Apache Kafka Nedir?
Apache Kafka, akış verilerini gerçek zamanlı olarak almak ve işlemek için optimize edilmiş dağıtılmış bir veri deposudur.


Apache Kafka, data streaming söz konusu olduğunda akla gelen ilk isimdir. Kafka, sunucu ve istemcilerden oluşan açık kaynaklı bir sistemdir ve akış verilerini gerçek zamanlı olarak almak ve işlemek için optimize edilmiş bir veri deposudur.
Apache Kafka, dünyanın önde gelen binlerce kuruluşu tarafından yüksek performanslı data streaming, streaming analizi, data integration ve diğer birçok hayati uygulama için kullanılmaktadır.
Data Integration Katmanı Olarak Kafka
Tipik bir kuruluş; muhasebe, faturalandırma, CRM, web siteleri vb. gibi çeşitli uygulamalar aracılığıyla veri toplar. Bu uygulamaların her birinin veri girişi ve güncellemesi için kendi süreçleri vardır. Tüm bu işlerin ortak bir analizini elde etmek için, mühendislerin bu farklı uygulamalar arasında entegrasyonlar geliştirmeleri gerekir.
Bu doğrudan entegrasyonlar, aşağıda gösterildiği gibi karmaşık bir çözümle sonuçlanabilir.
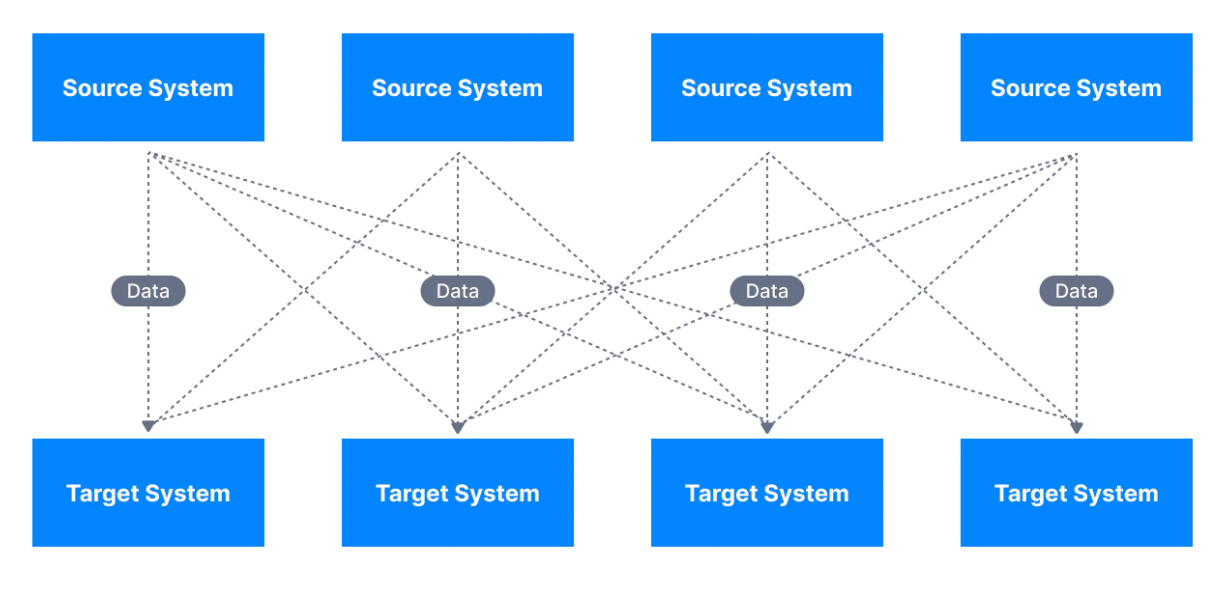
Her entegrasyon esasında zorluklarla birlikte gelir. Bu zorlukların temelinde şu üç bileşen yatmaktadır;
- Protokol – verilerin nasıl taşındığı (TCP, HTTP, REST, FTP, JDBC...)
- Veri tipi – verilerin nasıl parse edildiği (Binary, CSV, JSON, Avro...)
- Veri şeması ve evrimi – verilerin nasıl şekillendiği ve değişebileceği
Apache Kafka bir data integration katmanı olduğunda, veri kaynakları verilerini Apache Kafka'ya gönderir ve hedef sistemler verilerini Apache Kafka'dan alır. Bu sistem, kaynak veri akışlarını ve hedef sistemleri birbirirnden ayırır ve aşağıdaki diyagramda görebileceğiniz gibi basitleştirilmiş bir data integration çözümüne izin verir.

Data Streaming Katmanı Olarak Kafka
Data streaming, genellikle potansiyel olarak sınırsız bir veri dizisi olarak düşünülebilir.
Verilerin oluşturulduğu bir kuruluştaki uygulamaların her biri, potansiyel bir veri streaming oluşturucusudur. Data streaming'in bir parçası olarak oluşturulan veriler genellikle küçük ve değişkendir. Bazı streamler saniyede on binlerce kayıt alırken, bazıları saatte bir veya iki kayıt alır.
Apache Kafka, bu data streamleri (topic olarak da adlandırılır) depolamak için kullanılır ve bu da daha sonra sistemlerin streamleri işlemesine olanak tanır. Stream, Apache Kafka'da işlenip depolandıktan sonra başka bir sisteme, örneğin bir veritabanına aktarılabilir.
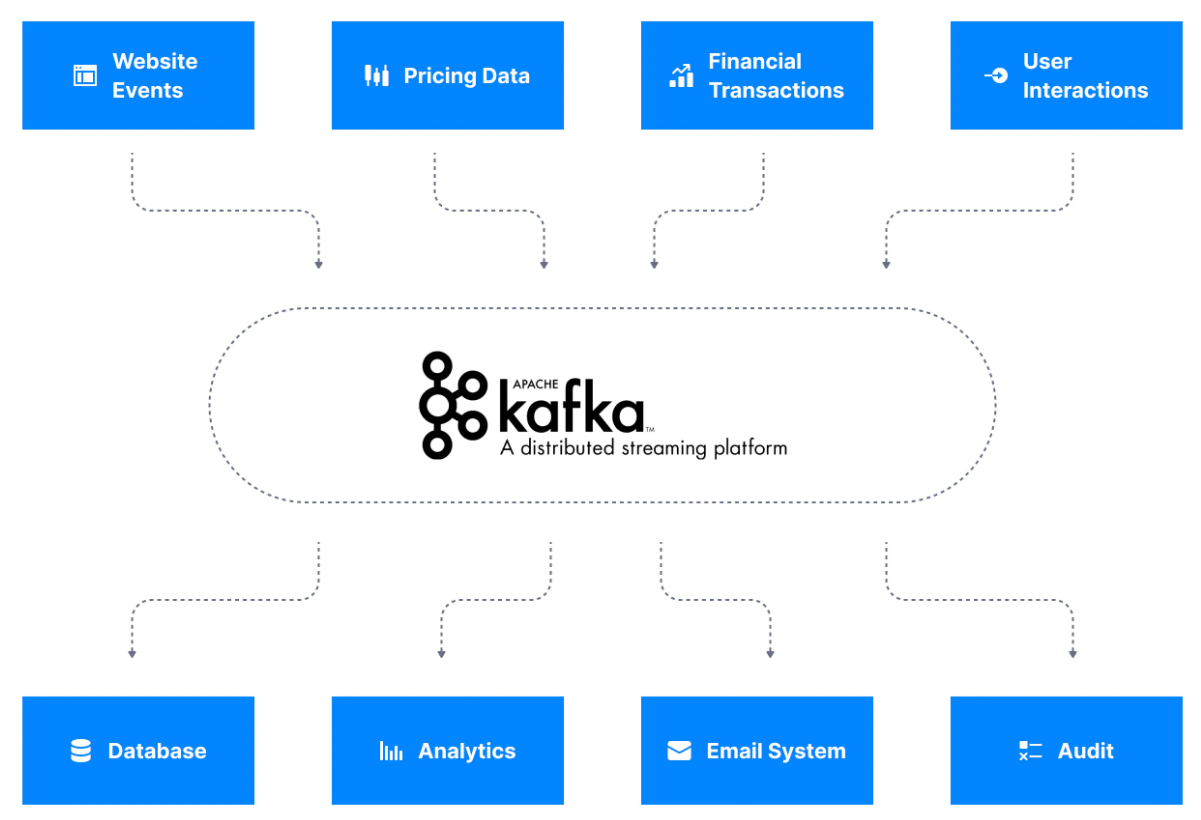
Data stream Örnekleri
Aşağıda, şirketlerin gerçek dünyada işlediği bazı data streamlere örnekler verilmiştir.
- Log Analizi. Modern uygulamalar, tümü sürekli olarak log üreten on ila binlerce mikroservice içerir. Bu loglar, business logic, failure prediction ve debugging için gerekli bilgilerle doludur. O halde buradaki zorluk, üretilen bu büyük hacimli log verilerinin tek bir yerde nasıl işleneceğidir. Şirketler, stream processing gerçekleştirmek için log verilerini bir data streame aktarır.
- Web analizi. Data streaming için başka bir yaygın kullanım web analitiğidir. Modern web uygulamaları, sitelerindeki buton tıklamaları, sayfa görüntülemeleri gibi hemen hemen her kullanıcı etkinliğini ölçer. Bu eylemler hızla toplanır. Stream processing, şirketlerin verileri saatler sonra değil, oluşturuldukları gibi işlemesine olanak tanır.
Neden Apache Kafka Kullanmalıyız?
Bir kuruluşun real-time data streaming ihtiyaçları olur olmaz, bir streaming platformu kurulmalıdır.
Apache Kafka, bugün endüstrideki en popüler data streaming platformlarından biridir ve Fortune 100 şirketlerinin %80'inden fazlası tarafından kullanılmaktadır. Kafka, yüksek düzeyde ölçeklenebilir ve node kaybı gibi failover durumlarına karşı dayanıklıdır.
Kafka cluster, yalnızca bir node'dan binlerce node'a kadar değişen boyutlarda oluşturulabilir. LinkedIn'in yanı sıra Netflix, Apple, Uber, Airbnb gibi şirketler iş yüklerinde yoğun olarak Kafka kullanmaktadır. Kafka'nın yaratıcıları, tam zamanlı olarak Kafka ve ekosistemine odaklanmak için Confluent adlı kendi şirketlerini kurmak üzere LinkedIn'den ayrılmıştır. Apache Kafka artık Confluent tarafından yürütülen açık kaynaklı bir projedir.
Apache Kafka'nın Tarihi
Kafka, geleneksel mesaj queuw sistemleriyle karşılanamayan stream processing gereksinimlerine hizmet vermek için LinkedIn'de tarafından oluşturulmuştur. İlk versiyonu Ocak 2011'de yayınlanana Kafka, hızla popülerlik kazandı ve o zamandan beri Apache Vakfı'nın en popüler projelerinden biri haline geldi.
Proje şu anda IBM, Yelp, Netflix ve benzeri diğer şirketlerin yardımıyla ağırlıklı olarak Confluent tarafından sürdürülüyor.
Apache Kafka'nın Kullanım Senaryoları Nelerdir?
Apache Kafka'nın kullanım senaryosu oldukça fazladır. Bunlar, farklı business uygulamaları için stream processingi içerir. Fakat temelde Apache Kafka; Apache Flink, Samza gibi önde gelen bazı stream processing frameworkleri için depolama mekanizmasını oluşturur.
Apache Kafka'nın kullanıldığı bazı senaryolar şu şekildedir;
- Mesajlaşma sistemleri
- Activity tracking
- Event-source tracking
- IoT cihazları gibi birçok farklı konumdan ölçüm toplama
- Log analizi
- Spark, Flink, Storm, Hadoop gibi Big Data teknolojileri ile entegrasyon
Kullanım senaryolarının bir listesini https://kafka.apache.org/uses adresinde bulabilirsiniz.
Apache Kafka'nın Uygun Olmadığı Durumlar
Apache Kafka, yukarıda özetlenen kullanım senaryoları için çok uygundur, ancak Apache Kafka kullanımının mümkün olmadığı veya tavsiye edilmediği birkaç kullanım senaryosu da vardır:
- Mobil uygulamalar veya IoT için milyonlarca istemcide proxy olarak kullanılması: Kafka protokolü bunun için yapılmadı, ancak boşluğu kapatmak için bazı proxy'ler mevcut.
- Indexlere sahip bir veritabanı: Kafka, built-in analitik yeteneği ve karmaşık sorgu modeli olmayan bir event streaming sistemidir.
- IoT için gömülü real-time bir teknoloji: Gömülü sistemlerde bu kullanım durumlarını gerçekleştirmek için daha düşük seviyeli ve daha hafif alternatifler mevcut.
- İş kuyrukları: Kafka, kuyruklardan değil topiclerden oluşur (RabbitMQ, ActiveMQ, SQS'den farklı olarak). Kuyruklar, milyonlarca consumera ölçeklendirmek ve işlendikten sonra mesajları silmek içindir. Kafka'da veriler işlendikten sonra silinmez ve consumerlar topic partition sayısının ötesine ölçeklenemez.
- Bir blokchain olarak Kafka: Kafka topicler, verilerin loga eklendiği bir blok zincirinin bazı özelliklerini sunar ve Kafka topicleri değişmez olabilir, ancak verilerin kriptografik doğrulaması ve tüm geçmişi saklama gibi blok zincirlerinin bazı temel özelliklerinden yoksundur.
Yazı serimize Apache Kafka kurulumu ile devam edebilirsiniz.




