Terraform State Nedir? Nasıl Yönetilir?
Terraform state, altyapınızın güncel durumunu takip eden ve bildiren bir mekanizmadır.


Terraform'u her çalıştırdığınızda, hangi altyapının oluşturulduğu ve hangi durumda olduğu bilgilerini Terraform state dosyası kaydeder. Bu yazıda Terraform state kullanım detaylarını ve pratiklerini göreceğiz.
Terraform ile resource'ları oluşturmak ve güncellemek için terraform plan veya terraform appy komutlarını her çalıştırdığınızda, Terraform'un daha önce oluşturduğu resource'ları bulabildiğini ve buna göre güncelleyebildiğini fark etmiş olabilirsiniz. Ama Terraform hangi resource'ları yönetmesi gerektiğini nasıl bildi? AWS hesabınızda çeşitli mekanizmalar (bazıları manuel, bazıları Terraform aracılığıyla, bazıları CLI aracılığıyla) aracılığıyla dağıtılan her türlü altyapıya sahip olabilirsiniz, peki Terraform hangi altyapıdan sorumlu olduğunu nasıl biliyor?
Bu yazıda, Terraform'un altyapınızın durumunu ve dosya düzeni, izolasyon ve locking üzerindeki etkisini nasıl izlediğini göreceksiniz. İşte üzerinde duracağımız ana konular:
- Terraform state nedir?
- State dosyaları için paylaşımlı depolama
- Terraform'un backendleri ile ilgili sınırlamalar
- State dosyalarını izole etme
terraform_remote_stateveri kaynağı
1. Terraform State Nedir?
Terraform'u her çalıştırdığınızda, hangi altyapıyı oluşturduğuyla ilgili bilgileri bir Terraform state dosyasına kaydeder. Varsayılan olarak, Terraform'u /kerteriz/blog klasöründe çalıştırdığınızda, Terraform /kerteriz/blog/terraform.tfstate dosyasını oluşturur. Bu dosya, konfigürasyon dosyalarınızdaki Terraform kaynaklarından (resource) bu kaynakların gerçek dünyadaki temsiline bir eşleme kaydeden özel bir JSON formatı içerir. Örneğin, Terraform yapılandırmanızın aşağıdakileri içerdiğini varsayalım:
resource "aws_instance" "example" {
ami = "ami-0fb653ca2d3203ac1"
instance_type = "t2.micro"
}terraform apply komutu çalıştırdıktan sonra, terraform.tfstate dosyasının içeriğinin küçük bir parçasını burada bulabilirsiniz (okunabilirlik için kısaltılmıştır):
{
"version": 4,
"terraform_version": "1.1.4",
"serial": 1,
"lineage": "86545604-7463-4aa5-e9e8-a2a221de98d2",
"outputs": {},
"resources": [
{
"mode": "managed",
"type": "aws_instance",
"name": "example",
"provider": "provider[\"registry.terraform.io/hashicorp/aws\"]",
"instances": [
{
"schema_version": 1,
"attributes": {
"ami": "ami-0fb653ca2d3203ac1",
"availability_zone": "us-east-2b",
"id": "i-0bc4bbe5b84387543",
"instance_state": "running",
"instance_type": "t2.micro",
"(...)": "(truncated)"
}
}
]
}
]
}Bu JSON biçimini kullanan Terraform, aws_instance türü ve example adı olan bir kaynağın, AWS hesabınızdaki i-0bc4bbe5b84387543 kimliğine sahip bir EC2 Instance'a karşılık geldiğini bilir. Terraform'u her çalıştırdığınızda, AWS'den bu EC2 Instance'ın en son durumunu alabilir ve hangi değişikliklerin uygulanması gerektiğini belirlemek için bunu Terraform yapılandırmalarınızda bulunanlarla karşılaştırabilir. Başka bir deyişle, plan komutunun çıktısı, state dosyasındaki kimlikler aracılığıyla keşfedildiği gibi, bilgisayarınızdaki kod ile gerçek dünyada konuşlandırılmış altyapı arasındaki farktır.
terraform import veya terraform state komutlarını kullanın. (Bu komutları ilerleyen yazılarda göreceğiz)Terraform'u kişisel bir proje için kullanıyorsanız, state'i bilgisayarınızda yerel olarak bulunan tek bir terraform.tfstate dosyasında saklamak gayet iyi sonuç verir. Ancak Terraform'u gerçek bir ürün üzerinde bir ekip olarak kullanmak istiyorsanız, birkaç sorunla karşılaşırsınız:
- State dosyaları için paylaşımlı depolama:
Altyapınızı güncellemek üzere Terraform'u kullanabilmek için ekip üyelerinizin her birinin aynı Terraform state dosyalarına erişmesi gerekir. Bu durum, bu dosyaları paylaşılan bir konumda saklamanız gerektiği anlamına gelir.
- Durum dosyalarını üzeinde locking:
Veriler paylaşılır paylaşılmaz yeni bir sorunla karşılaşırsınız: locking. Locking olmadan, iki ekip üyesi aynı anda Terraform çalıştırıyorsa, birden fazla Terraform işlemi state dosyalarında eşzamanlı güncellemeler yaparak çakışmalara, veri kaybına ve state dosyası bozulmasına neden olduğundan race condition ile karşılaşabilirsiniz.
- State dosyalarını izole etme:
Altyapınızda değişiklik yaparken farklı ortamları izole etmek en iyi uygulamadır. Örneğin, bir test veya development ortamında bir değişiklik yaparken, üretimi yanlışlıkla kesintiye uğratmanın hiçbir yolu olmadığından emin olmak istersiniz. Ancak tüm altyapınız aynı Terraform durum dosyasında tanımlanmışsa, değişikliklerinizi nasıl izole edebilirsiniz?
Aşağıdaki bölümlerde, bu sorunların her birine değineceğim ve size bunları nasıl çözeceğinizi göstereceğim.
2. State Dosyaları için Paylaşılan Depolama Alanı
Birden çok ekip üyesinin ortak bir dosya kümesine erişmesine izin vermenin en yaygın tekniği, onları sürüm denetimine (örneğin Git) yerleştirmektir. Terraform kodunuzu sürüm kontrolünde kesinlikle saklamanız gerekse de, Terraform durumunu sürüm kontrolünde depolamak aşağıdaki nedenlerden dolayı kötü bir fikirdir:
- Manuel hata:
Terraform'u çalıştırmadan önce sürüm kontrolünden en son değişiklikleri indirmeyi veya Terraform'u çalıştırdıktan sonra en son değişikliklerinizi sürüm kontrolüne göndermeyi unutmak çok kolaydır. Ekibinizden birinin Terraform'u güncel olmayan durum dosyalarıyla çalıştırması ve bunun sonucunda yanlışlıkla geri alması veya önceki dağıtımları çoğaltması an meselesidir.
- Locking:
Çoğu sürüm kontrol sistemi, iki ekip üyesinin aynı anda aynı durum dosyasında terraform uygulamasını çalıştırmasını engelleyecek herhangi bir locking mekanizması sağlamaz.
- Hassas veriler (secrets):
Terraform state dosyalarındaki tüm veriler düz metin olarak saklanır. Bu bir sorundur çünkü belirli Terraform kaynaklarının hassas verileri depolaması gerekir. Örneğin, bir veritabanı oluşturmak için aws_db_instance kaynağını kullanırsanız, Terraform veritabanı için kullanıcı adını ve parolayı düz metin olarak bir durum dosyasında saklar. Hassas verileri düz metin olarak herhangi bir yerde saklamak, sürüm kontrolü de dahil olmak üzere kötü bir fikirdir. Mayıs 2019 itibariyle, bu Terraform topluluğunda açık bir issue'dur, ancak birazdan tartışacağım gibi bazı makul geçici çözümler vardır.
Sürüm kontrolünü kullanmak yerine, state dosyaları için paylaşılan depolamayı yönetmenin en iyi yolu, Terraform'un remote backend'ler için yerleşik desteğini kullanmaktır. Bir Terraform backend, Terraform'un state'i nasıl yüklediğini ve depoladığını belirler. Tüm bu süre boyunca kullandığınız varsayılan backend, state dosyasını yerel diskinizde depolayan yerel backenddir. Remote backend, state dosyasını uzak, paylaşılan bir depoda saklamanıza olanak tanır. Amazon S3 dahil olmak üzere bir dizi remote backend desteklenmektedir; Azure Storage, Google Cloud Storage ve HashiCorp'un Terraform Cloud ve Terraform Enterprise diğer seçeneklerdendir.
Remote backendler, az önce listelenen üç sorunu çözer:
- Manuel hata:
Bir remote backendi yapılandırdıktan sonra, Terraform, plan veya apply komutlarını her çalıştırdığınızda state dosyasını o remote backendden otomatik olarak yükler ve her apply komutundan sonra state dosyasını otomatik olarak o remote backendde depolar, böylece manuel hata olasılığı yoktur.
- Locking:
Remote backendlerin çoğu yerel olarak lockingi destekler. Terraform apply komutunu çalıştırmak için Terraform otomatik olarak bir lock alır. Eğer başka biri zaten çalışıyorsa, state dosyasında lock olduğundan beklemeniz gerekir. Terraform'a bir kilidin açılması için TIME kadar beklemesi talimatını vermek için -lock-timeout= parametresiyle apply komutunu çalıştırabilirsiniz (örneğin, `-lock-timeout=10m` 10 dakika bekler).
- Hassas veriler (secrets):
Remote backendlerin çoğu, aktarım sırasında şifrelemeyi ve state dosyasının şifreli bir alanda durmasını destekler. Ayrıca, bu remote backendler genellikle erişim izinlerini yapılandırmanın yollarını sunar (örneğin, bir Amazon S3 paketiyle IAM ilkelerini kullanma), böylece state dosyalarınıza kimlerin erişimi olduğunu ve içerebilecekleri hassas verileri kontrol edebilirsiniz. Terraform'un state dosyasındaki hassas verileri yerel olarak şifrelemeyi desteklemesi daha iyi olurdu, ancak bu remote backendler, en azından state dosyasının düz metin olarak herhangi bir yerde diskte saklanmadığı göz önüne alındığında, güvenlik endişelerinin çoğunu azaltır.
AWS ile Terraform kullanıyorsanız, Amazon'un yönetilen dosya deposu olan Amazon S3 (Basit Depolama Hizmeti), aşağıdaki nedenlerle genellikle remote backend olarak en iyi seçeneğinizdir:
- Bu yönetilen bir hizmettir, dolayısıyla onu kullanmak için fazladan altyapıyı dağıtmanıza ve yönetmenize gerek yoktur.
- %99,99 dayanıklılık ve %99,99 kullanılabilirlik için tasarlanmıştır, bu da veri kaybı veya kesintileri konusunda çok fazla endişelenmenize gerek olmadığı anlamına gelir.
- State dosyalarında hassas verilerin depolanmasıyla ilgili endişeleri azaltan şifrelemeyi destekler. Ekibinizde bu S3 bucket'a erişimi olan herkes, state dosyalarını şifrelenmemiş bir biçimde görebilecek ancak en azından veriler hareketsizken (Amazon S3, AES-256 ile sunucu tarafı şifrelemeyi destekler) ve aktarım sırasında (Terraform, Amazon S3 ile konuşurken TLS kullanır) şifrelenecek.
- DynamoDB aracılığıyla lockingi destekler. (Daha sonra göreceğiz.)
- Sürüm oluşturmayı destekler, böylece state dosyanızın her revizyonu saklanır ve bir şeyler ters giderse eski bir sürüme geri dönebilirsiniz.
- Ucuzdur, çoğu Terraform kullanımı ücretsiz katmana kolayca sığar.
Terraform ile AWS S3 Bucket üzerinde depolayarak manuel hatalar, locking ve hassas veriler konusunda endişelerinizi ortadan kaldırabilirsiniz. Üstelik Free Tier ile ücretsiz bir şekilde state dosyalarınızı ekip kullanımında hataya ve endişeye yer bırakmadan kullanabilirsiniz.
Amazon S3 ile remote state depolamayı etkinleştirmek için ilk adım bir S3 bucket oluşturmaktır. Terraform ile AWS S3 Bucket oluşturma işlemi için bir önceki yazımıza aşağıdaki bağlantı üzerinden erişebilirsiniz.
 Ismet BALAT
Ismet BALAT
Artık bir S3 bucketa sahipseniz bu bucket'ın adını not alın ve buradan ilerlemeye devam edin.
Şimdi, locking için kullanmak üzere bir DynamoDB tablosu oluşturmanız gerekir. DynamoDB, Amazon'un dağıtık key/value deposudur. Dağıtık bir locking sistemi son derece tutarlı okuma ve yazma işlemlerini destekler. Ayrıca, tamamen yönetilebilirdir.
DynamoDB'yi Terraform ile locking için kullanmak için, LockID adlı bir primary keye sahip bir DynamoDB tablosu oluşturmanız gerekir. aws_dynamodb_table kaynağını kullanarak böyle bir tablo oluşturabilirsiniz:
resource "aws_dynamodb_table" "terraform_locks" {
name = "terraform-kerteriz-blog-state-s3-bucket-locks"
billing_mode = "PAY_PER_REQUEST"
hash_key = "LockID"
attribute {
name = "LockID"
type = "S"
}
}DynamoDB'yi Terraform ile yönetebilmek için terraform kullanıcınıza IAM üzerinden "AmazonDynamoDBFullAccess" yetkisi verdiğinizden emin olunuz. Aksi halde yetki hatası alırsınız.
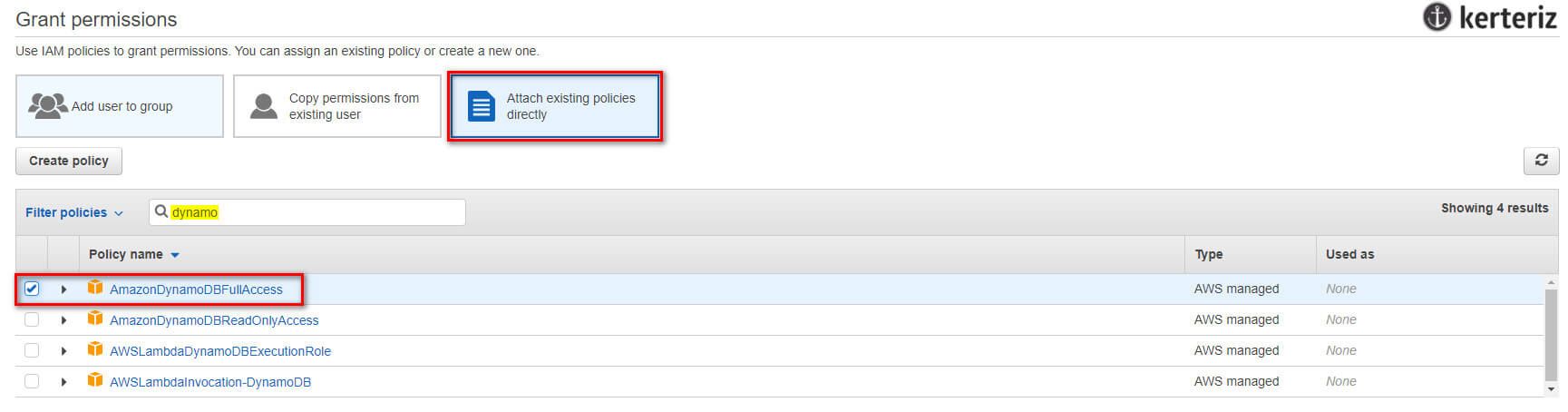
Şimdi sağlayıcı kodunu indirmek için terraform init'i çalıştırın ve ardından deploy etmek için terraform apply'ı çalıştırın. Her şey deploy edildikten sonra daha önce oluşturmuş olduğunuz S3 bucket'a ek olarak bir de DynamoDB tablonuz olacak.
Her ne kadar S3 bucket ve bir DynamoDB tablosuna sahip olsakta Terraform state'i yerel olarak saklanmaya devam edecek. Terraform'u state'i S3 bucketınızda saklayacak şekilde yapılandırmak için (şifreleme ve locking ile birlikte), Terraform kodunuza bir remote backend eklemeniz gerekir. Bu, Terraform'un kendisi için yapılandırmadır, bu nedenle bir terraform bloğu içinde bulunur ve aşağıdaki sözdizimine sahiptir:
terraform {
backend "<BACKEND_NAME>" {
[CONFIG...]
}
}Burada BACKEND_NAME, kullanmak istediğiniz backend adıdır (örneğin, "s3") ve CONFIG, o backende özel bir veya daha fazla bağımsız değişkenden oluşur (örneğin, kullanılacak S3 bucket adı). Bir S3 bucket için backend yapılandırması şöyle görünür:
terraform {
backend "s3" {
# Kendi bucket adınızla değiştirin!
bucket = "terraform-kerteriz-blog-state-s3-bucket"
key = "global/s3/terraform.tfstate"
region = "us-east-2"
# Kendi DynamoDB tablo adınızla değiştirin!
dynamodb_table = "terraform-kerteriz-blog-state-s3-bucket-locks"
encrypt = true
}
}Bu ayarları tek tek inceleyelim:
bucket: Kullanılacak S3 bucket adı. Bunu kendi oluşturduğunuz S3 bucketın adıyla değiştirdiğinizden emin olun.key: Terraform state dosyasının yazılması gereken S3 bucket içindeki dosya yolu. Biraz sonra, önceki örnek kodun bunu nedenglobal/s3/terraform.tfstateolarak ayarladığını göreceksiniz.region: S3 bucketın yaşadığı AWS bölgesi. Bunu kendi oluşturduğunuz S3 bucketın bölgesiyle değiştirdiğinizden emin olun.dynamodb_table: Kilitleme için kullanılacak DynamoDB tablosu. Bunu kendi oluşturduğunuz DynamoDB tablosunun adıyla değiştirdiğinizden emin olun.encrypt: Bunutrueolarak ayarlamak, S3'te saklandığında Terraform state'inizin diskte şifrelenmesini sağlar. S3 bucketın kendisinde varsayılan şifrelemeyi zaten etkinleştirdik, bu nedenle bu, verilerin her zaman şifrelenmesini sağlamak için ikinci bir katman olarak buradadır.
Terraform'a state dosyanızı bu S3 bucketta saklaması talimatını vermek için terraform init komutunu tekrar kullanacaksınız. Bu komut yalnızca sağlayıcı kodunu indirmekle kalmaz, aynı zamanda Terraform backendi de yapılandırabilir (daha sonra başka bir kullanımını göreceksiniz). Ayrıca, init komutu idempotenttir, bu nedenle onu birden çok kez çalıştırmak güvenlidir:
$ terraform init
Initializing the backend...
Acquiring state lock. This may take a few moments...
Do you want to copy existing state to the new backend?
Pre-existing state was found while migrating the previous "local" backend
to the newly configured "s3" backend. No existing state was found in the
newly configured "s3" backend. Do you want to copy this state to the new
"s3" backend? Enter "yes" to copy and "no" to start with an empty state.
Enter a value:Terraform, yerel olarak zaten bir state dosyanız olduğunu otomatik olarak algılar ve sizden onu yeni S3 backende kopyalamanızı ister. yes yazarsanız, aşağıdakileri görmelisiniz:
Successfully configured the backend "s3"! Terraform will automatically
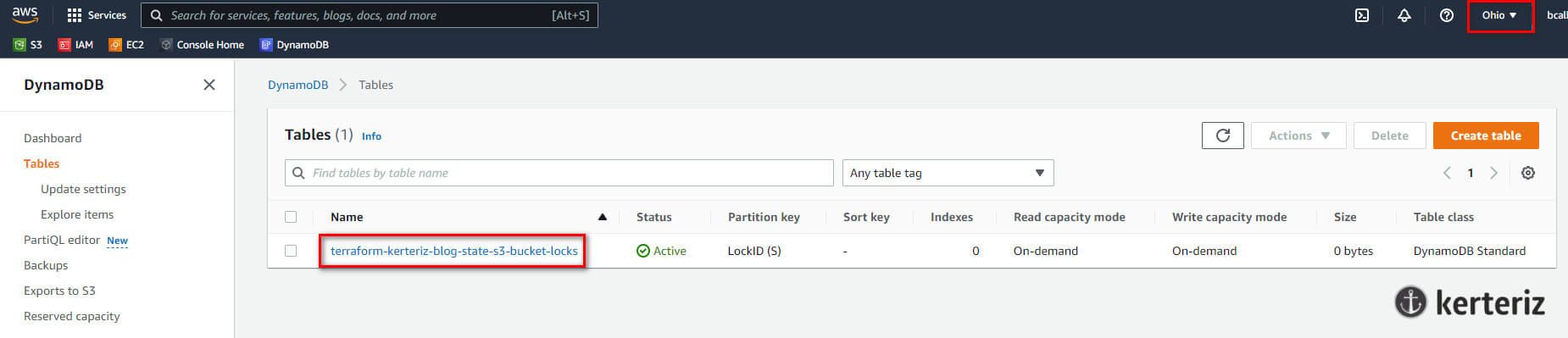
use this backend unless the backend configuration changes.Bu komutu çalıştırdıktan sonra Terraform state dosyanız S3 bucketta saklanacaktır. Bunu, tarayıcınızdaki S3 Yönetim Konsolu'na giderek ve bucketınıza tıklayarak kontrol edebilirsiniz.
Bu backend etkinleştirildiğinde, Terraform bir komutu çalıştırmadan önce bu S3 buckettan en son state'i otomatik olarak çeker ve bir komutu çalıştırdıktan sonra en son state'i otomatik olarak S3 bucket'a gönderir. Bunu çalışırken görmek için aşağıdaki çıktı değişkenlerini ekleyin:
output "s3_bucket_arn" {
value = aws_s3_bucket.terraform_state.arn
description = "The ARN of the S3 bucket"
}
output "dynamodb_table_name" {
value = aws_dynamodb_table.terraform_locks.name
description = "The name of the DynamoDB table"
}Bu değişkenler, S3 bucket'ınızın Amazon Resource Name (ARN) ve DynamoDB tablonuzun adını yazdırır. Görmek için terraform apply komutunu çalıştırın:
$ terraform apply
(...)
Acquiring state lock. This may take a few moments...
aws_dynamodb_table.terraform_locks: Refreshing state...
aws_s3_bucket.terraform_state: Refreshing state...
Apply complete! Resources: 0 added, 0 changed, 0 destroyed.
Releasing state lock. This may take a few moments...
Outputs:
dynamodb_table_name = "terraform-kerteriz-blog-state-s3-bucket-locks"
s3_bucket_arn = "arn:aws:s3:::terraform-kerteriz-blog-state-s3-bucket"Terraform'un apply komutundan önce nasıl bir lock aldığını ve ardından locku nasıl serbest bıraktığını not edin!
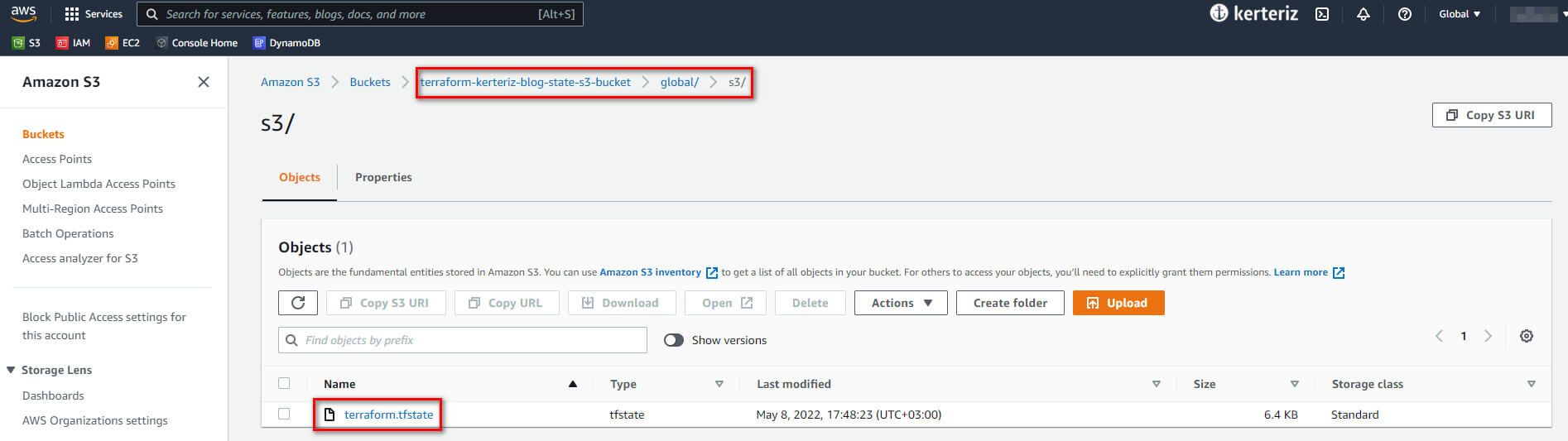
Şimdi tekrar S3 konsoluna gidin, sayfayı yenileyin ve "Show versions" isimli switchi aktif edin. Şekil 4'te gösterildiği gibi, S3 bucket'ınızda terraform.tfstate dosyanızın birkaç sürümünü görmelisiniz.
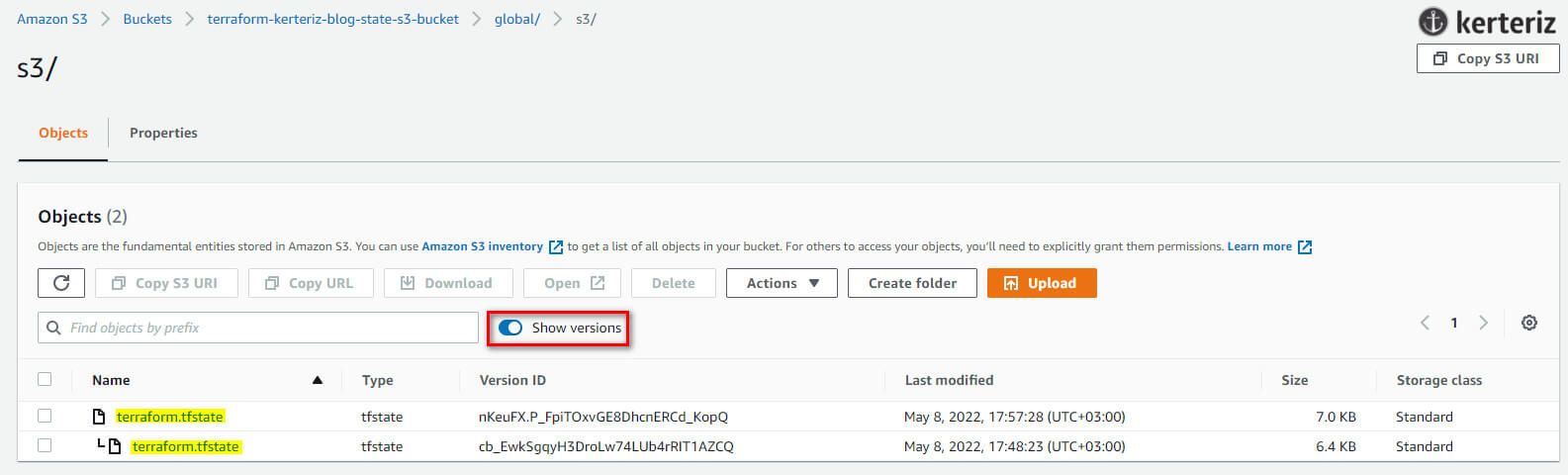
Bu, Terraform'un state verilerini S3'e ve S3'ten otomatik olarak gönderip çektiği ve S3'ün state dosyasının her revizyonunu sakladığı anlamına gelir. Eğer bir şeyler ters giderse hata ayıklamak ve eski sürümlere geri dönmek için yararlı olabilir.
3. Terraform'un Backendleri İle İlgili Sınırlamalar
Remote bir backend ve locking ile işbirliği artık hallettiğimiz basit bir problem oldu. Ancak geriye kalan bir sorun daha var: İzolasyon. Terraform'u ilk kullanmaya başladığınızda, tüm altyapınızı tek bir Terraform dosyasında veya Terraform dosya kümesi olarak tek bir klasörde tanımlamak isteyebilirsiniz. Bu yaklaşımla ilgili sorun, tüm Terraform state'inizin artık tek bir dosyada saklanması ve herhangi bir yerdeki bir hatanın her şeyi bozabilmesidir.
Örneğin, uygulamanızın yeni bir sürümünü test ortamına dağıtmaya çalışırken production ortamındaki uygulamayı bozabilirsiniz. Veya daha da kötüsü, locking kullanmadığınız için veya nadir bir Terraform hatası nedeniyle state dosyanızın tamamını bozabilirsiniz ve tüm ortamlardaki altyapınızlarınız bozuk hale gelir.
Ayrı ortamlara sahip olmanın tüm amacı, birbirlerinden izole olmalarıdır, bu nedenle tüm ortamları tek bir Terraform yapılandırması kümesinden yönetiyorsanız, bu yalıtımı kırıyorsunuz demektir. Bir geminin, geminin bir kısmındaki bir sızıntının diğerlerini hemen su basmasını önlemek için bariyer görevi gören perdeleri olduğu gibi, Şekil 5'te gösterildiği gibi Terraform tasarımınızda yerleşik "bölme duvarları" olmalıdır.
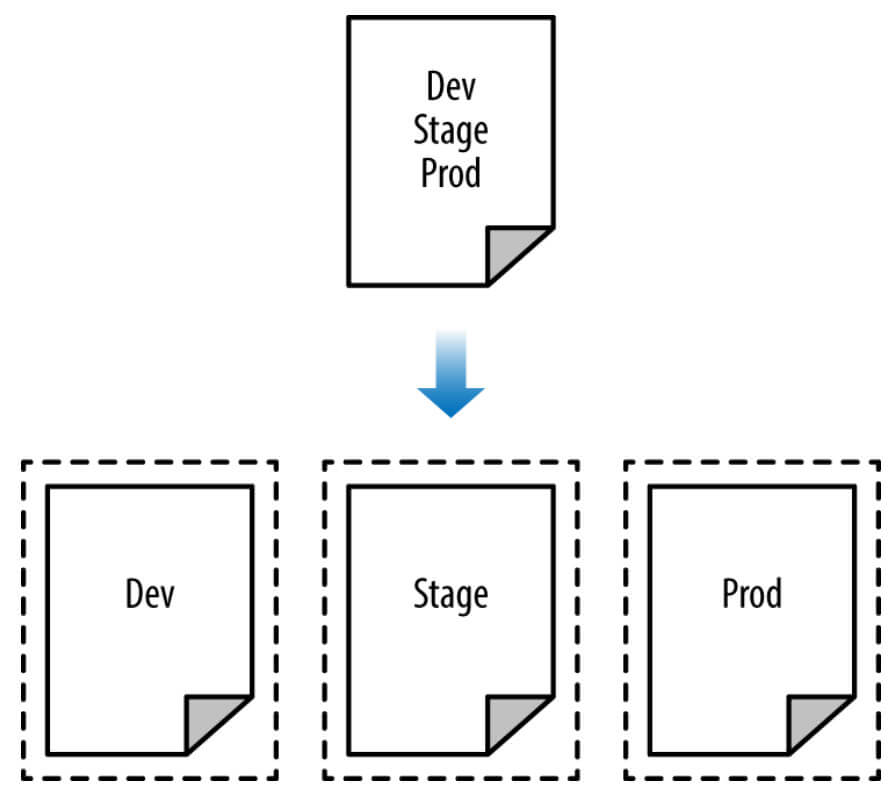
Şekil 5'te gösterildiği gibi, tüm ortamlarınızı tek bir Terraform konfigürasyonu setinde (üstte) tanımlamak yerine, her bir ortamı ayrı bir konfigürasyon setinde (altta) tanımlamak istiyorsunuz, böylece bir ortamdaki bir problem tamamen izole edilmiş olur. State dosyalarını izole etmenin iki yolu vardır:
- Workspaceler aracılığıyla izolasyon: Aynı konfigürasyon üzerinde hızlı, izole testler için kullanışlıdır.
- Dosya düzeni aracılığıyla izolasyon: Ortamlar arasında güçlü bir ayrım yapmanız gereken production kullanım durumları için kullanışlıdır.
Sonraki iki bölümde bunların her birine dalalım.
3.1. Workspaceler Aracılığıyla İzolasyon
Terraform workspace, Terraform state'inizi birden çok, ayrı, adlandırılmış çalışma alanında saklamanıza olanak tanır. Terraform, "default" olarak adlandırılan tek bir workspace ile başlar ve hiçbir zaman açıkça bir çalışma alanı belirtmezseniz, default workspace tüm zaman boyunca kullanacağınız workspace olur. Yeni bir workspace oluşturmak veya workspaceler arasında geçiş yapmak için terraform workspace komutunu kullanırsınız. Hadi tek bir EC2 Instance deploy eden Terraform kodunda workspaceleri deneyelim. Bu örnekleri yeni bir klasörde yeni bir main.tf oluşturarak deneyebilirsiniz:
resource "aws_instance" "example" {
ami = "ami-0fb653ca2d3203ac1"
instance_type = "t2.micro"
}Bölümün başlarında oluşturduğunuz S3 bucket ve DynamoDB tablosunu kullanarak, ancak key değerini workspaces-example/terraform.tfstate olarak ayarlayarak bu Instance için bir endpoint yapılandıralım:
terraform {
backend "s3" {
# Kendi bucket adınızla değiştirin!
bucket = "terraform-kerteriz-blog-state-s3-bucket"
key = "workspaces-example/terraform.tfstate"
region = "us-east-2"
# Kendi DynamoDB tablo adınızla değiştirin!
dynamodb_table = "terraform-kerteriz-blog-state-s3-bucket-locks"
encrypt = true
}
}Bu kodu deploy etmek için terraform init ve terraform apply komutunu çalıştırın:
$ terraform init
Initializing the backend...
Successfully configured the backend "s3"! Terraform will automatically
use this backend unless the backend configuration changes.
Initializing provider plugins...
(...)
Terraform has been successfully initialized!
$ terraform apply
(...)
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.Bu deployun state'i, default workspace'de depolanır. Şu anda hangi çalışma alanında olduğunuzu belirleyecek olan terraform workspace show komutunu çalıştırarak bunu görebilirsiniz:
$ terraform workspace show
defaultDefault workspace, state'i tam olarak key yapılandırması aracılığıyla belirttiğiniz konumda saklar. Şekil 6'da gösterildiği gibi, S3 bucket'ınıza bakarsanız, workspaces-example klasöründe bir terraform.tfstate dosyası bulacaksınız.
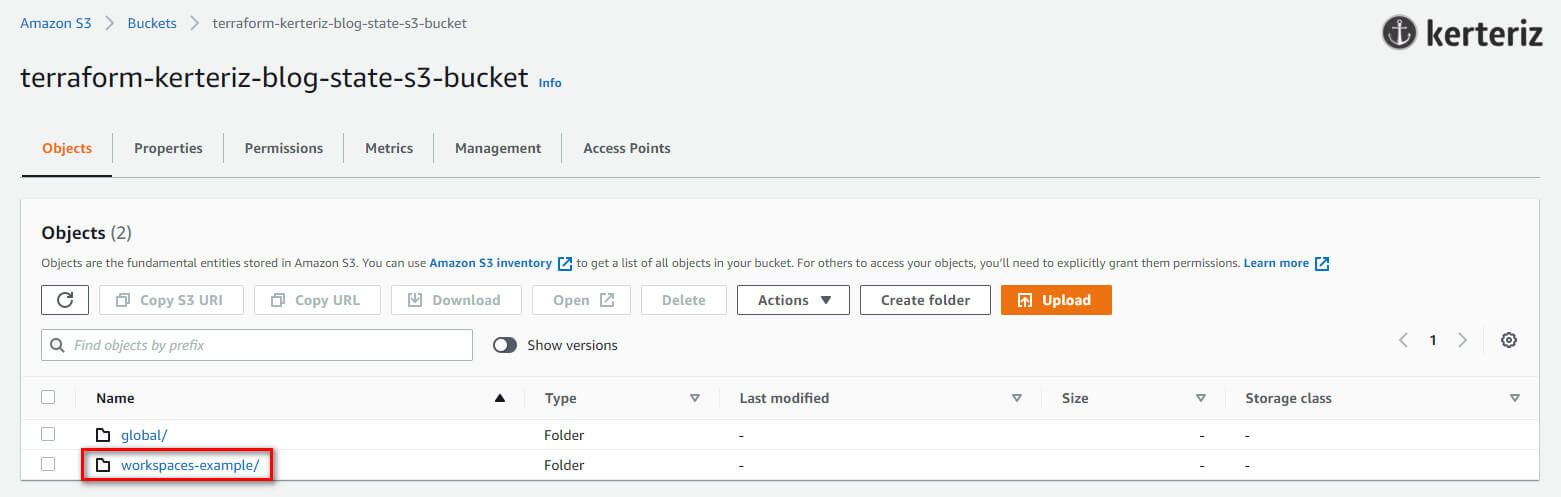
terraform workspace new komutunu kullanarak “example1” adında yeni bir workspace oluşturalım:
$ terraform workspace new example1
Created and switched to workspace "example1"!
You're now on a new, empty workspace. Workspaces isolate their state,
so if you run "terraform plan" Terraform will not see any existing state
for this configuration.Şimdi, terraform plan komutunu çalıştırmayı denerseniz ne olduğuna dikkat edin:
$ terraform plan
Terraform will perform the following actions:
# aws_instance.example will be created
+ resource "aws_instance" "example" {
+ ami = "ami-0fb653ca2d3203ac1"
+ instance_type = "t2.micro"
(...)
}
Plan: 1 to add, 0 to change, 0 to destroy.Terraform, sıfırdan tamamen yeni bir EC2 Instance oluşturmak istiyor! Bunun nedeni, her workspace içindeki state dosyalarının birbirinden yalıtılmış olmasıdır. Şu anda example1 workspace içinde olduğunuz için, Terraform default workspace içindeki state dosyasını kullanmıyor ve bu nedenle zaten mevcut olan EC2 Instance'ı görmüyor.
Bu ikinci EC2 Instance'ı yeni workspace içinde deploy etmek için terraform apply komutunu çalıştırmayı deneyin:
$ terraform apply
(...)
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.Alıştırmayı bir kez daha tekrarlayın ve “example2” adında başka bir workspace oluşturun:
$ terraform workspace new example2
Created and switched to workspace "example2"!
You're now on a new, empty workspace. Workspaces isolate their state,
so if you run "terraform plan" Terraform will not see any existing state
for this configuration.Üçüncü bir EC2 Instance deploy etmek için terraform apply komutunu yeniden çalıştırın:
$ terraform apply
(...)
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.Artık terraform workspace list komutunu kullanarak görebileceğiniz gibi üç çalışma alanınız var:
$ terraform workspace list
default
example1
* example2Ve terraform workspace select komutunu kullanarak istediğiniz zaman bunlar arasında geçiş yapabilirsiniz:
$ terraform workspace select example1
Switched to workspace "example1".Bunun nasıl çalıştığını anlamak için S3 bucket'ınıza tekrar bir göz atın; şimdi Şekil 7'de gösterildiği gibi env: adlı yeni bir klasör görmelisiniz. Bu klasörü ziyaret ettiğinizde ise herbir workspace'e ait klasör ve state dosyalarının aynı dizin hiyerarşisi içinde olduğunu göreceksiniz.
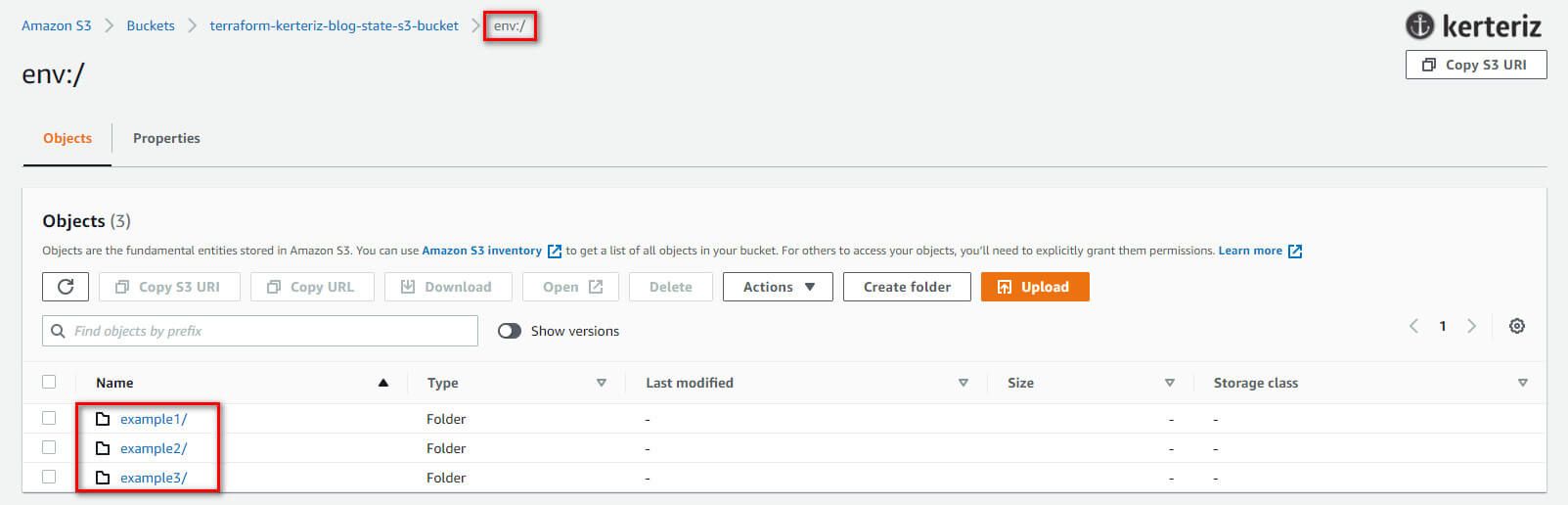
Bu çalışma alanlarının her birinin içinde Terraform, backend yapılandırmanızda belirttiğiniz key'i kullanır, bu nedenle bir example1/workspaces-example/terraform.tfstate,bir example2/workspaces-example/terraform.tfstate ve bir example3/workspaces-example/terraform.tfstate dosyası bulmalısınız. Başka bir deyişle, farklı bir çalışma alanına geçmek, state dosyanızın depolandığı yolu değiştirmekle eşdeğerdir.
Bu, halihazırda deploy edilmiş bir Terraform modülünüz olduğunda ve onunla bazı deneyler yapmak istediğinizde (örneğin, kodu yeniden düzenlemek gibi), ancak deneylerinizin halihazırda deploy edilmiş altyapının durumunu etkilemesini istemiyorsanız kullanışlıdır. Terraform workspaceler, terraform workspace new komutu çalıştırmanıza ve tamamen aynı altyapının yeni bir kopyasını dağıtmanıza, ancak state'i ayrı bir dosyada saklamanıza olanak tanır.
Aslında, terraform.workspace ifadesini kullanarak çalışma alanı adını okuyarak bu modülün içinde bulunduğunuz çalışma alanına göre nasıl davranacağını bile değiştirebilirsiniz. Örneğin, Instance türünü default çalışma alanında t2.medium ve diğer tüm çalışma alanlarında t2.micro olarak nasıl ayarlayacağınız aşağıda açıklanmıştır (ör. deneme yaparken paradan tasarruf etmek için):
resource "aws_instance" "example" {
ami = "ami-0fb653ca2d3203ac1"
instance_type = terraform.workspace == "default" ? "t2.medium" : "t2.micro"
}Önceki kod, terraform.workspace'in değerine bağlı olarak instance_type öğesini koşullu olarak t2.medium veya t2.micro olarak ayarlamak için üçlü sözdizimini kullanır.
Terraform workspaceler, kodunuzun farklı sürümleri arasında hızla geçiş yapmak ve destroy için harika bir yol olabilir, ancak birkaç dezavantajı vardır:
- Tüm çalışma alanlarınızın state dosyaları aynı backendde (ör. aynı S3 bucket) depolanır. Bu, tüm çalışma alanları için aynı kimlik doğrulama ve erişim kontrollerini kullandığınız anlamına gelir. Çalışma alanlarının ortamlarını yalıtmak için uygun olmayan bir mekanizma olmasının başlıca nedenlerinden biridir (örneğin, production ve test ortamları hesaplarını yalıtmak gerekebilir).
terraform wokspacekomutlarını çalıştırmadığınız sürece çalışma alanları kodda veya terminalde görünmez. Koda göz atarken, bir çalışma alanında dağıtılan bir modül, 10 çalışma alanında dağıtılan bir modülle tamamen aynı görünür. Bu, altyapınızın iyi bir resmine sahip olmadığınızdan bakımı daha da zorlaştırır.- Önceki iki öğeyi bir araya getirdiğimizde sonuç, çalışma alanlarının oldukça hataya açık olabilmesidir. Görünürlüğün olmaması, hangi çalışma alanında bulunduğunuzu unutmanızı ve yanlışlıkla yanlış çalışma alanında değişiklik yapmanızı kolaylaştırır (örneğin, terraform'u yanlışlıkla çalıştırmak, bir "test" çalışma alanından ziyade bir "production" çalışma alanında destroy komutu çalıştırabilir) ve kullanmanız gerektiği için tüm çalışma alanları için aynı kimlik doğrulama mekanizması, bu tür hatalara karşı koruma sağlayacak başka bir savunma katmanınız olmaz.
Bu dezavantajlardan dolayı, workspaceler bir ortamı diğerinden yalıtmak için uygun bir mekanizma değildir. Workspaceler yerine ortamlar arasında düzgün bir yalıtım elde etmek için büyük olasılıkla dosya düzenini (bir sonraki başlık) kullanmak isteyeceksiniz.
Devam etmeden önce, az önce dağıttığınız üç EC2 Instance'ı, üç çalışma alanının her birinde terraform workspace select ve terraform destroy komutunu çalıştırarak temizlediğinizden emin olun.
3.2. Dosya Düzeni Aracılığıyla İzolasyon
Ortamlar arasında tam izolasyon sağlamak için aşağıdakileri yapmanız gerekir:
- Her ortam için Terraform yapılandırma dosyalarını ayrı bir klasöre koyun. Örneğin, stage ortamının tüm konfigürasyonları
stageadlı bir klasörde olabilir ve production ortamının tüm konfigürasyonlarıprodadlı bir klasörde olabilir. - Farklı kimlik doğrulama mekanizmaları ve erişim kontrolleri kullanarak her ortam için farklı bir backend yapılandırın: ör. her ortam, backend olarak ayrı bir S3 bucketile ayrı bir AWS hesabında yaşayabilir.
Bu yaklaşımla, ayrı klasörlerin kullanılması, hangi ortamlara dağıttığınızı çok daha net hale getirir ve ayrı kimlik doğrulama mekanizmalarına sahip ayrı state dosyalarının kullanılması, bir ortamdaki bozulmanın diğerinde herhangi bir etki yaratma olasılığını önemli ölçüde azaltır.
Aslında, yalıtım kavramını ortamların ötesine ve bir bileşenin tipik olarak birlikte dağıttığınız tutarlı bir kaynak kümesi olduğu "component" düzeyine indirmek isteyebilirsiniz. Örneğin, altyapınız için temel ağ topolojisini (AWS dilinde, Sanal Özel Bulut (VPC) ve ilişkili tüm alt ağlar, yönlendirme kuralları, VPN'ler ve ağ ACL'leri) ayarladıktan sonra, muhtemelen bunu yalnızca bir kez değiştireceksiniz. Veya en fazla birkaç ayda bir. Öte yandan, bir web sunucusunun yeni bir sürümünü günde birden çok kez dağıtabilirsiniz. Hem VPC bileşeni hem de web sunucusu bileşeni için altyapıyı aynı Terraform konfigürasyonları setinde yönetiyorsanız, tüm ağ topolojinizi gereksiz yere günde birden çok kez bozulma riskine sokarsınız (örn. yanlış komut ile).
Bu nedenle, o ortamdaki her ortam (hazırlama, üretim vb.) ve her bileşen (VPC, hizmetler, veritabanları) için ayrı Terraform klasörleri (ve dolayısıyla ayrı durum dosyaları) kullanmanızı öneririm. Bunun pratikte nasıl göründüğünü görmek için, Terraform projeleri için önerilen dosya düzenini gözden geçirelim.
Şekil 8, tipik Terraform projem için dosya düzenini göstermektedir.
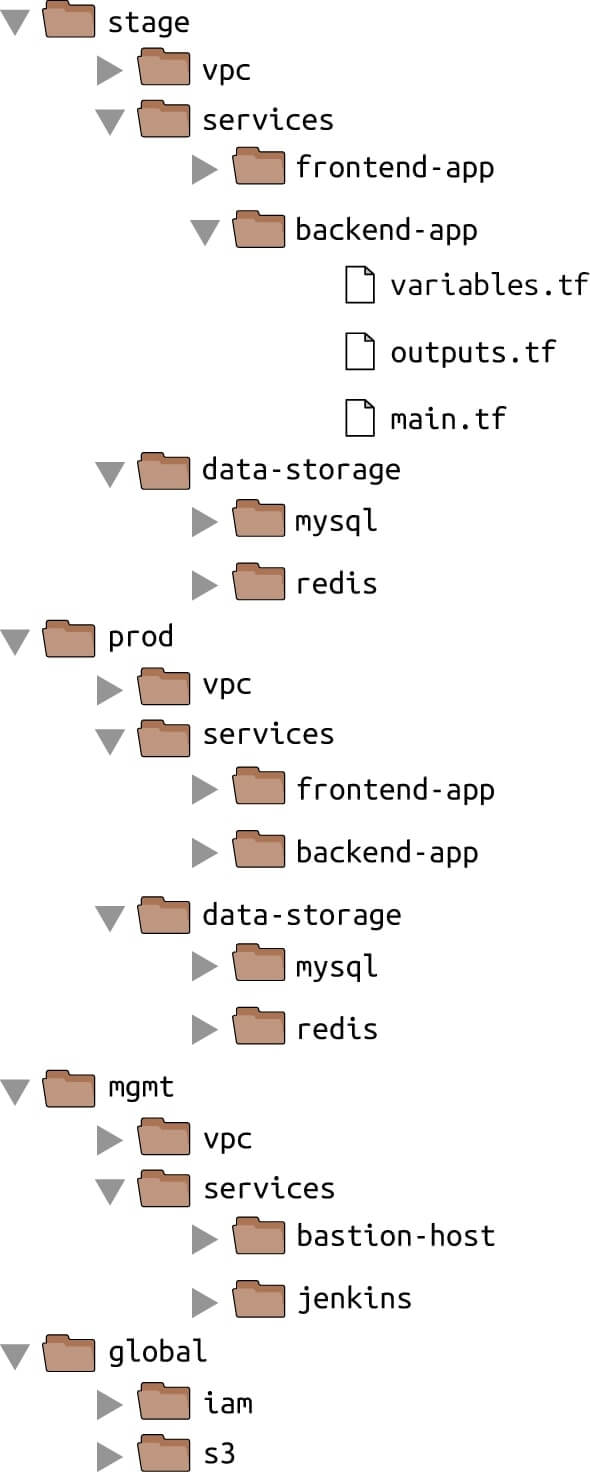
En üst düzeyde, her bir "ortam" için ayrı klasörler bulunur. Ortamlar her proje için farklılık gösterir, ancak tipik olanlar aşağıdaki gibidir:
stage:Production öncesi için bir ortam (ör. test)prod:Uygulamanızın kullanıcılara sunulduğu ortam (production)mgmt:DevOps araçları için bir ortam (ör. CI sunucusu)global:Tüm ortamlarda kullanılan kaynakları koyabileceğiniz bir yer (ör. S3, IAM)
Her ortamda, her bileşen için ayrı klasörler vardır. Bileşenler her proje için farklılık gösterir, ancak tipik olanlar şunlardır:
vpc:Bu ortam için ağ topolojisi.services:React frontend veya Java backend gibi bu ortamda çalıştırılacak uygulamalar veya mikro hizmetler. Her uygulama, onu diğer tüm uygulamalardan izole etmek için kendi klasöründe bile yaşayabilir.data-storage:MySQL veya Redis gibi bu ortamda çalışacak veri depoları içindir. Hatta her veri deposu, onu diğer tüm veri depolarından yalıtmak için kendi klasöründe bulunabilir.
Her bileşen içinde, aşağıdaki adlandırma kurallarına göre düzenlenen gerçek Terraform yapılandırma dosyaları vardır:
variables.tf:Girdi değişkenlerinin tutulduğu dosyaoutputs.tf:Çıktı değişkenlerinin tutulduğu dosyamain.tf:Kaynakların tutulduğu dosya
Terraform'u çalıştırdığınızda, yalnızca geçerli dizindeki .tf uzantılı dosyaları arar. Böylece dosyalarınızda istediğiniz isimleri özgürce kullanabilirsiniz. Bununla birlikte, Terraform dosya adlarını önemsemese de, muhtemelen takım arkadaşlarınız bunu önemser. Tutarlı, tahmin edilebilir bir adlandırma kuralı kullanmak, kodunuza göz atmayı kolaylaştırır: örneğin, bir değişkeni, çıktıyı veya kaynağı nerede bulacağınızı her zaman bilirsiniz.
Yukarıdaki kuralın, Terraform'un neredeyse tüm kullanımlarında olduğu gibi, izlemeniz gereken minimum kural olduğunu unutmayın. Girdi değişkenlerine, çıktı değişkenlerine ve kaynaklara çok hızlı bir şekilde atlayabilmek faydalıdır, ancak bu kuralın ötesine geçmek isteyebilirsiniz. Buradakiler sadece birkaç örnek:
dependencies.tf: Kodun hangi harici şeylere bağlı olduğunu görmeyi kolaylaştırmak için tüm veri kaynaklarınızı bu dosyaya koymak yaygındır.providers.tf:Sağlayıcı bloklarınızı bu dosyaya koymak isteyebilirsiniz, böylece bir bakışta kodun hangi sağlayıcılarla konuştuğunu ve hangi kimlik doğrulamasını sağlamanız gerektiğini görebilirsiniz.main-xxx.tf: Eğermain.tfdosyası çok sayıda kaynak içerdiği için gerçekten uzuyorsa, onu kaynakları mantıklı bir şekilde gruplayan daha küçük dosyalara bölebilirsiniz: örneğin,main-iam.tftüm IAM kaynaklarını içerebilir,main-s3.tf, tüm S3 kaynaklarını vb. içerebilir.Mainprefix kullanmak, tüm kaynaklar bir arada gruplandırılacağından, alfabetik olarak düzenlendiklerinde bir klasördeki dosyaların listesini taramayı kolaylaştırır. Ayrıca, kendinizi çok sayıda kaynağı yönetirken ve bunları birçok dosyaya bölmek için uğraşırken bulursanız, bu, kodunuzu daha küçük modüllere ayırmanız gerektiğinin bir işareti olabilir.
"Terraform İle AWS Kullanımı ve EC2 Web Server Deploy" başlıklı yazımızda yağtığımız web server örneğini tek bir main.tf dosyası yerine dosya düzeniyle yapsaydık dizin yapımız şu şekilde olurdu:
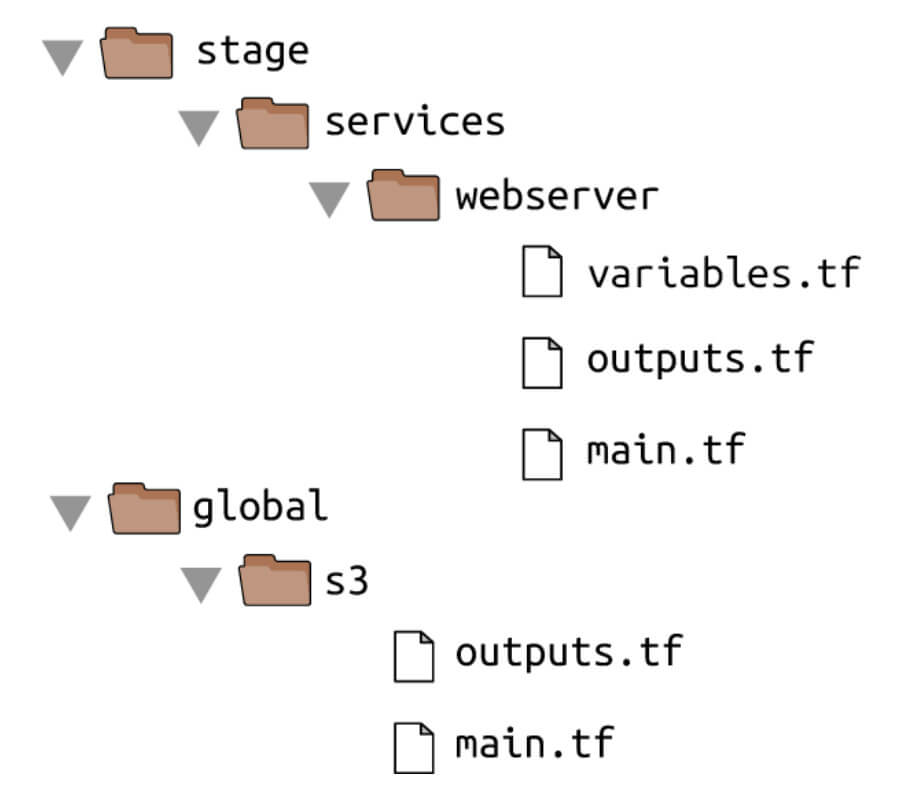
Bu bölümde oluşturduğunuz S3 bucket, global/s3 klasörüne taşınmalıdır. Çıktı değişkenlerini (s3_bucket_arn ve dynamodb_table_name) outputs.tf'ye taşıyın. Klasörü taşırken, dosyaları yeni konuma kopyalarken (gizli) .terraform klasörünü gözden kaçırmadığınızdan emin olun, böylece her şeyi yeniden başlatmanız gerekmez.
Yukarıdaki linkte yaptığımız web sunucusu örneği, stage/services/webserver dizinine taşınmalıdır (bunu o web sunucusunun "test" veya "stage" sürümü olarak düşünün). Yine, .terraform klasörünü kopyaladığınızdan, girdi değişkenlerini variables.tf'ye ve çıktı değişkenlerini de outputs.tf'ye taşıdığınızdan emin olun.
AWS S3'ü backend olarak kullanmak için web sunucusunu da güncellemelisiniz. Backend yapılandırmasını global/s3/main.tf adresinden aşağı yukarı aynen kopyalayıp yapıştırabilirsiniz, ancak key'i web sunucusu Terraform koduyla aynı klasör yoluna değiştirdiğinizden emin olun: stage/services/webserver/terraform.tfstat. Bu size sürüm kontrolünde Terraform kodunuzun düzeni ile S3'teki Terraform durum dosyalarınız arasında 1:1 eşleme sağlar. Bu nedenle ikisinin nasıl bağlandığı açıktır. s3 modülü zaten bu kuralı kullanarak key'iayarlar.
Bu dosya düzeninin bir takım avantajları vardır:
Temiz kod ve dosya düzeni: Koda göz atmak ve her bir ortamda tam olarak hangi bileşenlerin dağıtıldığını anlamak kolaydır.İzolasyon: Bu düzen, ortamlar arasında ve bir ortam içindeki bileşenler arasında iyi bir izolasyon sağlar ve bir şeyler ters giderse, hasarın tüm altyapınızın yalnızca küçük bir parçasında mümkün olduğunca sınırlandırılmasını sağlar.
Bazı yönlerden, bu avantajlar aynı zamanda dezavantajlardır:
Birden çok klasörle çalışma: Bileşenleri ayrı klasörlere bölmek, yanlışlıkla tüm altyapınızı tek komutta patlatmanızı engeller, ancak tüm altyapınızı tek komutta oluşturmanızı da engeller. Tek bir ortamın tüm bileşenleri tek bir Terraform konfigürasyonunda tanımlanmışsa, tek birterraform applyçağrısıyla tüm ortamı hazırlayabilirsiniz. Ancak tüm bileşenler ayrı klasörlerdeyse, her birinde ayrı ayrıterraform applyçalıştırmanız gerekir.
run-all komutunu kullanarak aynı anda birden çok klasörde komut çalıştırabilirsiniz.Kopyala / yapıştır: Bu bölümde açıklanan dosya düzeni çok fazla tekrar içeriyor. Örneğin, aynı frontend uygulaması ve backend uygulaması hem stage hem de prod klasörlerinde bulunuyor.
Kaynak bağımlılığı: Kodu birden çok klasöre bölmek, kaynak bağımlılıklarını kullanmayı zorlaştırır. Uygulama kodunuz, veritabanı koduyla aynı Terraform yapılandırma dosyalarında tanımlanmışsa, bu uygulama kodu, bir attribute referansı kullanarak veritabanının attributelerine doğrudan erişebilir (ör.,aws_db_instance.foo.addressaracılığıyla veritabanı adresine erişir). Ancak uygulama kodu ve veritabanı kodu, önerdiğim gibi farklı klasörlerde yaşıyorsa, artık bunu yapamazsınız.
terraform_remote_state veri kaynağını kullanmaktır.4. terraform_remote_state Data Source
Bir önceki "Terraform İle AWS Kullanımı ve Load Balancer Deploy" yazımızda, VPC'nizdeki subnetlerin bir listesini döndüren aws_subnets data source gibi AWS'den salt okunur bilgileri almak için veri kaynaklarını kullandınız. State ile çalışırken özellikle yararlı olan başka bir veri kaynağı daha vardır: terraform_remote_state. Bu data source, başka bir Terraform konfigürasyon seti tarafından depolanan Terraform state dosyasını tamamen salt okunur bir şekilde getirmek için kullanabilirsiniz.
Bir örnek üzerinden gidelim. Web sunucusu kümenizin bir MySQL veritabanı ile iletişim kurması gerektiğini hayal edin. Ölçeklenebilir, güvenli, dayanıklı ve yüksek oranda kullanılabilir bir veritabanı çalıştırmak çok iş yükü gerektirir. Yine, Şekil 10'da gösterildiği gibi, bu sefer Amazon'un Relational Database Service (RDS) ini kullanarak AWS'nin bunu sizin için halletmesine izin verebilirsiniz. RDS, MySQL, PostgreSQL, SQL Server ve Oracle dahil olmak üzere çeşitli veritabanlarını destekler.
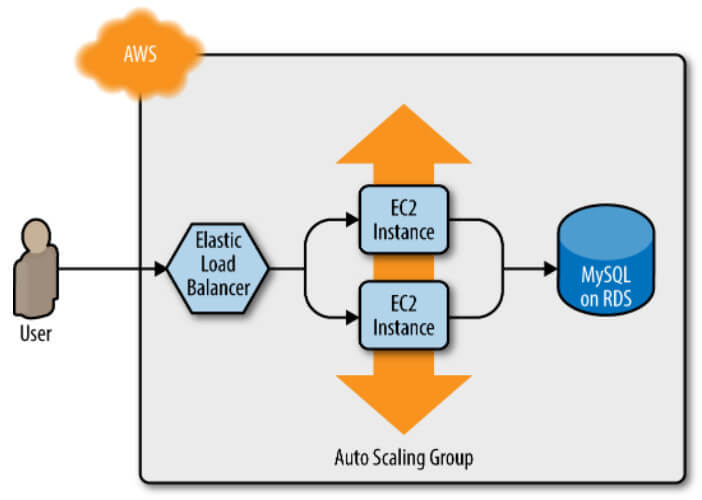
Web sunucusu kümesine güncellemeleri çok daha sık dağıtacağınız ve her seferinde yanlışlıkla veritabanını bozma riskini almak istemediğiniz için MySQL veritabanını web sunucusu kümesiyle aynı yapılandırma dosyaları kümesinde tanımlamak istemeyebilirsiniz. Bu nedenle ilk adımınız, stage/data-stores/mysql'de yeni bir klasör oluşturmak ve Şekil 11'de gösterildiği gibi bunun içinde temel Terraform dosyalarını (main.tf, variables.tf, outputs.tf) oluşturmak olmalıdır.

Stage/data-stores klasöründe veritabanı kodunu oluşturunArdından, stage/data-stores/mysql/main.tf'de veritabanı kaynaklarını oluşturalım:
provider "aws" {
region = "us-east-2"
}
resource "aws_db_instance" "example" {
identifier_prefix = "terraform-up-and-running"
engine = "mysql"
allocated_storage = 10
instance_class = "db.t2.micro"
skip_final_snapshot = true
db_name = "example_database"
# Kullanıcı adı ve şifreyi nasıl ayarlamalıyız?
username = "???"
password = "???"
}Dosyanın en üstünde tipik sağlayıcı bloğunu görürsünüz, ancak bunun hemen altında yeni bir kaynak bulunuyor: aws_db_instance. Bu kaynak, RDS'de aşağıdaki ayarlarla bir veritabanı oluşturur:
- Veritabanı motoru olarak MySQL.
- 10 GB depolama alanı.
- Bir sanal CPU'ya, 1 GB belleğe sahip olan ve AWS ücretsiz katmanının bir parçası olan bir
db.t2.microInstance. - Bu kod yalnızca öğrenme ve test etme amaçlı olduğundan final snapshot devre dışı bırakılır. Snapshot'ı devre dışı bırakmazsanız veya
final_snapshot_identifierparametresi aracılığıyla snapshot için bir ad sağlamazsanız, destroy başarısız olur.
aws_db_instance kaynağına iletmeniz gereken iki parametrenin kullanıcı adı ve parola olduğunu unutmayın. Bunlar hassas veri olduğundan, bunları doğrudan düz metin olarak kodunuza koymamalısınız!
İlerleyen yazılarda hassas verilerinizi nasıl ele alacağınıza dair daha detaylı incelemeler yapacağız fakat şimdilik "Terraform İle AWS Kullanımı ve EC2 Server Deploy" başlıklı yazımızın 3. başlığında anlattığımız gibi, Terraform ile hassas verilerinizi nasıl güvenli bir şekilde ele alınacağını görebilirsiniz.
Şimdilik, hassas verileri düz metin olarak saklamaktan kaçınan ve kullanımı kolay bir seçenek kullanalım: Veritabanı parolaları gibi hassas verileri Terraform dışında (örneğin, 1Password, LastPass veya macOS Keychain gibi bir parola yöneticisinde) depolarsınız ve bu hassas verileri ortam değişkenleri aracılığıyla Terraform'a iletirsiniz.
Bunu yapmak için, stage/data-stores/mysql/variables.tf dosyasında db_username ve db_password adlı değişkenleri oluşturun:
variable "db_username" {
description = "The username for the database"
type = string
sensitive = true
}
variable "db_password" {
description = "The password for the database"
type = string
sensitive = true
}İlk olarak, bu değişkenlerin hassas veri içerdiğini belirtmek için sensitive = true ile işaretlendiğini unutmayın. Bu, plan veya apply komutu çalıştırdığınızda Terraform'un değerleri kaydetmemesini sağlar. İkincisi, bu değişkenlerin bir varsayılanı olmadığını unutmayın. Bu kasıtlı yapılmıştır. Veritabanı kimlik bilgilerinizi veya hassas bilgileri düz metin olarak saklamamalısınız. Bunun yerine, bu değişkeni ortam değişkenlerini kullanarak ayarlayacaksınız.
Hatırlatma olarak, Terraform yapılandırmalarınızda tanımlanan xxx giriş değişkenlerinin her biri için, TF_VAR_xxx ortam değişkenini kullanarak Terraform'a bu değişkenin değerini sağlayabilirsiniz. db_username ve db_password giriş değişkenleri için, Linux/Unix/macOS sistemlerinde TF_VAR_db_username ve TF_VAR_db_password ortam değişkenlerini şu şekilde ayarlayabilirsiniz:
$ export TF_VAR_db_username="(YOUR_DB_USERNAME)"
$ export TF_VAR_db_password="(YOUR_DB_PASSWORD)"Windows sistemlerinde bunu şu şekilde yaparsınız:
$ set TF_VAR_db_username="(YOUR_DB_USERNAME)"
$ set TF_VAR_db_password="(YOUR_DB_PASSWORD)"aws_db_instance gibi bir Terraform kaynağına argüman olarak iletirseniz, bu hassas veri Terraform state dosyasında saklanacaktır!Veritabanı kimlik bilgilerini yapılandırdığınıza göre, sonraki adım, bu modülü, state'i daha önce path aşamasında /data-stores/mysql/terraform.tfstate'de oluşturduğunuz S3 klasöründe saklayacak şekilde yapılandırmaktır:
terraform {
backend "s3" {
# Kendi bucket adınızla değiştirmelisiniz!
bucket = "terraform-kerteriz-blog-state"
key = "stage/data-stores/mysql/terraform.tfstate"
region = "us-east-2"
# Kendi DynamoDB tablo adınızla değiştirmelisiniz!
dynamodb_table = "terraform-kerteriz-blog-locks"
encrypt = true
}
}Son olarak, veritabanının adresini ve bağlantı noktasını döndürmek için stage/data-stores/mysql/outputs.tf dosyasına iki çıktı değişkeni ekleyin:
output "address" {
value = aws_db_instance.example.address
description = "Connect to the database at this endpoint"
}
output "port" {
value = aws_db_instance.example.port
description = "The port the database is listening on"
}Veritabanını oluşturmak için terraform init ve terraform apply komutunu çalıştırın. Amazon RDS'nin küçük bir veritabanını bile sağlamanın yaklaşık 10 dakika sürebileceğini unutmayın, bu yüzden sabırlı olun. Uygulama tamamlandıktan sonra, terminaldeki çıktıları görmelisiniz:
$ terraform apply
(...)
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.
Outputs:
address = "tf-2016111123.cowu6mts6srx.us-east-2.rds.amazonaws.com"
port = 3306Bu çıktılar artık veritabanınız için S3 bucketınızda /data-stores/mysql/terraform.tfstate yolunda bulunan state dosyasında depolanır.
Web sunucusu cluster kodunuza geri dönerseniz, stage/services/webserver-cluster/main.tf'ye terraform_remote_state veri kaynağını ekleyerek web sunucusunun bu çıktıları veritabanının state dosyasından okumasını sağlayabilirsiniz:
data "terraform_remote_state" "db" {
backend = "s3"
config = {
bucket = "(YOUR_BUCKET_NAME)"
key = "stage/data-stores/mysql/terraform.tfstate"
region = "us-east-2"
}
}Bu terraform_remote_state veri kaynağı, web sunucusu küme kodunu, Şekil 12'de gösterildiği gibi, aynı S3 kovasından ve veritabanının state'ini sakladığı klasörden state dosyasını okumak için yapılandırır.
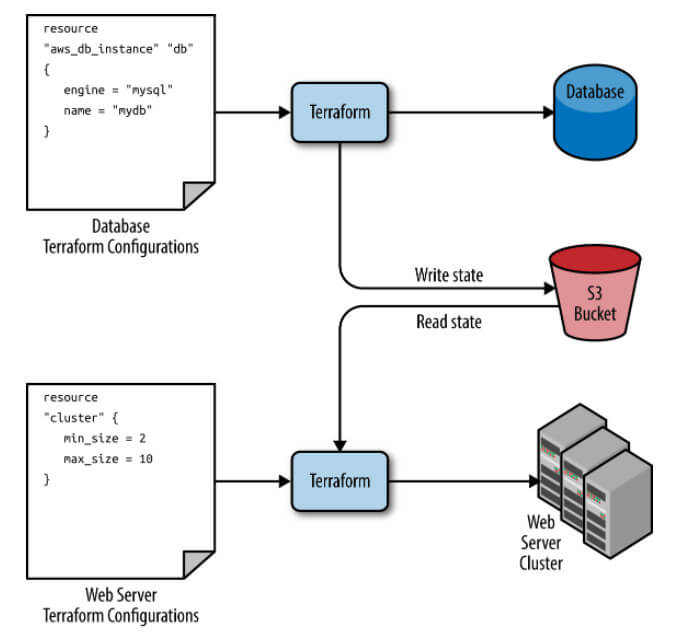
Tüm Terraform data source'ları gibi, terraform_remote_state tarafından döndürülen verilerin salt okunur olduğunu anlamak önemlidir. Web sunucusu kümenizde yaptığınız hiçbir Terraform kodu bu state'i değiştiremez, böylece veritabanının kendisinde herhangi bir soruna neden olma riski olmadan veritabanının state verilerini alabilirsiniz.
Veritabanının tüm çıktı değişkenleri state dosyasında saklanır ve bunları, formun attribute referansını kullanarak terraform_remote_state veri kaynağından okuyabilirsiniz:
data.terraform_remote_state.<NAME>.outputs.<ATTRIBUTE>
Örneğin, veritabanı adresini ve bağlantı noktasını terraform_remote_state data source içinden almak ve bu bilgileri HTTP yanıtına koymak için web sunucusu kümesi Instance'larının User Data kısmını nasıl güncelleyebileceğiniz aşağıda açıklanmıştır:
user_data = <<EOF
#!/bin/bash
echo "Hello, World" >> index.html
echo "${data.terraform_remote_state.db.outputs.address}" >> index.html
echo "${data.terraform_remote_state.db.outputs.port}" >> index.html
nohup busybox httpd -f -p ${var.server_port} &
EOFUser Data komut dosyası uzadıkça, onu satır içinde tanımlamak daha da karmaşık hale geliyor. Genel olarak, bir programlama dilini (Bash) diğerinin (Terraform) içine gömmek, her birinin bakımını daha zor hale getirir, bu yüzden Bash betiğini haricileştirmek için bir an burada duralım. Bunu yapmak için, templatefile metodunu kullanabilirsiniz.
Terraform, aşağıdaki sözdizimini kullanarak yürütebileceğiniz bir dizi yerleşik metod içerir:
function_name(...)Örneğin, format metodunu düşünün:
format(<FMT>, <ARGS>, ...)Bu metod, FMT string'indeki sprintf sözdizimine göre ARGS'deki bağımsız değişkenleri biçimlendirir. Yerleşik metodları denemenin harika bir yolu, Terraform sözdizimini deneyebileceğiniz etkileşimli bir konsol elde etmek için terraform console komutunu çalıştırmaktır. Böylece altyapınızın durumu ve sonuçları anında görürsünüz:
$ terraform console
> format("%.3f", 3.14159265359)
3.142Stringleri, sayıları, listeleri ve mapleri işlemek için kullanabileceğiniz bir dizi başka yerleşik metod vardır. Bunlardan biri de templatefile işlevidir:
templatefile(<PATH>, <VARS>)Bu metod, dosyayı PATH konumundan okur, onu bir şablon olarak işler ve sonucu bir string olarak döndürür. "Bunu bir şablon olarak işler" dediğimde, PATH'deki dosyanın Terraform'da (${...}) string enterpolasyon sözdizimini kullanabileceğini ve Terraform'un bu dosyanın içeriğini VARS değişkenlerini enterpolasyondaki yerlere doldurarak render edeceğini anlatmak istiyorum.
Bunu çalışırken görmek için, User Data komut dosyasının içeriğini aşağıdaki gibi stage/services/webserver-cluster/user-data.sh dosyasına koyun:
#!/bin/bash
cat > index.html <<EOF
<h1>Hello, World</h1>
<p>DB address: ${db_address}</p>
<p>DB port: ${db_port}</p>
EOF
nohup busybox httpd -f -p ${server_port} &Bu Bash betiğinin orijinalinden birkaç değişikliği olduğunu unutmayın:
- Terraform standart enterpolasyon sözdizimini kullanarak değişkenleri arar, ancak erişebildiği tek değişkenler ikinci parametre aracılığıyla
templatefile'a ilettiğiniz değişkenlerdir (kısa bir süre sonra göreceğiniz gibi). Bu nedenle onlara erişmek için herhangi bir prefix gerekmez: örneğin,${var.server_port}değil,${server_port}kullanmalısınız. - Komut dosyası artık çıktıyı bir web tarayıcısında biraz daha okunabilir kılmak için bazı HTML sözdizimlerini (örneğin,
<h1>) içeriyor.
Son adım, aws_launch_configuration kaynağının user_data parametresini, templatefile metodunu çağıracak ve ihtiyaç duyduğu değişkenleri bir map olarak iletecek şekilde güncellemektir:
resource "aws_launch_configuration" "example" {
image_id = "ami-0fb653ca2d3203ac1"
instance_type = "t2.micro"
security_groups = [aws_security_group.instance.id]
# User Data komut dosyasını şablon olarak işler
user_data = templatefile("user-data.sh", {
server_port = var.server_port
db_address = data.terraform_remote_state.db.outputs.address
db_port = data.terraform_remote_state.db.outputs.port
})
# ASG launch configuration kullanırken gereklidir.
lifecycle {
create_before_destroy = true
}
}Evet, bu Bash komut dosyalarını satır içi yazmaktan çok daha temizdir!
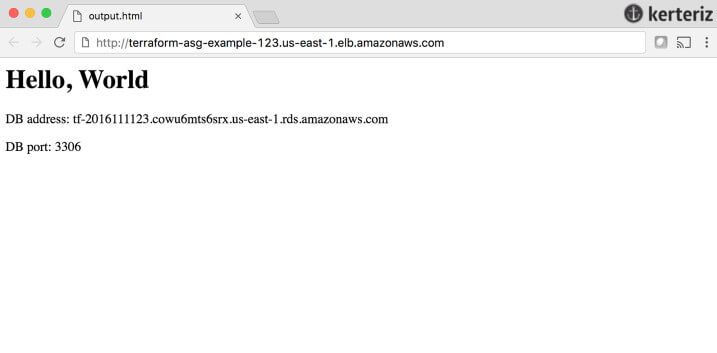
Bu clusterı terraform apply kullanarak dağıtırsanız, Instance'ların ALB'ye kaydolmasını bekleyin ve ALB URL'sini bir web tarayıcısında açın. Şekil 13'e benzer bir şey göreceksiniz.
Tebrikler, web sunucusu kümeniz artık Terraform aracılığıyla veritabanı adresine ve bağlantı noktasına programatik olarak erişebilir. Gerçek bir web framework (örneğin, Spring Boot) kullanıyorsanız, adresi ve portu ortam değişkenleri olarak ayarlayabilir veya bunları bir yapılandırma dosyasına yazabilir ve böylece veri tabanı kitaplığınız (örneğin ActiveRecord) tarafından veritabanı ile iletişim kurmak için kullanılabilir.