Python XML Okuma & Yazma İşlemleri (XML Parser)


Python XML işlemleri ile elinizde bulunan XML dosyaları üzerinde okuma, yazma ve dönüştürme işlemlerini rahatlıkla yapabilirsiniz. XML dosyası açma ve okuma işlemi başta olmak üzere birçok işlemi nasıl yapacağımızı örneklerle inceleyelim.
XML, EXtensible Markup Language yani Genişletilebilir İşaretleme Dili, hem insanlar hem bilgisayar sistemleri tarafından kolayca okunabilecek dokümanlar oluşturmaya yarayan bir işaretleme dilidir. İşin aslında XML dosyası bir metin dosyasıdır. Dilediğiniz etiketleri kullanarak dilediğiniz uzunlukta veri oluşturabilir ve rahatlıkla okuyabilirsiniz. Unutmayınız ki XML bir programlama dili değildir ve derlenmeye ihtiyacı yoktur. Örnek bir XML verisi görelim.
<?xml version="1.0" encoding="UTF-8"?>
<site>
<isim>Kerteriz Blog</isim>
<aciklama>Profesyoneller için içerikler</aciklama>
<adres>kerteriz.net</adres>
<yazar>İsmet BALAT</yazar>
</site>
Peki elimizdeki XML dosyalarını nasıl okur ve işleriz? XML dosyalarıyla çalışmanın birçok farklı yöntemi vardır. Bunlardan bilinen ve en popüler olanları DOM, SAX, lxml ve ElementTree kütüphaneleridir. Bu kadar çok seçenek varsa hangisi tercih etmeliyiz sorusunu sorduğunuzu duyuyorum. Bu soruyu bende çok sordum ve sonuç olarak şöyle bir özet yapabilirim:
DOM: Python standart kütüphanelerinden birisidir. Okuma işlemi için belirttiğiniz XML dosyasını tek seferde parse eder yani okur ve hafızaya yükleyerek ağaç oluşturur. Dosyayı tek seferde okuduğu için dosya boyutu kadar alanı kapatır. Bu nedenle küçük boyutlu XML dosyalarıyla çalışırken tercih edebilirsiniz ama büyük boyutlu XML dosyalarında memory problemi yaşamanız oldukça mümkün.
SAX: Python standart kütüphanelerinden birisidir. XML dosyasını parça parça okuyarak parse eder. Eğer büyük bir XML dosyasıyla çalışmak istiyorsanız DOM yerine SAX’ı tercih etmeniz mantıklı olacaktır.
ElementTree: Python standart kütüphanelerinden birisidir. Kullanımı oldukça kolaydır ve kullanım alanı yaygındır. XML dosyasını list yapısında, elemanları dict yapısında sunar. Özet bir tabirle daha Pythonic bir kullanım sunar. Tıpkı SAX gibi XML dosyasını parça parça okuyarak parse eden iterparse() methodu ve DOM gibi tek seferde yükleyen parse() yöntemi vardır. Ayrıca C ile yazılan cElementTree kütüphanesi de mevcuttur ve çok daha yüksek performans sunar. Özet olarak DOM veya SAX kullanmak yerine ElementTree kullanmayı tercih etmeniz faydalı olabilir.
lxml: Üçüncü parti bir kütüphanedir. Oldukça popülerdir ve sık kullanılmaktadır. ElementTree’nin sunduğu özelliklere ek olarak HTML parse edebilmesi, Xpath in tüm özellikleri ve XSLT, soupparser gibi birçok ekstra yeteneğe sahip olması da lxml’i daha tercih edilebilir hale getirmekte diyebiliriz. Tabi tüm bunların yanında en büyük avantajı hız konusu. Eğer işlemlerinizde hız önemliyse kesinlikle lxml’i kullanmalısınız. Çünkü en yakın rakibi ElementTree ile arasında bile oldukça yüksek farklar bulunmakta. İlgili performans testini ve değerleri görüntülemek için Tıklayınız.
Öyleyse hepsinin özeti olarak hangisini kullanmalıyım konusunda, eğer temel işlemler ihtiyaçlarınızı giderecekse direkt Python standart kütüphanelerinden olan ElementTree‘yi tercih edebilirsiniz. Fakat yaptığınız işte hız önemliyse üçüncü parti bir kütüphane olan lxml‘i indirerek kullanmaya başlayabilirsiniz. Biz bu dersimizde daha Pythonic ve standart bir kütüphane olması sebebiyle ElementTree kullanacağız.
1. cElementTree Kütüphanesini Dahil Etme
ElementTree kütüphanesi iki implementasyona sahiptir. Bunlardan birisi Python ile hazırlanan ElementTree, diğeri ise C ile hazırlanan cElementTree implementasyonlarıdır. cElementTree daha hızlı parse etme ve düşük bellek kullanımı için optimize edilmiştir. Tipik belgelerde cElementTree, ElementTree’nin Python sürümünden 15-20 kat daha hızlıdır ve 2-5 kat daha az bellek kullanır. Bu nedenle kesinlikle cElementTree kullanıyoruz. Tabi projenizde C kullanmanızı engelleyen hiçbir neden yoksa.
try:
import xml.etree.cElementTree as ET
except ImportError:
import xml.etree.ElementTree as ET
Kütüphanemizi projemize dahil ettik. Tabi her ihtimale karşı ElementTree yi de yedek olarak ekledik.
NOT: Dosya adınızı xml.py olarak isimlendirmeyiniz. Aksi takdirde modül hatası alacaksınızdır.
2. XML Dosyasını Okumak (XML Parse Etmek)
Kütüphanemizi ekledikten sonra XML dosyamızı seçerek okumalıyız. Bunun için eğer dosya boyutu küçükse parse() fonksiyonunu, eğer dosya büyükse iterparse() fonksiyonunu kullanabiliriz. Ardından getroot() fonksiyonu ile XML verimizi kökünden ele alabiliriz. Yeri gelmişken;
- tree (ağaç): Tüm XML içeriğimizi temsil eder. İç içe dallanmasına istinaden ağaç yapısına benzer.
- root (kök): XML içeriğimizin en üstünde yer alan ana etiket. Aşağıdaki örnekte
<kutuphane> - child (çocuk): root elemanının her bir alt elemanları. Aşağıdaki örnekte
<kitap> - subchild (alt çocuk): child elemanının her bir alt elemanları. Aşağıdaki örnekte
<ad>,<yazar>vs.
Örneğimizde kullanacağımız örnek XML dosyasını indirmek ve kendi çalışmanızda kullanmak için Tıklayınız.
mytree = ET.parse('kitaplar.xml')
myroot = mytree.getroot()
Burada XML dosyamızı seçtik ve ardından root elemanı değişkenimize atadık. Tabi aynı seçme işlemini bir XML dosyasından değilde elinizde XML yapısına uygun bir string değişkenden yapmak isterseniz de aşağıdaki kodu kullanabilirsiniz.
data = '''<?xml version="1.0" encoding="UTF-8"?>
<kutuphane>
<kitap id="1">
<ad>Şeker Portakalı</ad>
<yazar>Jose Mauro De Vasconcelos</yazar>
<fiyat>15,27 TL</fiyat>
<tarih>2019-09-06</tarih>
</kitap>
</kutuphane>
'''
myroot = ET.fromstring(data)
Root etiketinin ismini (kutuphane) yazdırmak isterseniz aşağıdaki kodu kullanabilirsiniz.
print(myroot.tag)
Root etiketinin özelliklerini de yazdırabilirsiniz. Bunun için attrib özelliğini kullanabiliriz. Bu komut bize bir sözlük (dict) verisi döndürecektir. Tabi bu örnekte root etiketinin hernagi bir özellik değeri bulunmadığı için boş sözlük çıktısını ({}) göreceğiz. Ayrıca sadece root değil tüm etiketlerin sahip olduğu özellikleri yine aynı attrib kullanımı ile seçebilirsiniz.
print(myroot.attrib)
XML içeriğimizde ki root etiketi altında yer alan tüm childleri ekrana yazdırmak için aşağıdaki örneği inceleyebilirsiniz.
for child in myroot:
print(child.tag)
Burada ekran çıktımız şu şekilde olacak çünkü root etiketimiz beş adet child etikete sahip ve hepsinin de adı ‘kitap‘.
kitap
kitap
kitap
kitap
kitap
Ayrıca iter() fonksiyonu ile spesifik bir etiket ismi belirterek bu isme sahip elemanlar üzerinde de gezinebiliriz.
for etiket in myroot.iter('ad'):
print(etiket.text)
Ekra çıktımız şu şekilde olacaktır:
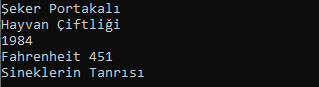
Bir XML in kaç adet child eleman içerdiğini len() fonksiyonu ile öğrenebiliriz.
print(len(myroot))
Ardından her bir etiketi tek tek seçebiliriz. Aşağıdaki seçme işleminde ilk child etiketi seçmiş bulunduk ve ekran çıktımız yine ‘kitap‘ olacaktır.
print(myroot[0].tag)
Artık child elemanların da içinde olan subchild elemanları seçmeye ve değerlerini ekrana basmaya geçebiliriz. Bunun için aşağıdaki örneği inceleyebilirsiniz.
for subchild in myroot[0]:
print("Etiket:",subchild.tag,"-","Değer:",subchild.text)
Ekran çıktımız şu şekilde olacaktır:

Tabi XML ağaç yapımızda arama da yapabiliriz. Bir veya birden fazla etiketi XML içinde arayarak bulmak için find() ve findall() fonksiyonlarını kullanabiliriz. findall() eşleşen tüm etiketleri seçerken find() sadece eşleşen ilk elemanı seçer.
for sonuc in myroot.findall("kitap"):
ad = sonuc.find('ad').text
yazar = sonuc.find('yazar').text
print("Kitap:",ad,"-","Yazar:",yazar)
Ekran çıktımız şu şekilde olacaktır:

3. XML Dosyasını Düzenlemek (Ekleme & Değiştirme & Silme)
Üst başlıkta XML dosyamızı seçtik ve parse ettik. Böylece tüm içeriğe rahatlıkla erişebildik ve dilediğimiz etiketi seçebildik. Şimdi ise yeni etiketler eklemeyi ve mevcut etiketlerde, değerlerde değişiklik yapmayı göreceğiz.
İlk örneğimiz olarak tüm kitapların fiyatlarına 10 TL zam yapalım.
for etiket in myroot.iter('fiyat'):
fiyat = etiket.text.split(" ")[0]
yenifiyat = float(fiyat)+10
yenifiyat = round(yenifiyat,2)
etiket.text = str(yenifiyat) + " TL"
Burada aldığımız fiyat değerlerine 10 ekledik ve tekrar aynı formata çevirerek etiketin değerine atadık. Bu andan itibaren ise 2 seçeneğimiz var. İsterseniz bu değişikleri sadece ekrana basabilir, isterseniz de yeni haliyle dosyaya kaydedebilirsiniz. Sadece ekrana basmak isterseniz yukarıda ki komutlardan sonra yine şunu kullanabilirsiniz:
for etiket in myroot.iter('fiyat'):
print(etiket.text)
Ekran çıktımız şu şekilde olacaktır:

Veya write() fonksiyonu ile ya yeni bir dosyaya ya da aynı dosyanın üzerine kaydedebilirsiniz.
mytree.write('kitaplar.xml')
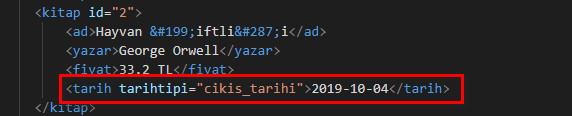
Düzenleme yaparken etiketlerinize özellikte ekleyebilirsiniz. Bunu yapabilmek için set() fonksiyonunu kullanabiliriz. Örnek olarak tarih isimli etiketlere bu tarihin çıkış tarihi olduğu özelliğini verelim.
for etiket in myroot.iter('tarih'):
etiket.set('tarihtipi','cikis_tarihi')
mytree.write('kitaplar.xml')
Ekleme işlemini yapıp dosyamızı kaydettikten sonra yeni XML dosyamızda ki tarih etiketlerine resimdeki gibi attributes eklenmiş olacak.
Geldik belki de en merak ettiğiniz noktaya 🙂 XML dosyamıza yeni bir etiket eklemek için yine iki farklı örnek kullanacağım. İlk örneğimizde sadece ilk child elemanımıza stok isimli subchild elemanını ekleyeceğim.
ET.SubElement(myroot[0], 'stok')
for x in myroot.iter('stok'):
x.text = "100"
mytree.write("kitaplar.xml")
Ekran çıktımız ve yeni XML içeriğimiz şu şekilde olacaktır.
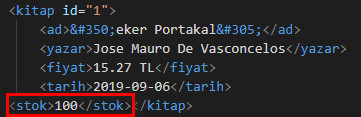
Şimdi ki örnekte ise tüm kitap etiketlerine stok subchild elemanını ekleyeceğim.
for x in myroot.iter('kitap'):
stok = ET.SubElement(x, 'stok')
stok.text = "100"
mytree.write("kitaplar.xml")
Ardından XML dosyanıza baktığınızda tüm child elemanlarına stok subchild elemanın eklendiğini göreceksiniz.
Artık son işlevimiz olan XML içeriğinizde bir eleman silme ve istediğiniz bir elamandan özellik silme işlemlerine geldik. İlk olarak daha yeni eklediğimiz tarih etiketindeki tarihtipi isimli attribute değerini silelim. Tabi bunu örnek olması için sadece ilk elemanda yapalım.
myroot[0][3].attrib.pop('tarihtipi', None)
mytree.write("kitaplar.xml")
Attribute kaldırma işlemini tüm tarih elemanları için yapmak istiyorsanız iter() fonksiyonunu yukarıda yaptığım örneklerde ki gibi kullanabilirsiniz. Şimdi ikinci kitap isimli child elamanındaki yazar isimli subchild elemanını kaldıralım.
myroot[0].remove(myroot[0][1])
mytree.write('kitaplar.xml')
XML içeriğimize bakarsak ilk child içindeki yazar subchildinin silindiğini görebiliriz.

Unutmadan bir etiket içindeki tüm elemanları silme işlemini nasıl yapacağınızı da gösterelim.
myroot[1].clear()
4. Sonuç
Python ile XML dosyalarınız üzerinde yapabileceğiniz parse etme (okuma), ekleme, düzenleme ve silme işlemlerinin tamamını örneklerle detaylı bir şekilde açıkladık. Ayrıca en başta hangi kütüphaneleri kullanabileceğimizi karşılaştırarak anlattık. Burada yazımızı bitiriyoruz ama aklınıza takılan ve sormak istediğiniz soruları aşağıdaki yorum alanından yazabilirsiniz. Son olarak ilgililer için Python ile JSON işlemleri yazımıza da göz atmanızını tavsiye ederim.



