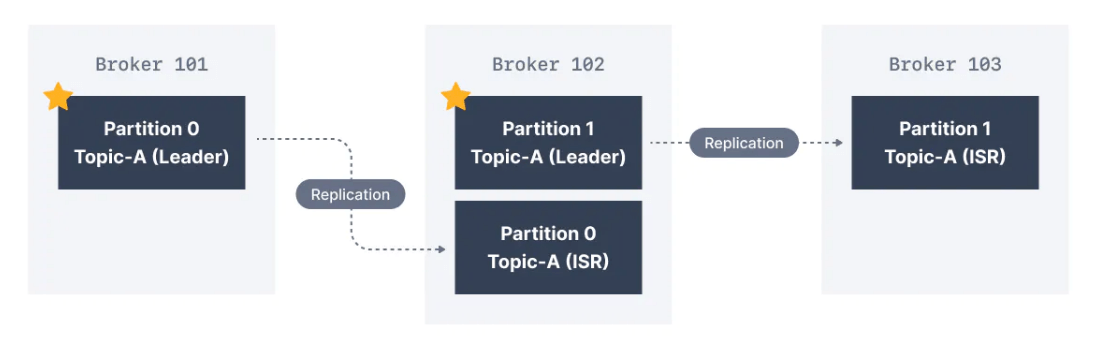
Burada Partition 0 lideri olarak Broker 101 ve Partition 1'in lideri olarak Broker 102 var. Broker 102, Partition 0 için bir replikadır ve Broker 103, Partition 1 için bir replikadır. Lider broker başarısız olursa, replikalardan biri bir seçimle yeni partition lideri olarak seçilecektir.
11.4. Kafka Producer ACKS Ayarları
Kafka producerlar yalnızca bir partition için geçerli lider broker'a veri yazar.
Kafka producerlar, iletinin başarılı bir yazma olarak kabul edilmeden önce en az sayıda replikasyona yazılması gerekip gerekmediğini belirtmek için bir acks düzeyi de belirtmelidir.
acks'nin varsayılan değeri Kafka v3.0 ile değiştirildi.* Kafka < v3.0 kullanıyorsanız,
acks=1* Kafka >= v3.0 kullanıyorsanız,
acks=allacks=0
acks = 0 producerlar, iletinin broker'ın kabul etmesini beklemeden gönderildiği anda iletileri "başarıyla yazılmış" olarak kabul eder.

Broker çevrimdışı olursa veya bir hata olursa, bunu bilemeyiz ve veriyi kaybederiz. Bu, metric toplama gibi iletileri kaybetme olasılığının yüksek olduğu veriler için kullanışlıdır ve ağ yükü en aza indirildiğinden en yüksek aktarım hızını elde ederiz.
acks=1
acks=1 olduğunda, producerlar mesaj yalnızca lider tarafından onaylandığında iletileri "başarıyla yazılmış" olarak kabul eder.

Bu ayarda lider yanıtı istenir, ancak replikasyon garanti değildir. Bir ack alınmazsa, producer isteği yeniden deneyebilir. Lider broker beklenmedik bir şekilde çevrimdışı olursa, ancak replikalar verileri henüz replika etmediyse, veri kaybımız olur.
acks=all
acks=all olduğunda, producerlar ileti tüm in-sync replikalar (ISR) tarafından kabul edildiğinde iletileri "başarıyla yazılmış" olarak kabul eder.
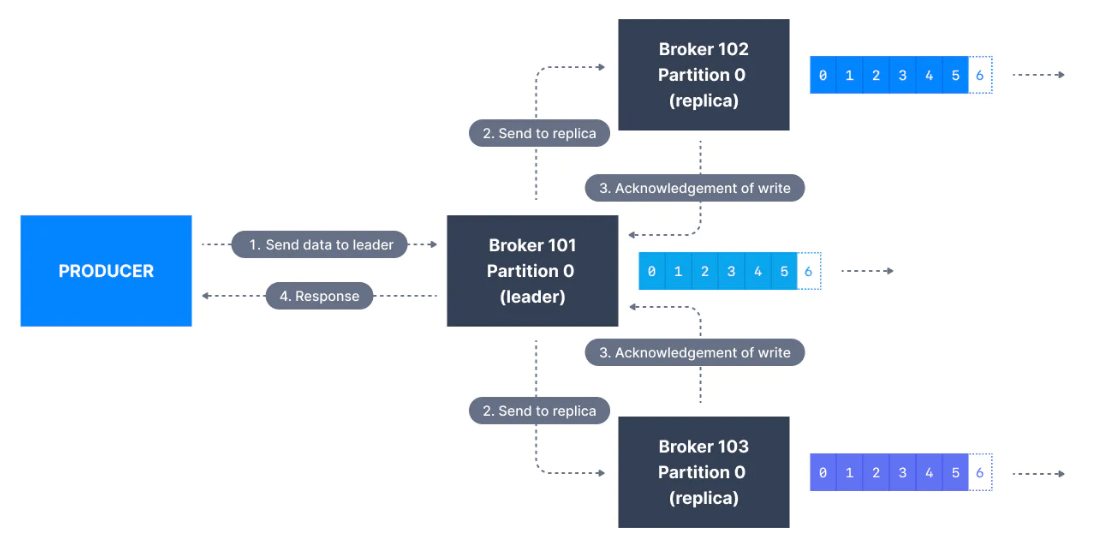
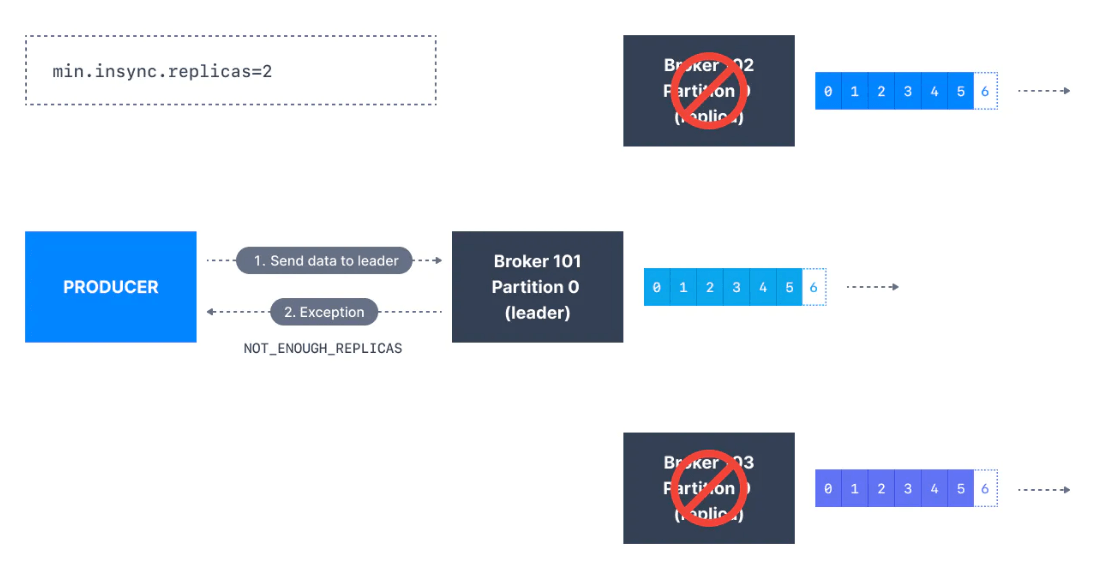
Bir partition'ın lider replikası, iletiyi güvenli bir şekilde yazmak için yeterli in-sync replika olup olmadığını denetler (min.insync.replicas ayarı ile ayarlanır). Lider, replikaların iletiyi çoğalttığını gözlemleyene kadar istek bir arabellekte depolanır ve bu noktada client'a başarılı bir onay gönderilir.
min.insync.replicas hem topic hem de broker düzeyinde yapılandırılabilir. Veriler, tüm replikalara (min.insync.replicas) yazıldığında kaydedilmiş olarak kabul edilir. 2 değeri, ISR (lider dahil) olan en az 2 broker'ın verilere sahip olduklarını yanıtlaması gerektiğini ima eder.
Commit edilen verilerin birden fazla replikaya yazıldığından emin olmak istiyorsanız, en düşük in-sync replika sayısını daha yüksek bir değere ayarlamanız gerekir. Bir topic'in üç replikası varsa ve min.insync.replicas ayarını 2 olarak ayarlarsanız, yalnızca üç replikadan en az ikisi in-sync olan topicteki bir partition'a yazabilirsiniz.
11.5. Kafka Topic Durability & Availability
3 değerine sahip bir topic replikasyon faktör için, topic durability, 2 broker'ın kaybına dayanabilir. Genel bir kural olarak, replikasyon faktörün N olması durumunda , N-1 broker'ın kaybına kadar verilerinizi kurtarmaya devam edebilirsiniz.
Availability ise biraz daha karmaşık bir durumdur. Örnek vermek gerekirse, 3 değerine sahip bir topic replikasyon faktörü ele alalım:
- Okuma İşlemleri: Bir partition ayakta olduğu ve ISR olarak kabul edildiği sürece, topic okumalar için kullanılabilir olacaktır
- Yazma İşlemleri:
-
acks=0&acks=1: Bir partition ayakta olduğu ve ISR olarak kabul edildiği sürece, topic yazma işlemleri için kullanılabilir olacaktır.
-
acks=all
-
-
min.insync.replicas=1(varsayılan): Topic'in ISR olarak en az 1 bölümü olmalıdır (okuyucuyu içerir) ve böylece iki broker'ın down olmasına tahammül edebiliriz.
-
-
-
min.insync.replicas=2: Topic'in en az 2 ISR'si up olmalıdır ve bu nedenle en fazla bir broker'ın down olmasına tahammül edebiliriz (replikasyon faktörü 3 durumunda) ve her yazma için verilerin en az iki kez yazılacağını garanti ederiz.
-
-
-
min.insync.replicas=3: Bu, karşılık gelen 3 replikasyon faktörü için pek bir anlam ifade etmez ve herhangi bir broker'ın düşmesine tahammül edemezdik.
-
-
-
- Özetle,
acks=all,replication.factor=Nvemin.insync.replicas=Molduğunda,N-Mbrokerlarının topic kullanılabilirliği amacıyla down inmesine tahammül edebiliriz.
- Özetle,
-
acks=all ve min.insync.replicas=2, durability ve availability için en popüler seçenektir ve en fazla bir Kafka broker'ın kaybına dayanmanıza olanak tanır11.6. Kafka Replika İşleme
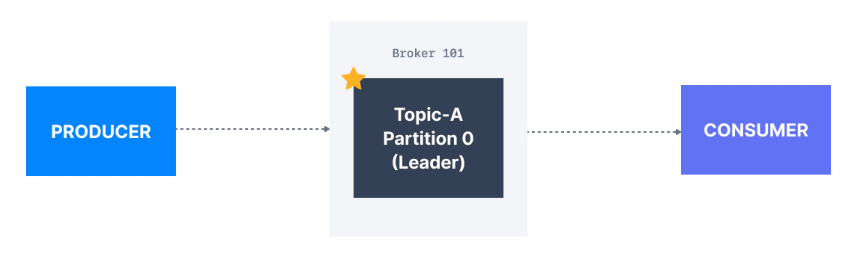
Kafka consumer varsayılan olarak partition liderinden okur.
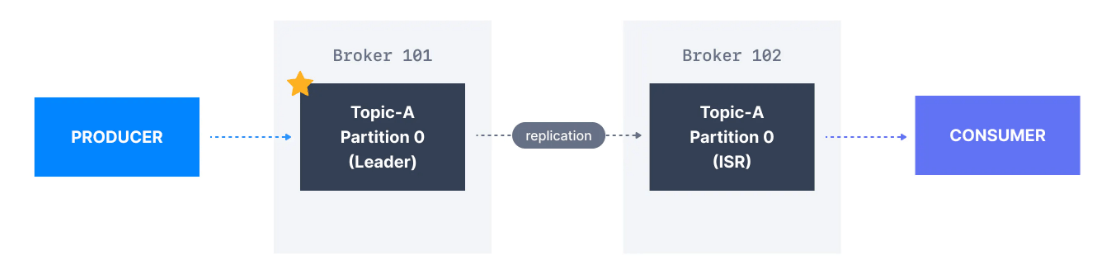
Ancak Apache Kafka 2.4'ten bu yana, consumerları bunun yerine in-sync replikalardan (genellikle en yakını) okuyacak şekilde yapılandırmak mümkündür.
En yakın in-sync replikadan (ISR) okumak, istek gecikmesini azaltabilir ve çoğu bulut ortamında veri merkezleri arası ağ istekleri ücrete tabi olduğundan ağ maliyetlerini de azaltabilir.
11.7. Tercih Edilen Lider
Tercih edilen lider, topic oluşturma zamanında bir partition için belirlenmiş lider broker'dır.
Tercih edilen lider down olduğunda, ISR (in-sync replika) olan herhangi bir partition yeni bir lider olmaya hak kazanır. Tercih edilen lider broker'ını kurtardıktan ve bölüm verilerini tekrar senkronize ettikten sonra, tercih edilen lider bu partition için liderliği geri alır.
12. Kafka ve Zookeeper
Zookeeper, cluster durumunu, üyeliği ve liderliği izlemek için kullanılır.
0.x, 1.x ve 2.x Zookeeper kullanmalıdır2. Kafka
3.x, Zookeeper (KIP-500) olmadan çalışabilir ancak henüz production ortamı için hazır değildir3. Kafka
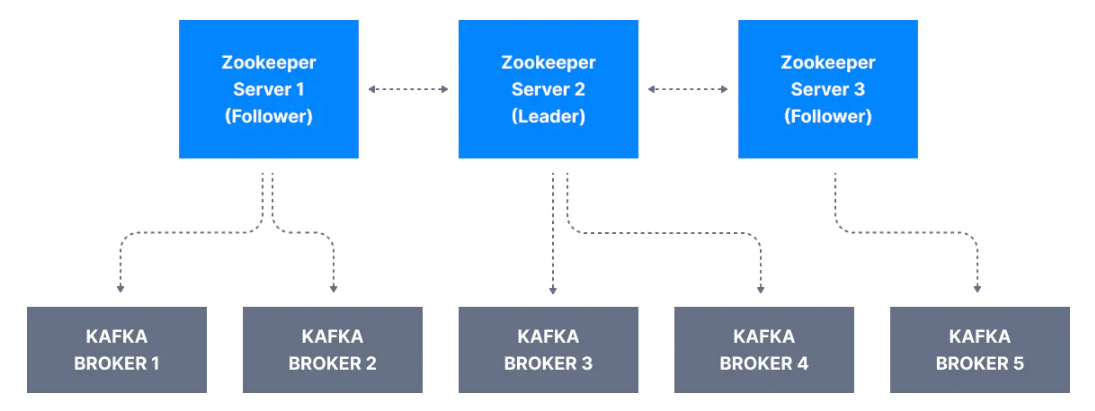
4.x'te Zookeeper olmayacakBirden fazla broker olduğunda, Kafka brokerlar ve clientlar tüm Kafka brokerları nasıl takip eder? Bu zor bir durumdur. Bu sebeple Kafka ekibi Zookeeper'ı kullanıma sokmuştur.
Zookeeper, Kafka dünyasında meta veri yönetimi için kullanılır. Mesela:
- Zookeeper, hangi brokern hangi clusterın parçası olduğunu izler
- Zookeeper, Kafka brokerlar tarafından hangi brokerın belirli bir partion ve topic'in lideri olduğunu belirlemek ve lider seçimleri gerçekleştirmek için kullanılır.
- Zookeeper, topicler ve izinler için yapılandırmaları depolar
- Zookeeper, değişiklik durumunda Kafka'ya bildirimler gönderir (örneğin, yeni topic geldiğinde, broker up veya down olduğunda, broker eklendiğinde, topic silindiğinde vb.)
Bir Zookeeper clustera topluluk denir. Topluluğun 3, 5, 7 gibi tek sayıda sunucuyla çalıştırılması önerilir. Çünkü topluluk üyelerinin büyük bir çoğunluğu (quorum) Zookeeper'ın taleplerine cevap verebilmesi için çalışıyor olmalıdır. Zookeeper'ın yazma işlemlerini işlemek için bir lideri vardır. Sunucuların geri kalanı okumaları işlemek içindir.
12.1. Zookeeper'ı Kafka Brokerlarla Birlikte Kullanmalı mıyız?
Zookeeper'sız Kafka production için hazır olmadığı sürece (4.x versiyonunda bekleniyor), Apache Kafka için production ortamınızda Zookeeper kullanmanız gerekir.
12.2. Zookeeper'ı Kafka Client'larla Birlikte Kullanmalı mıyız?
Zamanla, Kafka clientları ve CLI, brokerları Zookeeper yerine bir bağlantı uç noktası olarak kullanmak üzere transfer edilmiştir.
Bu, şu anlama gelir:
- Kafka 0.10'dan bu yana, consumerlar Kafka ve Zookeeper'da offset depolar ve bu seçenek kullanımdan kaldırıldığı için Zookeeper'a bağlanmamalıdır.
- Kafka 2.2'den bu yana,
kafka-topics.shCLI komutu, topic yönetimi (oluşturma, silme vb.) için Zookeeper'a değil, Kafka broker'a başvurur ve Zookeeper CLI argümanı kullanımdan kaldırılmıştır. - Daha önce Zookeeper'dan yararlanan tüm API'ler ve komutlar Kafka kullanmak üzere yükseltilebilir, böylece clusterlar Zookeeper'dan koparıldığında değişiklik istemcilere görünmez.
- Zookeeper Kafka'dan daha az güvenlidir ve bu nedenle Zookeeper bağlantı noktaları Kafka clientlardan değil, yalnızca Kafka brokerlardan gelen trafiğe izin vermek için açılmalıdır.
Bu nedenle, güncel bir Kafka geliştiricisi olmak için, Zookeeper'ı Kafka clientlarınızda ve Kafka'ya bağlanan diğer programlarda asla bir yapılandırma olarak kullanmayın.
12.3. Zookeeper Neden Kaldırılıyor?
Kafka projesi, KIP-500'ün piyasaya sürülmesiyle en büyük değişikliklerinden birini gerçekleştirdi. Artık Apache Kafka'nın Zookeeper bağımlılığını ortadan kaldırılması en büyük arzu konumunda.
Zookeeper performans sorunları ve aşağıdaki sınırlamalara sahip olduğu olduğu için kaldırılması planlanmıştır:
- Kafka clusterlar yalnızca sınırlı sayıda partition'ı destekler (200.000'e kadar)
- Bir Kafka broker bir cluster'a katıldığında veya cluster'dan ayrıldığında, Zookeeper'ı aşırı yükleyebilecek ve cluster'ı geçici olarak yavaşlatabilecek çok sayıda lider seçimi yapılmalıdır.
- Kafka clusterların kurulumu zordur ve kurulum için başka bir bileşene bağlıdır
- Kafka cluster meta verileri bazen Zookeeper'dan eşitlenmiyor
- Zookeeper güvenliği Kafka güvenliğinin gerisinde kalıyor
12.4. Zookeeper KRaft Mod Nedir?
KIP-500'ün bir parçası olarak, Kafka'nın meta verilerinin kendisinin bir log olduğu ve Kafka brokerlarınn bu meta loglarını dahili bir meta veri konusu olarak kullanabilmeleri gerektiği belirtilmiştir.
Zookeeper'ı kaldırmak için, Kafka Raft protokolünü kullanarak quorum da kendi seçimini gerçekleştirebilir. Bu yeni özelliğe de KRaft (Kafka Raft) adı verilir.



